 盡管H.264/AVC承諾將此已有視頻編碼標(biāo)準(zhǔn)具有更高的編碼效率,,它仍為系統(tǒng)架構(gòu)師,、DSP 工程師和硬件設(shè)計人員帶來了巨大的工程設(shè)計挑戰(zhàn),。H.264/AVC 標(biāo)準(zhǔn)引入了自 1990 年推出 H.261 之后視頻編碼標(biāo)準(zhǔn)演進(jìn)過程中出現(xiàn)的大部分重大改變和算法間斷 (algorithmic discontinuities),。
盡管H.264/AVC承諾將此已有視頻編碼標(biāo)準(zhǔn)具有更高的編碼效率,,它仍為系統(tǒng)架構(gòu)師,、DSP 工程師和硬件設(shè)計人員帶來了巨大的工程設(shè)計挑戰(zhàn),。H.264/AVC 標(biāo)準(zhǔn)引入了自 1990 年推出 H.261 之后視頻編碼標(biāo)準(zhǔn)演進(jìn)過程中出現(xiàn)的大部分重大改變和算法間斷 (algorithmic discontinuities),。
實現(xiàn) H.264/AVC 編碼標(biāo)準(zhǔn)所需的算法計算復(fù)雜度,、數(shù)據(jù)局部性,,以及算法和數(shù)據(jù)并行性,常常會直接影響系統(tǒng)級別的整體架構(gòu)決策,。這種影響又會決定在廣播,、視頻編輯、電話會議以及消費電子領(lǐng)域開發(fā)H.264/AVC解決方案所需的最終開發(fā)成本,。
復(fù)雜度分析
為了實現(xiàn)實時 H.264/AVC 標(biāo)準(zhǔn)清晰度 (SD) 或高清晰度 (HD) 分辯率編碼解決方案,,系統(tǒng)架構(gòu)師常常需要使用多個 FPGA 和可編程 DSP。為了說明所需計算的巨大復(fù)雜度,,先探討一下 H.264/AVC 編碼器的典型運(yùn)行時的周期要求,。H.264/AVC 編碼器基于由聯(lián)合視頻工作組(JVT)提供的軟件模型,該工作組由來自 ITU-T 的視頻編碼專家組 (VCEG) 和 ISO/IEC 的運(yùn)動圖像專家組 (MPEG) 的專家組成,。
采用Intel的VTune軟件,,在 Intel Pentium III 1.0 GHz 通用 CPU、512 MB 內(nèi)存的平臺上運(yùn)行,,按照主要配置編碼解決方案實現(xiàn) H.264/AVC SD,,需要約 1,600 BOPS(每秒十億次運(yùn)算)。
表 1 顯示了基于 Pentium III 通用處理器架構(gòu)的 H.264/AVC 編碼器的復(fù)雜度的典型情況,。請注意,,在表 1 中,運(yùn)動估計,、宏塊/塊處理(包括模式?jīng)Q策),,以及運(yùn)動補(bǔ)償模塊是基本候選硬件加速單元。
然而,,單憑計算復(fù)雜度并不能決定一個功能模塊是否應(yīng)映射為硬件或是使其保持為軟件,。為了評估在由 FPGA、可編程 DSP或通用主處理器混合組成的平臺上實現(xiàn) H.264/AVC 編碼標(biāo)準(zhǔn)時,,軟件和硬件分割的可行性,,需要分析將會影響整體設(shè)計決策的大量架構(gòu)問題,。
數(shù)據(jù)局部性
在同步設(shè)計中,按照特定的順序和粒度訪問內(nèi)存,,同時根據(jù)延遲,、總線競爭、對準(zhǔn),、DMA 傳輸率以及所用內(nèi)存的類型(如 ZBT 內(nèi)存,、SDRAM和 SRAM 等)使時鐘周期數(shù)降至最小的能力至關(guān)重要。數(shù)據(jù)局部性問題主要是由數(shù)據(jù)單元和算術(shù)單元(或處理引擎)之間的物理接口體現(xiàn)的,。
數(shù)據(jù)并行性,。
大多數(shù)信號處理算法都是對高度并行的數(shù)據(jù)進(jìn)行操作(如 FIR 濾波)。單指令多數(shù)據(jù) (SIMD) 和向量處理器對可被并行化或做成向量格式(或長數(shù)據(jù)寬度)的數(shù)據(jù)具有較高的處理效率,。
FPGA可通過提供大量塊 RAM 支持大量極高總計帶寬要求來實現(xiàn)這一點,。在新的 Xilinx Virtex-4 SX器件中,塊 RAM 的數(shù)量與 Xtreme DSP的邏輯片數(shù)緊密匹配(例如,,SX25具有128個塊RAM,,128個DSP邏輯片;SX35具有192個塊 RAM,,192個DSP 邏輯片,;SX55具有320個塊 RAM,512個DSP邏輯片),。
信號處理算法并行機(jī)制,。
在典型的可編程 DSP 或通用處理器中,,信號處理算法并行機(jī)制通常是指指令級并行 (ILP),。超長指令字 (VLIW) 處理器是此類采用ILP的機(jī)器中的一個例子,它將多條指令(ADD,、MULT 及 BRA)組合起來,在一個周期內(nèi)執(zhí)行,。處理器中高度流水線化的執(zhí)行單元也是實現(xiàn)并行機(jī)制的典型硬件示例。現(xiàn)在已經(jīng)有可編程DSP采用這種架構(gòu)(如TI的TMS320C64x),。
但是,,并非所有算法都能使用這種并行機(jī)制。遞歸算法,,如 IIR 濾波,、MPEG 1/2/4 中的變長編碼 (VLC)、上下文自適應(yīng)變長編碼 (CAVLC),,以及 H.264/AVC 中的上下文自適應(yīng)二進(jìn)制算術(shù)編碼 (CABAC),,當(dāng)映射到這些可編程 DSP 時,均無法達(dá)到最優(yōu)且效率不高,。這是因為數(shù)據(jù)遞歸阻礙了 ILP 的有效利用,。作為取代方案,,可在FPGA 結(jié)構(gòu)中有效地構(gòu)建專用硬件引擎。
計算復(fù)雜度,。
可編程 DSP 受計算復(fù)雜度的限制,,可通過處理器的時鐘速率來度量。在FPGA中實現(xiàn)的信號處理算法通常為計算密集型算法,。其中的例子有運(yùn)動估計中的絕對差值和 (SAD) 引擎以及視頻縮放,。
通過將這些模塊映射到 FPGA 中,主處理器或可編程DSP就可有額外的周期來處理其他算法,。此外,,F(xiàn)PGA 結(jié)構(gòu)還可以具有多時鐘域,從而允許選擇性硬件模塊根據(jù)各自的計算要求使用獨立的時鐘速度,。
理論上質(zhì)量的最優(yōu)性,。
當(dāng)且僅當(dāng)對復(fù)雜度沒有限制時,任何基于速率失真曲線的理論最優(yōu)解決方案均可實現(xiàn),。在可編程 DSP 或通用處理器中,,計算復(fù)雜度常受可用時鐘周期的限制。而 FPGA 則相反,,通過對硬件引擎的多重實例化,,或提高結(jié)構(gòu)中塊 RAM 和寄存器組的利用率,實行數(shù)據(jù)和算法并行機(jī)制,,從而提供更高的靈活性,。
可編程 DSP 或通用處理器通常受每個周期發(fā)出的指令數(shù)、執(zhí)行單元中的流水線級數(shù)以及完全饋給執(zhí)行單元所需最大數(shù)據(jù)寬度的限制,。在可編程 DSP 中,,受每個任務(wù)可用周期數(shù)的限制,視頻質(zhì)量常常大受影響,。而在 FPGA 結(jié)構(gòu)中,,硬件資源則可得到完全分配(三步和完全搜索運(yùn)動估計對比)。
使用FPGA 實現(xiàn)功能模塊

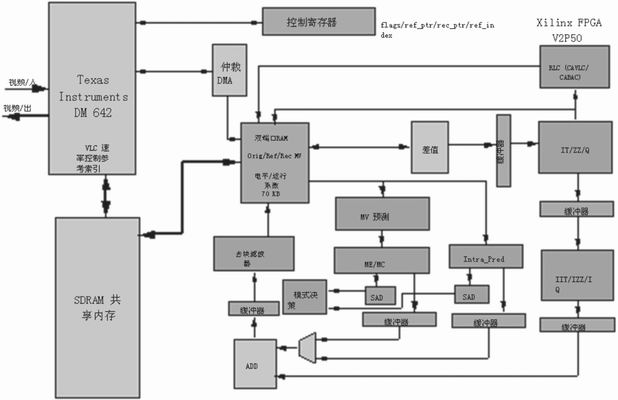
圖 1 包括功能塊和數(shù)據(jù)流的 H.264/AVC 宏塊編碼器
圖 1 為定義了主功能塊和數(shù)據(jù)流的整個 H.264/AVC 宏塊級編碼器,。H.264/AVC 標(biāo)準(zhǔn)的主要優(yōu)勢在于能夠通過以不同的方式和方向分析像素冗余,,預(yù)測要編碼的圖像內(nèi)容的值,而這種分析以前從未在其他標(biāo)準(zhǔn)中進(jìn)行過,。但與以前的標(biāo)準(zhǔn)相比,,其復(fù)雜度和內(nèi)存訪問帶寬增加了4倍。
改進(jìn)預(yù)測方法
下面重點分析一下在 H.264/AVC 視頻編碼設(shè)計中實現(xiàn)其增強(qiáng)編碼效率的主要特點,,根據(jù)前文討論過的設(shè)計準(zhǔn)則對這些功能模塊進(jìn)行評估,。
四分之一像素精度(Quarter-pixel-accurate) 運(yùn)動補(bǔ)償。
以前的標(biāo)準(zhǔn)采用二分之一像素運(yùn)動向量精度,。新設(shè)計通過采用四分之一像素運(yùn)動向量精度對此進(jìn)行了改善,。二分之一像素位置的預(yù)測值是通過沿橫向和縱向采用一個一維6抽頭 FIR 濾波器 [1, -5, 20, 20, -5, 1]/32 計算得到的,。
四分之一像素位置的預(yù)測值是通過將全像素和二分之一像素位置的采樣值進(jìn)行平均得到的。這些二次采樣內(nèi)插運(yùn)算可在 FPGA內(nèi)的硬件中高效地實現(xiàn),。
小塊尺寸可變塊大小運(yùn)動補(bǔ)償,。
該標(biāo)準(zhǔn)在 16×16 像素宏塊尺寸中為鋪瓦結(jié)構(gòu) (tiling structure) 提供了更多的靈活性。它允許使用 16×16,、16×8,、8×16、8×8,、8×4,、4×8 和 4×4 子宏塊尺寸。
由于給定 16×16 宏塊鋪瓦結(jié)構(gòu)的組合增多,,因此要找到一個速率失真優(yōu)化鋪瓦解決方案需要很高的計算強(qiáng)度,。這一額外特性為運(yùn)動估計、細(xì)化和模式?jīng)Q策過程中所用的計算引擎增加了巨大負(fù)荷,。
環(huán)中自適應(yīng)去塊(deblocking) 濾波,。
去塊濾波器已經(jīng)在 H.263+ 和 MPEG-4 第 2 部分的實現(xiàn)中作為后處理濾波器被成功采用。在 H.264/AVC 中,,去塊濾波器將在運(yùn)動補(bǔ)償環(huán)路中移動,,對在預(yù)測和解碼過程中的殘留差值編碼階段造成的塊邊緣進(jìn)行濾波。濾波對 4×4 塊和 16×16 宏塊邊緣均可進(jìn)行,,兩個邊上的兩個像素可能會被一個三抽頭濾波器更新,。濾波器系數(shù)或強(qiáng)度由內(nèi)容自適應(yīng)非線性濾波器決定。
幀內(nèi)編碼有向空間預(yù)測,。
當(dāng)無法采用運(yùn)動估計時,,可以采用幀內(nèi)有向空間預(yù)測來估計空間冗余。這種技術(shù)通過從相鄰塊沿預(yù)先定義的一組方向向相鄰像素外插來預(yù)測當(dāng)前塊,。然后就可以對預(yù)測塊和實際塊之間的差值進(jìn)行編碼了,。
這種方法在存在空間冗余的平面背景中特別有用。對于 Intra_4×4 預(yù)測,,總共有九種預(yù)測方向;對于 Intra_16×16,,則有4種預(yù)測方向,。注意,在 Intra_4×4情況下,,由于數(shù)據(jù)因果性,,將導(dǎo)致對當(dāng)前塊上邊和左邊相鄰的 13 個像素值的快速內(nèi)存訪問。對于 Intra_16×16,,每邊將使用 16個像素來預(yù)測一個 16×16 塊,。
多參考圖像運(yùn)動補(bǔ)償,。
H.264/AVC 標(biāo)準(zhǔn)為幀間編碼提供了多參考幀選項。除非參考圖像的數(shù)量為1,,否則必須指定參考圖像在多圖像緩沖區(qū)內(nèi)的索引位置,。多圖像緩沖區(qū)的尺寸決定編碼器和解碼器中內(nèi)存的使用情況。這些參考幀緩沖區(qū)必須在編碼器的運(yùn)動估計和補(bǔ)償階段分別訪問,。
加權(quán)預(yù)測,。
JVT 認(rèn)為在對一些有衰弱現(xiàn)象的視頻圖像進(jìn)行編碼時,采用加權(quán)運(yùn)動補(bǔ)償預(yù)測可以極大地改善編碼效率,。
改善編碼效率
除了預(yù)測方法得到改進(jìn)以外,,該標(biāo)準(zhǔn)設(shè)計的其他部分也對編碼效率的改善進(jìn)行了增強(qiáng)。下面兩個附加特性最容易對基于關(guān)于軟件和硬件分割的設(shè)計準(zhǔn)則的整體系統(tǒng)架構(gòu)產(chǎn)生影響,。
小塊尺寸,,層次化,精確匹配反變換和短字長變換,。
同其他標(biāo)準(zhǔn)一樣,,H.264/AVC 也是對運(yùn)動補(bǔ)償預(yù)測殘留施加變換編碼。
但是,,與以前采用 8×8 離散余弦變換 (DCT) 的標(biāo)準(zhǔn)不同,,這種變換是施加于 4 x 4 塊上,并且采用 16 位整數(shù)格式,,可以精確地進(jìn)行反變換,。小塊有助于減小分塊和振鈴結(jié)果,而精確整數(shù)規(guī)范則消除了編碼器與反變換中的解碼器之間的一切不匹配問題,。
此外,,還采用了一種基于阿達(dá)瑪矩陣 (Hadamard matrix) 的附加變換,以實現(xiàn)已變換塊的 16 個 DC 系數(shù)的冗余,。與 DCT 相比,,所有整數(shù)變換矩陣中只包含從 -2 到 2 之間的整數(shù)。這樣,,只使用低復(fù)雜度的移位寄存器和加法器就可以通過 16 位算術(shù)計算變換和反變換,。
算術(shù)和上下文自適應(yīng)熵編碼。
有兩種熵編碼方法:一種是基于上下文自適應(yīng)切換變長編碼集 (CAVLC) 的低復(fù)雜度技術(shù),,一種是計算要求更高的基于上下文的自適應(yīng)二進(jìn)制算術(shù)編碼 (CABAC) 算法,。
CAVLC 是 H.264/AVC 的基本熵編碼方法。其基本編碼工具包括一個結(jié)構(gòu)化 Exp-Golomb 編碼 VLC,,它通過單獨定制的映射,,可應(yīng)用于除與量化變換系數(shù)有關(guān)的語法元素以外的所有語法元素。CABAC則采用了一種更為復(fù)雜的編碼方案,。
首先,,根據(jù)一種預(yù)定義的掃描模式,,將變換系數(shù)映射到一個 1 維數(shù)組。量化后,,塊將只包含一些重要的非零系數(shù),。
根據(jù)該統(tǒng)計結(jié)果,使用5個數(shù)據(jù)元素來傳遞特征 4 × 4 塊的量化變換系數(shù)的信息,。使用 CABAC 可進(jìn)一步改善熵編碼的效率,。
CABAC 中的兩個部分。規(guī)定算術(shù)編碼內(nèi)核引擎及其相關(guān)的概率估計是免乘法,、低復(fù)雜度方法,,只能使用移位和查找表。自適應(yīng)編碼的使用使之能夠與非靜止符號統(tǒng)計適應(yīng),。通過采用根據(jù)前面編碼語法元素進(jìn)行估計從而在條件概率模型間切換的上下文建模方法,,CABAC 可獲得比 CAVLC 低 5~15% 的位速率。
圖2 典型H.264/AVC硬件/軟件功能塊分割
圖 2 顯示了 H.264/AVC SD 視頻編解碼器系統(tǒng)級功能塊的典型分割,。該解決方案基于針對 TI公司的TMS320DM642 DSP 的 Spectrum Digital EVM DM642 評估模塊,,結(jié)合 Xilinx XEVM642- 2VP20 Virtex-II Pro或XEVM642-4VSX25 Virtex-4子插件板實現(xiàn)。
結(jié)語
以最優(yōu)模式使用時,,與以前的視頻編碼標(biāo)準(zhǔn)(如 MPEG-4 第 2 部分和 MPEG-2)相比,,H.264/AVC 標(biāo)準(zhǔn)的編碼工具可在很寬的位速率和分辯率范圍內(nèi)使編碼效率提高約 50%。但是,,當(dāng)分辯率比源輸入格式 (SIF) 高時,,算法極為復(fù)雜。
參考文獻(xiàn)
“聯(lián)合視頻規(guī)范國際標(biāo)準(zhǔn) ITU-TU 建議草案和最終草案 (ITU-T Rec. H.264/ISO/IEC 14 496-10 AVC),,”ISO/IEC MPEG 與 ITU-T VCEG 聯(lián)合視頻工作組 (JVT) ,,JVT-G050, 2003
A. Luthra、G.J. Sullivan 和 T. Wiegand,,2003 年 7 月,。“有關(guān) H.264/AVC 視頻編碼標(biāo)準(zhǔn)的專門問題”。 IEEE Trans.電路系統(tǒng)視頻技術(shù) 13(7): 557-725
