
1 引 言
隨著數(shù)字通信和工業(yè)控制領(lǐng)域的高速發(fā)展,要求專用集成電路(ASIC)的功能越來(lái)越強(qiáng),功耗越來(lái)越低,生產(chǎn)周期越來(lái)越短,這些都對(duì)芯片設(shè)計(jì)提出了巨大的挑戰(zhàn),傳統(tǒng)的芯片設(shè)計(jì)方法已經(jīng)不能適應(yīng)復(fù)雜的應(yīng)用需求了。SoC(System on a Chip)以其高集成度,低功耗等優(yōu)點(diǎn)越來(lái)越受歡迎。開(kāi)發(fā)人員不必從單個(gè)邏輯門開(kāi)始去設(shè)計(jì)ASIC,而是應(yīng)用己有IC芯片的功能模塊,稱為核(core),或知識(shí)產(chǎn)權(quán)(IP)宏單元進(jìn)行快速設(shè)計(jì),效率大為提高。CPU 的IP核是SoC技術(shù)的核心,開(kāi)發(fā)出具有自主知識(shí)產(chǎn)權(quán)的CPU IP核對(duì)我國(guó)在電子技術(shù)方面跟上世界先進(jìn)的步伐,提高信息產(chǎn)業(yè)在世界上的核心竟?fàn)幜τ兄卮笠饬x。
精簡(jiǎn)指令集計(jì)算機(jī)RISC(Reduced Instruction Set Computer)是針對(duì)復(fù)雜指令集計(jì)算機(jī)CISC(Complex Instruction Set Computer)提出的,具備如下特征1)一個(gè)有限的簡(jiǎn)單的指令集; 2)強(qiáng)調(diào)寄存器的使用或CPU配備大量的能用的寄存器;3)強(qiáng)調(diào)對(duì)指令流水線的使用。
2 CPU IP核的組成
盡管各種CPU的性能指標(biāo)和結(jié)構(gòu)細(xì)節(jié)不同,但所要完成的基本功能相同,從整體上可分為八個(gè)基本的部件:時(shí)鐘發(fā)生器、指令寄存器、累加器、RISC CPU算術(shù)邏輯運(yùn)算單元、數(shù)據(jù)控制器、狀態(tài)控制器、程序控制器、程序計(jì)數(shù)器、地址多路器。狀態(tài)控制器負(fù)責(zé)控制每一個(gè)部件之間的相互操作關(guān)系,具體的結(jié)構(gòu)和邏輯關(guān)系如圖1所示。
時(shí)鐘發(fā)生器利用外部時(shí)鐘信號(hào),經(jīng)過(guò)分頻生成一系列時(shí)鐘信號(hào)給CPU中的各個(gè)部件使用。為了保證分頻后信號(hào)的跳變性能,在設(shè)計(jì)中采用了同步狀態(tài)機(jī)的方法。
指令寄存器在觸發(fā)時(shí)鐘clk1的正跳變觸發(fā)下,將數(shù)據(jù)總線送來(lái)的指令存入寄存器中。數(shù)據(jù)總線分時(shí)復(fù)用傳遞數(shù)據(jù)和指令,由狀態(tài)控制器的load_ir信號(hào)負(fù)責(zé)判別。load_ir信號(hào)通過(guò)使能信號(hào)ena口線輸入到指令寄存器。復(fù)位后,指令寄存器被清為零。每條指令為兩個(gè)字節(jié)16位,高3位是操作碼,低13位是地址線。CPU的地址總線為是13位,位尋址空間為8K 字節(jié)。本設(shè)計(jì)的數(shù)據(jù)總線是8位,每條指令取兩次,每次由變量state控制。
累加器用于存放當(dāng)前的運(yùn)算結(jié)果,是雙目運(yùn)算中的一個(gè)數(shù)據(jù)來(lái)源。復(fù)位后,累加器的值為零。當(dāng)累加器通過(guò)使能信號(hào)ena 口線收到來(lái)自CPU狀態(tài)控制器load_acc 信號(hào)后,在clk1時(shí)鐘正跳沿時(shí)就接收來(lái)自數(shù)據(jù)總線的數(shù)據(jù)。

圖1 CPU結(jié)構(gòu)圖
算術(shù)邏輯運(yùn)算單元根據(jù)輸入的不同的操作碼分別實(shí)現(xiàn)相應(yīng)的加、與、異或、跳轉(zhuǎn)等基本運(yùn)算。
數(shù)據(jù)控制器其作用是控制累加器的數(shù)據(jù)輸出,由于數(shù)據(jù)總線是各種操作傳送數(shù)據(jù)的公共通道,分時(shí)復(fù)用,有時(shí)傳輸指令,有時(shí)要傳送數(shù)據(jù)。其余時(shí)候,數(shù)據(jù)總線應(yīng)呈高阻態(tài),以允許其他部件使用。所以,任何部件向總線上輸出數(shù)據(jù)時(shí),都需要一個(gè)控制信號(hào)的,而此控制信號(hào)的啟、停則由CPU狀態(tài)控制器輸出的各信號(hào)控制決定。控制信號(hào)datactl_ena決定何時(shí)輸出累加器中的數(shù)據(jù)。
地址多路器用于輸出的地址是PC(程序計(jì)數(shù)器)地址還是數(shù)據(jù)/端口地址。每個(gè)指令周期的前4個(gè)時(shí)鐘周期用于從ROM中讀取指令,輸出的應(yīng)是PC地址,后4個(gè)時(shí)鐘周期用于對(duì)RAM或端口的讀寫,該地址由指令給出,地址的選擇輸出信號(hào)由時(shí)鐘信號(hào)的8分頻信號(hào)fecth提供。
程序計(jì)數(shù)器用于提供指令地址,以便讀取指令,指令按地址順序存放在存儲(chǔ)器中,有兩種途徑可形成指令地址,一是順序執(zhí)行程序的情況,二是執(zhí)行JMP指令后,獲得新的指令地址。
狀態(tài)機(jī)控制器接受復(fù)位信號(hào)RST,當(dāng)RST有效時(shí),能通過(guò)信號(hào)ena使其為0 ,輸入到狀態(tài)機(jī)中以停止?fàn)顟B(tài)機(jī)的工作。狀態(tài)機(jī)是CPU 的控制核心,用于產(chǎn)生一系列的控制信號(hào),啟動(dòng)或停止某些部件,CPU何時(shí)進(jìn)行讀指令來(lái)讀寫I/O端口及RAM區(qū)等操作,都是由狀態(tài)機(jī)來(lái)控制的。狀態(tài)機(jī)的當(dāng)前狀態(tài),由變量state記錄,state的值就是當(dāng)前這個(gè)指令周期中已經(jīng)過(guò)的時(shí)鐘數(shù)。指令周期是由8 個(gè)時(shí)鐘組成,每個(gè)時(shí)鐘都要完成固定的操作。
3 系統(tǒng)時(shí)序
RISC CPU的復(fù)位和啟動(dòng)操作是通過(guò)rst引腳的信號(hào)觸發(fā)執(zhí)行的,當(dāng)rst信號(hào)一進(jìn)入高電平,RISC CPU就會(huì)結(jié)束現(xiàn)行操作,并且只要rst停留在高電平狀態(tài),CPU就維持在復(fù)位狀態(tài),CPU各狀態(tài)寄存器都設(shè)為無(wú)效狀態(tài)。當(dāng)信號(hào)rst回到低電平,接著到來(lái)的第一個(gè)fetch 上升沿將啟動(dòng)RISC CPU開(kāi)始工作,從ROM的000處的開(kāi)始讀取指令并 執(zhí)行相應(yīng)的操作。
讀指令時(shí)序,每個(gè)指令的前3個(gè)時(shí)鐘周期用于讀指令,4~6周期讀信號(hào)rd有效,第7 個(gè)周期讀信號(hào)無(wú)效,第8個(gè)周期地址總線輸出PC地址,為下一個(gè)指令作準(zhǔn)備。
寫指令時(shí)序,每個(gè)指令的第3.5個(gè)時(shí)鐘周期建立寫地址,第四個(gè)周期輸出數(shù)據(jù),第5個(gè)時(shí)鐘周期輸出寫信號(hào),第6個(gè)時(shí)鐘結(jié)束,第7.5個(gè)時(shí)鐘周期輸出為PC地址,為下個(gè)指令做準(zhǔn)備。
如圖2 所示,這是ModelSim SE6.0進(jìn)行波形仿真的結(jié)果。
4 微處理器指令
數(shù)據(jù)處理指令:數(shù)據(jù)處理指令完成寄存器中數(shù)據(jù)的算術(shù)和邏輯操作,其他指令只是傳送數(shù)據(jù)和控制程序執(zhí)行的順序.因此,數(shù)據(jù)處理指令是唯一可以修改數(shù)據(jù)值的指令,數(shù)據(jù)處理指令一般需兩個(gè)源操作數(shù),產(chǎn)生單個(gè)結(jié)果.所有的操作數(shù)都是8位寬,或者來(lái)自寄存器,或者來(lái)自指令中定義的立即數(shù).每一個(gè)源操作數(shù)寄存器和結(jié)果寄存器都在指令中獨(dú)立的指定。
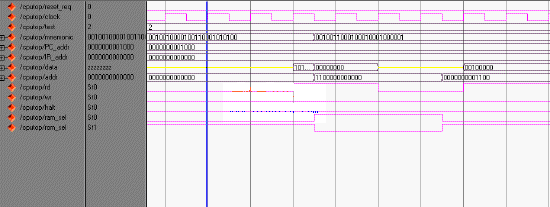
圖2 讀寫指令時(shí)序
數(shù)據(jù)傳送和控制轉(zhuǎn)移類指令:共有17條,不包括按布爾變量控制程序轉(zhuǎn)移的指令。其中有全存儲(chǔ)空間的長(zhǎng)調(diào)用、長(zhǎng)轉(zhuǎn)移和按2KB分塊的程序空間內(nèi)的絕對(duì)調(diào)用和絕對(duì)轉(zhuǎn)移;全空間的長(zhǎng)度相對(duì)
轉(zhuǎn)移及一頁(yè)范圍內(nèi)的短相對(duì)轉(zhuǎn)移;還有條件轉(zhuǎn)移指令。這類指令用到的助記符有ACALL, AJMP, LCALL, LJMP, SJMP, M, JZ, JNZ, ONE,DJNZ。控制轉(zhuǎn)移類指令主要用來(lái)修改1x指針從而達(dá)到對(duì)程序流的控制,所用到的寄存器主要有sp, pc, ir等寄存器。
指令由操作碼和操作數(shù)組成,取指令電路的目的就是把指令碼和操作數(shù)分開(kāi)。組成電路由如圖3所示。取指令電路由程序指針,程序指針解析模塊、ROM, IR(指令寄存器),控制器狀態(tài)寄存器組成。取指令指令的過(guò)程如下:PC指針的值經(jīng)過(guò)pc_mux模塊賦值,把ROM中的指令取出來(lái),送到指令寄存器的數(shù)據(jù)輸入口。指令寄存器受狀態(tài)寄存器的控制,當(dāng)取指令信號(hào)有效時(shí),ROM中的指令碼被保存在指令寄存器中,然后經(jīng)控制器譯碼,產(chǎn)生控制信號(hào),對(duì)PC指針的增量加以控制取出下一條指令。
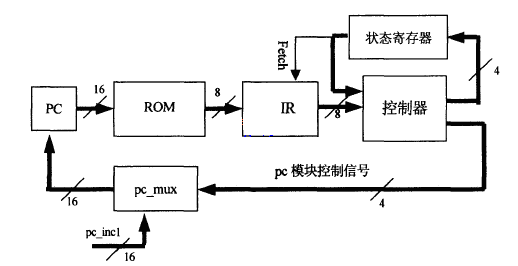
圖3 取指令電路
5 匯編
匯編程序是為了調(diào)試軟核而開(kāi)發(fā)的,手工編寫機(jī)器碼很容易出錯(cuò)并且工作量很大。在調(diào)試過(guò)程中修改指令集時(shí),匯編程序也要作相應(yīng)的修改。所以要求編譯器的結(jié)構(gòu)簡(jiǎn)單性能可靠,在程序中必要的地方可以用堆疊代碼方法實(shí)現(xiàn),不必考慮編程技巧和匯編器效率問(wèn)題。匯編程序用于測(cè)試RISC CPU的基本指令集,如果CPU的各條指令執(zhí)行正確,停止在HLT指令處。如果程序在其它地址暫停運(yùn)行,則有一個(gè)指令出錯(cuò)。程序中,@符號(hào)后的十六進(jìn)制表示存儲(chǔ)器的地址,每行的//后表示注釋。下面是一小段程序代碼,編譯好的匯編機(jī)器代碼裝入虛擬ROM,要參加運(yùn)算的數(shù)據(jù)裝入虛擬RAM就可以開(kāi)始進(jìn)行仿真。
機(jī)器碼 地址 匯編助記符 注釋
@00 //地址聲明
101_11000 //00 BEGIN: LDA DATA_2
0000_0001
011_11000 //02 AND DATA_3
0000_0010
100_11000 //04 XOR DATA_2
0000_0001 001_00000 //06 SKZ
0000_0000
000_00000 //08 HLT //AND does't work
6 調(diào)試
最基本的調(diào)試手段
是基于FPGA 廠商提供的開(kāi)發(fā)和仿真環(huán)境,用硬件描述語(yǔ)言編寫TESTBENCH,構(gòu)成一個(gè)最小運(yùn)行環(huán)境。TESTBENCH產(chǎn)生對(duì)目標(biāo)軟核的激勵(lì),同時(shí)記錄軟核的輸出,和預(yù)期值進(jìn)行比對(duì),可以確定核的設(shè)計(jì)錯(cuò)誤。這種方法的好處是實(shí)現(xiàn)容易,結(jié)果準(zhǔn)確,但硬件描述語(yǔ)言編碼量較大。為了仿真結(jié)果的準(zhǔn)確性,無(wú)論功能仿真還是時(shí)序仿真,仿真的步長(zhǎng)都不能太小,結(jié)果導(dǎo)致整個(gè)系統(tǒng)仿真時(shí)間太長(zhǎng)。本設(shè)計(jì)中先對(duì)RISC CPU的各個(gè)子模塊進(jìn)行了分別綜合,檢查正確性,如果發(fā)現(xiàn)錯(cuò)誤可以在較小的范圍內(nèi)來(lái)檢查并驗(yàn)證。子模塊綜合完畢后,把要綜合的RISC CPU的模塊與外圍器件以及測(cè)試模塊分離出來(lái)組成一個(gè)大模塊,綜合后的的RISC CPU模塊如圖4所示,這是Xilinx ISE7.1 所綜合生成的技術(shù)原理圖。
綜合的結(jié)果只是通用的門級(jí)網(wǎng)表,只是一些與、或、非門的邏輯關(guān)系,和芯片實(shí)際的配置情況還有差距。此時(shí)應(yīng)該使用FPGA/CPLD廠商提供的實(shí)現(xiàn)與布局布線工具,根據(jù)所選芯片的型號(hào),進(jìn)行芯片內(nèi)部功能單元的實(shí)際連接與映射。這種實(shí)現(xiàn)與布局布線工具一般要選用所選器件的生產(chǎn)商開(kāi)發(fā)的工具,因?yàn)橹挥猩a(chǎn)者最了解器件內(nèi)部的結(jié)構(gòu),如在ISE的集成環(huán)境中完成實(shí)現(xiàn)與布局布線的工具是Flow Engine。
圖4 CPU技術(shù)原理圖
STA(Static Timing Analysis)靜態(tài)時(shí)序分析,完成FPGA設(shè)計(jì)時(shí)必須的一個(gè)步驟。在FPGA加約束、綜合、布局布線后,在ISE中可以運(yùn)行Timing Analyzer生成詳細(xì)的時(shí)序報(bào)告,本設(shè)計(jì)中Minimum period: 12.032ns (Maximum Frequency: 83.112MHz),Minimum input arrival time before clock: 6.479ns,Maximum output required time after clock: 9.767ns。然后,設(shè)計(jì)人員檢查時(shí)序報(bào)告,根據(jù)工具的提示找出不滿足Setup/Hold time的路徑,以及不符合約束的路徑,進(jìn)行修改保證數(shù)據(jù)能被正確的采樣。在后仿真中將布局布線的時(shí)延反標(biāo)到設(shè)計(jì)中去,使仿真既包含門延時(shí),又包含線延時(shí)信息。這種后仿真是最準(zhǔn)確的仿真,能真實(shí)地反映芯片的實(shí)際工作情況。
7 結(jié) 論
復(fù)雜的RISC CPU設(shè)計(jì)是一個(gè)從抽象到具體的過(guò)程,本文根據(jù)FPGA的結(jié)構(gòu)特點(diǎn),圍繞在FPGA上設(shè)計(jì)實(shí)現(xiàn)八位微處理器軟核設(shè)計(jì)方法進(jìn)行探討,研究了片上系統(tǒng)的設(shè)計(jì)方法和設(shè)計(jì)復(fù)用技術(shù),并給出了指令集和其調(diào)試方法,提出了一種基于FPGA的微處理器的IP的設(shè)計(jì)方法。本文作者創(chuàng)新點(diǎn)是:根據(jù)Spartan II 的內(nèi)部結(jié)構(gòu),在編碼階段實(shí)現(xiàn)了地址和數(shù)據(jù)的優(yōu)化,實(shí)現(xiàn)階段對(duì)內(nèi)部布局布線進(jìn)行重新配置,設(shè)計(jì)實(shí)現(xiàn)的微處理器僅占用78個(gè)slices,1個(gè)Block RAM,在10萬(wàn)門的芯片實(shí)現(xiàn),占用6%的資源。
參考文獻(xiàn):
[1] 夏宇聞.Verilog數(shù)字系統(tǒng)設(shè)計(jì)教程[M].北京: 北京航空航天大學(xué)出版社,2003. [2] 袁俊泉 孫敏琪 曹瑞 Verilog數(shù)字系統(tǒng)設(shè)計(jì)教程[M].西安: 西安電子科技大學(xué)出版社,2002.
[3] J.Bhasjer 著 孫海平 等譯 Verilog HDL綜合實(shí)用教程[M].北京: 清華大學(xué)出版社,2004.
[4] 楊厚俊 張公敬 張昆藏 編著 計(jì)算機(jī)系統(tǒng)結(jié)構(gòu)---奔騰PC[M].北京: 科學(xué)出版社,2004.
[5] 馮海濤 王永綱 石江濤 顏天信 王硯方. 基于FPGA的32位整數(shù)微處理器的設(shè)計(jì)與實(shí)現(xiàn)[J]. 小型微型計(jì)算機(jī)系統(tǒng), 2005, 26(6): 1113-1117.
[6] 王喆.八位CPU IP核的研究與設(shè)計(jì)[D].大連:大連理工大學(xué),2005
[7] http://www.xilinx-china.com/
[8] 袁本榮 劉萬(wàn)春 賈云得 朱玉文 用Verilog HDL進(jìn)行FPGA設(shè)計(jì)的一些基本方法[J].微計(jì)算機(jī)信息,2004,20(6):93-95