
摘 要: 介紹了一種采用并行方式構(gòu)建的多" title="的多">的多符號可變長碼解碼器。該解碼器通過增加結(jié)構(gòu)的復(fù)雜性和對硬件資源的占用,換取可變長碼解碼的高吞吐量。這種結(jié)構(gòu)突破了可變長碼碼字之間的前向依賴性,可并行偵測出Buffer中的所有可能的碼字。采用FPGA實(shí)現(xiàn)了這種結(jié)構(gòu)。
關(guān)鍵詞: 可變長解碼 現(xiàn)場可編程邏輯門陣列 硬件描述語言
可變長編碼" title="變長編碼">變長編碼(VLC)是一種無損熵編碼,它廣泛應(yīng)用于多媒體信息處理等諸多領(lǐng)域。在H.261/263、MPEG1/2/3等國際標(biāo)準(zhǔn)中,VLC占有重要地位。VLC的基本思想是對一組出現(xiàn)概率各不相同的信源符號,采用不同長度的碼字表示,對出現(xiàn)概率高的信源符號采用短碼字,對出現(xiàn)概率低的信源符號采用長碼字。Huffman編碼是一種典型的VLC,其編碼碼字的平均碼長非常接近于數(shù)據(jù)壓縮的理論極限——熵。
可變長解碼(VLD)是VLC的逆過程,它從一組連續(xù)的碼流中提取出可變長碼字,并將之轉(zhuǎn)換為對應(yīng)的信源符號。由于在VLC過程中,碼字之間通常不會加入任何分隔標(biāo)識,這就造成了在解碼過程中識別碼字的困難。因此,在VLD過程中,變長碼字必須逐一識別,只有碼流中居前的碼字被識別之后,才能定位后序碼字的起始位置,這一點(diǎn)在很大程度上限制了VLD運(yùn)行的效率。
本文討論一種新型的VLD解碼結(jié)構(gòu),它通過并行偵測多路" title="多路">多路碼字,將Buffer中的多個可變長碼一次讀出,這將極大地提高VLD的吞吐量和執(zhí)行效率。然后采用FPGA對這種并行VLD算法的結(jié)構(gòu)進(jìn)行驗(yàn)證,最終得出相應(yīng)結(jié)論。
1 算法描述
由于碼流中的可變長碼之間具有前向依賴性,因此如何確定可變長碼碼字在連續(xù)碼流中的起始位置是VLD的關(guān)鍵所在。傳統(tǒng)的VLD解碼方案主要分為位串行解碼方案和位并行解碼方案兩種。
在位串行解碼方案中,碼流逐位送入解碼器,解碼器通過逐位匹配實(shí)現(xiàn)可變長碼的解碼。這種過程實(shí)質(zhì)上是一種建造Huffman樹的反過程,從根節(jié)點(diǎn)出發(fā),直至葉子節(jié)點(diǎn)為止。由于這種方式采用逐位操作方式,而可變長碼的碼長又各不相同,使得碼字識別所需的運(yùn)行周期也不相同。在解碼長較短的碼字時,其解碼速度較快,而在解碼長較長的碼字時,其解碼速度較慢。顯然,位串行解碼方案效率相對較低,解碼速度因碼字長度不同而不同,無法滿足某些對實(shí)時性要求較高的應(yīng)用場合。
針對位串行解碼方案的不足,多種位并行解碼方案被提出。位并行解碼方案采用并行方式工作,通過對可變長碼的碼字進(jìn)行排序(Ordering)、分割(Partitioning)和簇化(Clustering),采用基于邏輯塊的匹配模式或基于樹的匹配模式來實(shí)現(xiàn)[1~3]。并行解碼方案大大提高了可變長碼的解碼效率,而且可以確保每個運(yùn)行周期輸出一個解碼碼字,實(shí)現(xiàn)穩(wěn)定的解碼輸出。在高級的位并行解碼方案中,還可以將解碼過程分解為若干階段,引入流水線操作,進(jìn)一步提高解碼效率[4]。
在傳統(tǒng)的VLD解碼方案的基礎(chǔ)之上,采用并行操作方式,增加硬件資源和相應(yīng)的控制邏輯,可實(shí)現(xiàn)一個運(yùn)行周期輸出多個解碼碼字,使可變長碼的解碼效率進(jìn)一步得到提高。
由于可變長碼長度不同,在解碼過程中碼字存在前向依賴性。如果采用多路并行操作方式,在所有可能成為可變長碼碼字的起始位置同時進(jìn)行預(yù)測,然后通過后續(xù)控制篩選出合法的碼字,就可以對多個可變長碼實(shí)現(xiàn)同時解碼。這就是多符號可變長并行解碼方案的基本思想。
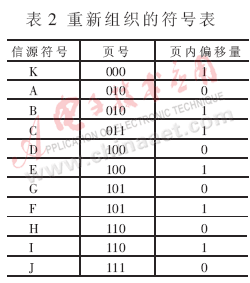
具體說明如下:假設(shè)某個信源符號集有K個符號,K個符號所對應(yīng)的變長碼字用![]() {0,1},k=0,…,K-1表示,這些變長碼的長度為集合L,其中最長的碼長用ln表示,最短的碼長用l1表示;具有相同碼長的碼字最多為dmax個。現(xiàn)采用分頁方式重新組織這些可變長碼,將具有相同碼長的碼字存入一個頁內(nèi),那么易知一個頁內(nèi)最多可能擁有dmax個碼字。為了識別一個頁內(nèi)的不同碼字,還需要引入頁內(nèi)偏移量,然后采用線性結(jié)構(gòu)將這些頁面重新組合。
{0,1},k=0,…,K-1表示,這些變長碼的長度為集合L,其中最長的碼長用ln表示,最短的碼長用l1表示;具有相同碼長的碼字最多為dmax個。現(xiàn)采用分頁方式重新組織這些可變長碼,將具有相同碼長的碼字存入一個頁內(nèi),那么易知一個頁內(nèi)最多可能擁有dmax個碼字。為了識別一個頁內(nèi)的不同碼字,還需要引入頁內(nèi)偏移量,然后采用線性結(jié)構(gòu)將這些頁面重新組合。
下面給出一個依據(jù)該思想重新組織信源符號的實(shí)例:
假設(shè)可變長碼碼表如表1所示。用變長碼的長度表示頁號,用變長碼的最右一位表示頁內(nèi)偏移量,重新組織符號表,如表2所示。這樣,在解可變長碼時,可以將焦點(diǎn)主要集中在獲取可變長碼長度和頁內(nèi)偏移量的問題上來,然后再將其轉(zhuǎn)換成對應(yīng)的信源符號。

?
對于存儲在Buffer中的等待解碼的數(shù)據(jù)碼流X,用滑動窗口從中截取前N位,這里的N應(yīng)當(dāng)大于或等于可變長碼中最長碼字的碼長,即N≥ln。由于可變長碼最短的碼長為l1,因此在這N位碼流中,最多可包含M=[N/l1]個可變長碼。為了表示方便,這里用Wi(i=0,1,…,M-1)表示這M個可變長碼。
顯然,對于W0,其起始位置必然為0;如果W0的碼長為L0,那么W1的起始位置則為L0;如果W1的碼長為L1,那么W2的起始位置為L0+L1,依此類推。由于在解碼開始時,L0的取值無法明確,其可能取值范圍是l1≤L0≤Ln,因此每個Wi的可能起始位置分別由一組值組成。
為了實(shí)現(xiàn)并行解碼,采用多個可變長碼檢測單元從所有可能的起始位置同時偵測,一旦W0的碼長L0被偵測出,就可以從所有已解碼的可能的變長碼中找出W1,并確定W1的碼長L1,由此W2的起始位置也就得以確定。依此類推,最多可逐次將Wi(i=0,1,…,M-1)個變長碼解出。
每個Wi的解碼過程只比Wi-1的解碼過程多一個加法操作的延遲,相對于變長碼的識別,加法操作的延遲非常的小。當(dāng)然,如果滑動窗口N的取值過大,每個Wi之間的加法操作的延遲將累加,這將降低解碼的整體效率。因此對于滑動窗口N的選擇,需要結(jié)合實(shí)際應(yīng)用中可變長碼編碼的特點(diǎn)來權(quán)衡。
設(shè)某個待解碼流為B={110110100011000011001111, ...}。這里采用長度N=12的滑動窗口進(jìn)行碼流提取,由于變長碼的長度從2~8不等,因此每個運(yùn)行周期至少可以解碼出1個碼字,最多可解碼出6個碼字,這6個變長碼字可能的起始位置分別為W0:{0};W1:{2,3,4,5,6,7,8};W2:{4,5,6,7,8,9,10};W3:{6,7,8,9,10};W4:{8,9,10};W5:{10}。
綜合起來,可能成為該可變長碼起始位置的集合為{0,2,3,4,5,6,7,8,9,10},因此在應(yīng)用上共需要10個可變長碼檢測單元并行執(zhí)行。
2 實(shí)現(xiàn)與驗(yàn)證
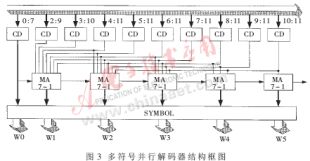
多碼字并行解碼方法實(shí)現(xiàn)的關(guān)鍵在于解碼過程的并行性,采用硬件方案實(shí)現(xiàn)起來并不難。上例中10個可變長碼檢測單元可采用經(jīng)典的位并行解碼方案實(shí)現(xiàn),因?yàn)槲徊⑿薪獯a方案能夠保證不同長度碼字的輸出時間基本相同,為其后的操作帶來便利。在本文中,采用基于查找表" title="查找表">查找表的方式來實(shí)現(xiàn)。
碼字檢測單元所檢測到的可變長碼的碼長及頁內(nèi)偏移量(這里采用碼字的最右位作為頁內(nèi)偏移量),在識別過程中可能存在沒有任何有效碼字的情況。為此,增加了一位有效狀態(tài)位,作為輸出是否有效的標(biāo)志。變長碼檢測單元CD的結(jié)構(gòu)框圖如圖1所示。
由于前一個有效碼字Wi-1的碼長控制著碼字Wi的選取,而對應(yīng)Wi-1的檢測單元CDi-1輸出了Wi-1的碼長,因此在實(shí)現(xiàn)上可以采用將CDi-1的輸出作為有效碼字Wi選取的控制位,它通過控制一個多路選擇器MUX,從所有對應(yīng)可能是Wi起始位置的CD輸出中選取有效的輸出作為有效碼字Wi。在有效碼字Wi被成功識別后,需要將其碼長即CDi的輸出與CDi-1的輸出相加,作為有效碼字選擇的控制。這些功能通過一個復(fù)合的多路復(fù)用器" title="多路復(fù)用器">多路復(fù)用器-加法器MA實(shí)現(xiàn),多路復(fù)用器-加法器MA的結(jié)構(gòu)如圖2所示。

在所有有效碼字的起始位置被識別后,根據(jù)對應(yīng)CD單元的輸出,即碼長信息和頁內(nèi)偏移量,可以通過查表將對應(yīng)的碼長數(shù)據(jù)轉(zhuǎn)換成相應(yīng)的信源符號或存儲相應(yīng)信源符號的地址。這些功能由信號轉(zhuǎn)換單元SYMBOL完成。
根據(jù)上面的討論,設(shè)計出用于上例的多符號并行解碼器,其結(jié)構(gòu)圖如圖3所示。
為了驗(yàn)證這種這種結(jié)構(gòu),采用FPGA器件實(shí)現(xiàn)它,選擇的是一片Xilinx xc2s400e-6ft256器件,其規(guī)模為145000門。在這里,采用VHDL語言進(jìn)行RTL級描述,利用XST進(jìn)行綜合,并在ModelSim5.8中進(jìn)行仿真。結(jié)果驗(yàn)證正確,其仿真結(jié)果如圖4所示。

實(shí)驗(yàn)表明,系統(tǒng)允許最大時鐘頻率為44.172MHz,占用了197個Slice(4%),74個Slice Flip Flops(<1%),347個四輸入查找表(12%)和1個全局時鐘(25%)。
參考文獻(xiàn)
1 Hashemian R. Design and Hardware Implementation of a Memory Efficient Huffman Decoding. IEEE Consumer Elec., 1994;40(3):345~352
2 S M Lei and M T Sun.An Entropy Coding System for Digital HDTV Applications. IEEE Trans. Circuits Syst.Video Technol., 1991;(3):147~155
3 S B Choi and M H Lee.High speed pattern matching for a fast Huffman decoder. IEEE Trans. Consurmer Electron,1995; 41(2):97~103
4 M K Rudberd and L Wanhammar. New Approaches to High Speed Huffman Decoding. IEEE Int.Symp. Circuits Syst., 1996;2(5):149~152
5 Nikara, Vassiliadis, Takala, Sima, Liuha. Parallel Multiple-Symbol Variable-Length Decoding.Computer Design: VLSI in Computers and Processors, 2002:126~131
6 黎 文,李蜀雄,朱維樂.采用多級查找表的定/變長解碼引擎. 信號處理,2002;6(12)
7 Spartan-IIE Data Sheet. Xilinx, 2003