傳統(tǒng)的綜合技術(shù)越來越不能滿足當(dāng)今采用 90 納米及以下工藝節(jié)點實現(xiàn)的非常大且復(fù)雜的 FPGA 設(shè)計的需求了。問題是傳統(tǒng)的 FPGA 綜合引擎是基于源自 ASIC 的方法,如底層規(guī)劃、區(qū)域內(nèi)優(yōu)化 (IPO,In-place Optimization) 以及具有物理意識的綜合 (physically-aware synthesis) 等。然而,這些從 ASIC 得來的綜合算法并不適用于 FPGA 的常規(guī)架構(gòu)和預(yù)定義的布線資源。
最終的結(jié)果是,所有的三種傳統(tǒng) FPGA 綜合方法需要在前端綜合與下游的布局布線工具之間進(jìn)行多次耗時的設(shè)計反復(fù),以獲得時序收斂。這個問題的解決方案是一種基于圖形的獨特物理綜合技術(shù),能夠提供一次通過、按鈕操作的綜合步驟,不需要 ( 或者需要很少 ) 與下游的布局布線引擎的設(shè)計反復(fù)。而且,基于圖形的物理綜合在總體的時鐘速度方面可以將性能提高 5% 到 20% 。 Synplify Premier 先進(jìn) FPGA 物理綜合工具就是這樣一種工具,專門針對那些設(shè)計很復(fù)雜的高端 FPGA 設(shè)計工程師而定制,他們的設(shè)計需要真正的物理綜合解決方案。
本文首先介紹了主要的傳統(tǒng)綜合方法,并說明這些方法存在的相關(guān)問題,然后介紹基于圖形的物理綜合概念,并指出這種技術(shù)如何滿足當(dāng)前先進(jìn) FPGA 的設(shè)計需求。
傳統(tǒng)綜合解決方案存在的問題
對于 2 微米的 ASIC 技術(shù)節(jié)點以及上世紀(jì) 80 年代早期以前來說,電路單元 ( 邏輯門 ) 相關(guān)的延時與互連 ( 連接線 ) 相關(guān)延時的比例約 80:20 ,也就是說門延時約占每個延時路徑的 80% 。這樣一來,設(shè)計師可以用連線負(fù)載模型來估計互連延時,在連線負(fù)載模型中,每個邏輯門輸入被賦予某個 “ 單位負(fù)載 ” 值,與某個特定路徑相關(guān)的延時可以作為驅(qū)動門電路的強(qiáng)度和連接線上的總電容性負(fù)載的函數(shù)來計算得出。
類似地,當(dāng)在上世紀(jì) 80 年代后期 ( 大約引入 1 微米技術(shù)節(jié)點的時候 ) 第一個 RTL 綜合工具開始用在 ASIC 設(shè)計中的時候,電路單元的延時與連線延時相比還是占主導(dǎo)地位,比例約為 66:34 。因此,早期的綜合工具還是基于它們的延時估計方法,并使用簡單的連線負(fù)載模型進(jìn)行優(yōu)化。由于電路單元的延時占據(jù)主導(dǎo),因此初期綜合引擎使用的基于連線負(fù)載的時序估計足夠準(zhǔn)確,下游的布局布線引擎通常能在相對較少的幾次反復(fù) ( 在 RTL 和綜合階段之間 ) 條件下實現(xiàn)設(shè)計。
然而,隨著每個后續(xù)技術(shù)節(jié)點的引入,互連延時大大地增加 ( 事實上,就 2005 年采用 90 納米技術(shù)實現(xiàn)的標(biāo)準(zhǔn)單元 ASIC 來說,電路單元與互連的延時比例現(xiàn)在已經(jīng)接近 20:80) 。這使得綜合引擎的延時估計與布局布線后實際延時的關(guān)聯(lián)性越來越低。
這具有一些很重要的牽連性,因為綜合引擎在不同的優(yōu)化方法之間選擇,以及在實現(xiàn)功能的替代方法 ( 諸如基于它們的時序預(yù)測的加法器 ) 之間選擇。例如,假設(shè)某個包含一個加法器 ( 以及其它組件 ) 的特定時序路徑被預(yù)知具有一些 ( 時序 ) 裕量,這種情況下,綜合工具可以選擇一個占用芯片面積相對較小的較慢加法器版本。但是,如果時序估計與實際的布局布線后延遲情況出入比較大的話,這個路徑可能最后非常慢。這樣一來,不準(zhǔn)確的延時估計意味著綜合引擎最后才對不正確的對象進(jìn)行優(yōu)化,只有在完成了布局布線后你才發(fā)現(xiàn)問題并不是像你 ( 或綜合引擎 ) 所想的那樣,其結(jié)果是獲得時序收斂所需的工作量將大大地增加,因為從前端到后端的設(shè)計反復(fù)次數(shù)大大增加了。
為了解決這些問題,有必要了解在綜合過程中與設(shè)計相關(guān)的物理特性。因此,隨著時間的推移, ASIC 綜合技術(shù) ( 緊跟著 FPGA 綜合技術(shù) ) 采用了一系列的方法 ( 某些情況下也拋棄了一些方法 ) ,例如下面討論的底層規(guī)劃、 IPO 和具有物理意識的綜合。
底層規(guī)劃
對于 ASIC 的 RTL 綜合,底層規(guī)劃技術(shù)在上世紀(jì) 90 年代早期出現(xiàn),稍晚于綜合技術(shù)本身的問世。底層規(guī)劃工具允許設(shè)計師在器件上定義物理區(qū)域,通過手工或者使用自動交互技術(shù)來對這些區(qū)域布局,并將設(shè)計的不同部分分配到這些區(qū)域。
底層規(guī)劃涉及到逐個模塊地綜合和優(yōu)化設(shè)計,然后在最后將所有東西 “ 縫合 ” 在一起 ( 早期底層規(guī)劃工具使用的綜合算法都是基于連接線負(fù)載模型 ) 。這意味著底層規(guī)劃工具不能按每個單元優(yōu)化邏輯,只能影響邏輯模塊的布局。而且,在定義上,底層規(guī)劃工具不會全局性地考慮布線資源,在設(shè)計完全布線完成之前,它不可能準(zhǔn)確分析所有的時序路徑。這會導(dǎo)致在前端和后端工具之間的大量耗時的設(shè)計反復(fù)。盡管這種方法可以提高 ASIC 設(shè)計的時序性能和降低功耗,但它需要對設(shè)計的復(fù)雜分析和很高的專業(yè)技術(shù)水準(zhǔn)。
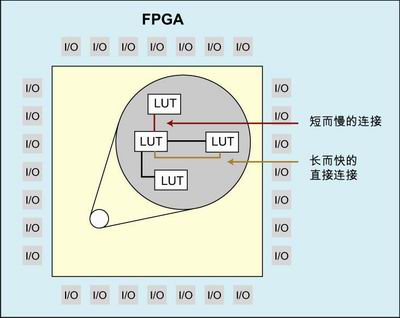
圖 1 : FPGA 的主流架構(gòu)。
在早期,采用 ASIC 底層規(guī)劃有下面幾個原因:作為一種獲得時許收斂的方法解決有限容量的問題,并支持基于逐個模塊的遞增變化。最近,底層規(guī)劃不再被認(rèn)為是一種其本身能獲得時序收斂的方法;底層規(guī)劃依然是一種有用的方法,但只是在與其它方法 ( 例如物理優(yōu)化 ) 結(jié)合的時候才有用,使用綜合后門級網(wǎng)表的底層規(guī)劃依然需要非常多的專門技術(shù)。
對于 FPGA 來說,直到上世紀(jì) 90 年代晚期,底層規(guī)劃技術(shù)還沒有成為主流應(yīng)用。平均而言,在一個 FPGA 設(shè)計中,關(guān)鍵路徑一般會經(jīng)過 3 個區(qū)域。由于 FPGA 一般用到的設(shè)計方法,如果使用綜合后 (“ 門級 ”) 網(wǎng)表來執(zhí)行底層規(guī)劃,即使對 RTL 的相對較小的改變都可能導(dǎo)致先前所做的底層規(guī)劃工作付之東流。解決這個問題的方法是在 RTL 級進(jìn)行底層規(guī)劃。然而,為了更有用,這必須和某種形式的物理優(yōu)化相結(jié)合,源于 ASIC 的物理綜合算法并不適合于 FPGA 的常規(guī)架構(gòu)以及預(yù)定義的布線資源。
布局優(yōu)化
隨著底層規(guī)劃在 ASIC 領(lǐng)域的作用逐漸弱化,在上世紀(jì) 90 年代中期, IPO 技術(shù)對其進(jìn)行了強(qiáng)化 / 或者替代。這再次地涉及到時序分析和估計是基于連接線負(fù)載模型的綜合。
在這種情況下,所產(chǎn)生的網(wǎng)表被傳遞到下游的布局布線引擎。在布局布線和寄生提取之后,實際的延時被背注到綜合引擎。這些新值觸發(fā)器在綜合引擎中的遞增優(yōu)化,例如邏輯重構(gòu)和復(fù)制。其結(jié)果是得到一個被部分修改的新網(wǎng)表。然后,這個網(wǎng)表被遞交到遞增布局布線引擎,產(chǎn)生一個改進(jìn)的設(shè)計拓?fù)洹?br />
基于 IPO 流程所得到的最后結(jié)果比那些采用底層規(guī)劃方法獲得的通常更好。然而,這種方法同樣可能需要在前端和后端工具之間進(jìn)行很多次設(shè)計反復(fù)。而且基于 IPO 方法的一個重要的問題是對布局布線的修改可能導(dǎo)致新的關(guān)鍵路徑,這個路徑在前一次反復(fù)中是看不到的,即修正一個問題可能會激起其它的問題,這可能導(dǎo)致收斂的問題。
對于 FPGA 設(shè)計,基于 IPO 的設(shè)計流程大約在 2003 年開始受到主流關(guān)注。然而,盡管這樣的流程已經(jīng)可用,但那時這些流程并沒有以一種有意義的方式得到采用,因為單個地優(yōu)化時序路徑的 IPO 技術(shù)通常導(dǎo)致其它路徑時序的劣化和時序收斂不完全。設(shè)計師需要可使他們在不犧牲之前設(shè)計版本獲得的成果的基礎(chǔ)上對設(shè)計進(jìn)行改變的可靠結(jié)果。但是基于 IPO 的方法并不能在多次設(shè)計反復(fù)之上產(chǎn)生穩(wěn)定的結(jié)果,因為在一次反復(fù)中優(yōu)化關(guān)鍵路徑會在下一次反復(fù)中產(chǎn)生新的關(guān)鍵路徑。類似地,增加約束以改進(jìn)一個區(qū)域的時序可能使其它的區(qū)域的時序惡化。
具有物理意識的綜合
當(dāng)前先進(jìn)的 ASIC 綜合技術(shù)是具有物理意識的綜合,這種綜合技術(shù)在大約 2000 年開始受到主流關(guān)注。不考慮實際的技術(shù) ( 有幾種不同的算法 ) ,具有物理意識的綜合的基本概念是在一次性完成的過程中結(jié)合布局和綜合。
這在 ASIC 領(lǐng)域中的實踐效果很好,因為了解布局的綜合引擎能根據(jù)已布局的單元的周邊和 Steiner 以及 Manhattan 布線估計進(jìn)行時序的預(yù)估。這種綜合方法在 ASIC 中效果很好的原因是連接線有序地布置。這意味著與最后的布局和布線設(shè)計相關(guān)的延時與綜合引擎所估計的結(jié)果具有非常好的相關(guān)性。
從 2002 年到 2003 年期間開始,很多的 EDA 供應(yīng)商開始考慮將從 ASIC 中得到的具有物理意識的綜合技術(shù)應(yīng)用到 FPGA 設(shè)計中,但是他們并沒有進(jìn)一步將這種思路深入下去,而 Synplicity 公司新的基于圖形的綜合方法是一個例外,現(xiàn)在沒有供應(yīng)商能提供具有布局意識的 RTL 綜合工具用于 FPGA 設(shè)計。問題是,與 ASIC 中的連線 “ 按序構(gòu)建 ” 不同的是, FPGA 具有固定數(shù)量的預(yù)先確定的布線資源,并不是所有的布線都設(shè)置成一樣 ( 某些連線短且快,某些長而快,某些短而慢,某些長而慢 ) 。
對于實際的情況而言,基于 ASIC 的具有物理意識的綜合可以根據(jù)形成設(shè)計的已布局單元的附近來進(jìn)行布線和時序估計。而對于 FPGA 來說,將兩個邏輯功能放在相鄰的區(qū)域并不一定能實現(xiàn)它們之間的快速連接。 - 取決于可用的布線資源,將相連接的邏輯功能布局位置更遠(yuǎn)可能反而能獲得更好的布線和時序結(jié)果,盡管這有一點違背常理。這就是為什么從 ASIC 設(shè)計中得來的具有物理意識的綜合技術(shù)用于 FPGA 架構(gòu)時并不能得到最佳結(jié)果的原因。同樣,使用這些技術(shù)的設(shè)計流程需要大量耗時的前端 ( 綜合 ) 與后端 ( 布局與布線 ) 引擎之間的設(shè)計反復(fù),以獲得相關(guān)性和時序收斂。
與 FPGA 架構(gòu)相關(guān)的一些考量
在詳細(xì)介紹基于圖形的物理綜合概念之前,先了解設(shè)計任務(wù)的復(fù)雜性很重要。正如前面談到的, FPGA 具有固定的連接資源,所有連線已經(jīng)構(gòu)建好,但并不是所有的路徑都是一樣的 ( 有短的、中等的和長的連線,而每個連線都可能具有快、中等或者慢的特性 ) 。
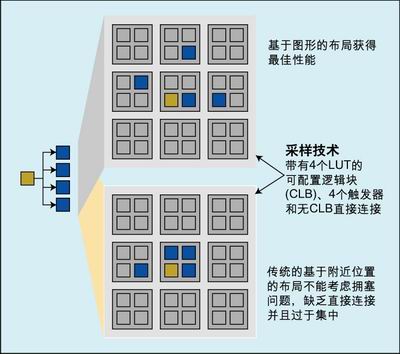
圖 2 :比較傳統(tǒng)和基于圖形的布局。
每個路徑都可能具有多個 “ 抽頭點 ”( 就像高速路的出口道 ) 。這里的問題是,你可能具有一個能迅速地將一個信號從源點函數(shù) ( 高速路的最初的入口道 ) 快速地傳遞到一個目的函數(shù) ( 高速路的最后出口道 ) 的快速路徑。然而,如果我們對一個內(nèi)部抽頭點增加第二個目的函數(shù),這可能大大地減慢信號速度。
而且,當(dāng)今 FPGA 的主流架構(gòu)基于一個查找表 (LUT) 具有幾個輸入和單個輸出的概念。一些 FPGA 架構(gòu)具有通過與查找表相關(guān)的每個輸入輸出路徑的不同延時。然而,更重要的事實是,到 LUT 的每個輸入可能只能使用一部分的不同連線類型。如果來自一個 LUT 的輸出驅(qū)動另外一個 LUT ,它們之間可能同時存在慢速和快速的路徑,這取決于我們在接收 LUT 上所使用的特定輸入 。
總的情形被 FPGA 架構(gòu)的分層特性進(jìn)一步復(fù)雜化。例如,一個小的邏輯模塊可能有幾個 LUT ;在一個較大的邏輯模塊中有幾個這樣的小模塊;在整個的 FPGA 中具有大量的這種大邏輯模塊。在這些大邏輯模塊中的某個邏輯塊中,一個 LUT 的輸出與另外一個 LUT 的輸入直接相連接的概率很小;為了實現(xiàn)額外的連接,可能必須繞道邏輯模塊的外部,然后再繞回到模塊內(nèi)部來實現(xiàn)。這一點再次地說明所處理問題的復(fù)雜性:如果你知道將它們放置在什么地方以及使用哪個引腳,將兩個對象 / 實例放在不同的邏輯模塊將獲得比放在采用非最佳互連資源的同一模塊中會得到更短的延時。
另外,任何被提出的綜合方案必須解決圍繞固定的硬宏資源,例如 RAM 、乘法器等相關(guān)的連線延時。同樣的,方案必須解決增加的布線擁塞,這種擁塞常出現(xiàn)在靠近這些硬宏的地方。所有這些硬宏都屬于特定器件具有的,因此任何被提出的方案必須能用于每個 FPGA 系列的每個器件。
基于圖形的獨特物理綜合方案
能真正處理 FPGA 架構(gòu)相關(guān)復(fù)雜性的具有物理意識的綜合解決方案將以完全不同的觀點來處理上述問題。這種方法將對 FPGA 中所有連線的特點進(jìn)行描述,包括入口點、端點和內(nèi)部出口點,然后對所有這些連線構(gòu)建一個 “ 地圖 ” 。對于軟件行業(yè)來說,這種地圖被稱為圖形 (Graph) ;這就是為什么這種方法稱為 “ 基于圖形的物理綜合 ” 的原因。
除了連線本身,這個圖形還包括這些細(xì)節(jié):哪個 LUT 引腳連接到哪類的連線;通過每個 LUT 的輸入到輸出的延時差異;以及器件中的任何硬宏的大小和位置。打個比方,這類似于通過查地圖來顯示你將驅(qū)車經(jīng)過的街道、高速路以及像停車場 ( 硬宏 ) 這樣的地方。當(dāng)希望穿行于城市中的兩個地方時,你將使用地圖來選擇最快的路徑,這個路徑通常并不是最短的點到點路徑。
類似地,基于圖形的物理綜合引擎不是尋找最近的路徑,而是使用一種以互連為中心的方法專注于速度。從最關(guān)鍵的路徑開始處理,然后逐步到次關(guān)鍵路徑 ( 這樣確保最關(guān)健的路徑獲得最快的路線 ) ,基于圖形的物理綜合引擎將選擇連線和它們相關(guān)的入口點和出口點;從這些連線得到電路布局;從這些連線和布局得到準(zhǔn)確的延時;最后按照要求進(jìn)行優(yōu)化和設(shè)計反復(fù)。
關(guān)鍵點是,所有的優(yōu)化和反復(fù)在流程的前端部分 ( 綜合 ) 執(zhí)行。基于圖形的物理綜合的輸出是一種完整布局的網(wǎng)表 ( 包括將與每個連線相關(guān)聯(lián)的特定 LUT 引腳 ) ,這種網(wǎng)表可以交給 FPGA 的后端布局布線引擎。
最終得到一種一次通過的、按鍵操作的綜合步驟,下游布局布線引擎不需要 ( 或者需要很少的 ) 設(shè)計反復(fù)。而且,根據(jù)對超過 200 個實際的設(shè)計進(jìn)行分析顯示,就系統(tǒng)的總體時鐘速度而言,基于圖形的物理綜合可以獲得 5% 到 20% 的性能提升。
本文小結(jié)
以 ASIC 為中心的具有物理意識的綜合中,連線從布局選擇中衍生出來,與此不同的是,在 FPGA 設(shè)計中使用基于圖形的物理綜合時,布局源自于連接線選擇。
對于時序收斂問題,基于已有的 ( 源于 ASIC) 物理綜合引擎可能需要在流程的前端 ( 綜合 ) 與后端 ( 布局布線 ) 之間進(jìn)行很多次耗時的設(shè)計反復(fù)。在所有這些反復(fù)之后,它們可能依然不能收斂。相比較而言,對于 200 多個采用基于圖形的物理綜合的設(shè)計進(jìn)行分析之后顯示, 90% 的設(shè)計處于最后實際時序的 10% 之內(nèi), 80% 的設(shè)計在實際時序值的 5% 以內(nèi),而采用邏輯綜合的設(shè)計只有 30% 在實際時序值的 5% 以內(nèi),很多設(shè)計的誤差很容易地達(dá)到 30% ,甚至更高 ) 。而且,基于圖形的物理綜合能提高 5% 到 20% 的總體時鐘速度性能。
此外,基于圖形的物理綜合的已布局網(wǎng)表的質(zhì)量大大地提高,這意味著時序驅(qū)動的布線工具的工作量很少,優(yōu)化了執(zhí)行,這樣運行將非常快。
Synplicity 公司的突破是基于以布線為中心方法的概念,以及以圖形來表示所有的東西,然后處理該圖形。在經(jīng)歷了大量的研究和開發(fā)之后, Synplicity 的綜合專家已經(jīng)創(chuàng)建了一種真正基于圖形的物理綜合解決方案。第一個具有基于圖表物理綜合特性的產(chǎn)品是 Synplify Premier ,這是一種先進(jìn)的 FPGA 物理綜合工具,專門針對那些設(shè)計復(fù)雜、要求采用真正的物理綜合解決方案的高端 FPGA 設(shè)計。 Synplify Premier 工具還包括高級的功能,例如 RTL 原級調(diào)試以及支持 ASIC 原型設(shè)計工具 Synopsys DesignWare 。
