
摘 要: 針對最大簡約法的搜索速度慢等特點(diǎn),提出了一種遺傳算法與模擬退火算法相結(jié)合的啟發(fā)式搜索方法。利用模擬退火算法保障物種的多樣性,克服了遺傳算法的早熟現(xiàn)象,加快了實(shí)驗(yàn)后期的收斂速度。結(jié)果表明,該算法的準(zhǔn)確性和運(yùn)算效率都有較大提高。
關(guān)鍵詞: 種系發(fā)生樹;最大簡約法;遺傳算法;模擬退火算法
系統(tǒng)發(fā)生(也稱種系發(fā)生或系統(tǒng)發(fā)育,phylogenetic inference) 是指生物形成或進(jìn)化的歷史[1],其基本思想是比較物種的特征,并認(rèn)為特征相似的物種在遺傳學(xué)上接近[2]。其研究的結(jié)果則以系統(tǒng)發(fā)生樹(phylogenetic tree)表示,用它描述物種之間的進(jìn)化關(guān)系。系統(tǒng)發(fā)生分析是根據(jù)某種標(biāo)準(zhǔn),從給定的一組序列數(shù)據(jù)中推導(dǎo)出這些對象之間“最好”的系統(tǒng)發(fā)生樹的過程。
簡約法構(gòu)建發(fā)生樹,主要問題就是龐大的搜索空間。遺傳算法是應(yīng)用于搜尋各類問題最優(yōu)解的一種方法,因此,基于遺傳算法來尋找最大簡約樹是適合的。但該算法有兩個嚴(yán)重的缺點(diǎn),容易導(dǎo)致過早收斂、以及在進(jìn)化后期搜索效率低[3]。
基于最優(yōu)原則的最大簡約法的啟發(fā)式搜索,將模擬退火算法引入遺傳算法群體更新的階段,既保證群體多樣性,又在后期逐步加快收斂速度,克服遺傳算法早熟現(xiàn)象,最終目標(biāo)是盡量使得最大簡約樹的樹長最小、搜索時間最短。
1 最大簡約法算法描述
最大簡約法通過簡約標(biāo)準(zhǔn)可以從現(xiàn)存后代的序列中客觀地推測出祖先狀態(tài),不僅可以填補(bǔ)分子進(jìn)化研究中的空白,更是對進(jìn)化理論研究的重大貢獻(xiàn)。對于系統(tǒng)發(fā)生樹最直觀的代價計(jì)算就是沿著各個分支累加特征變化的數(shù)目,而所謂簡約就是使代價最小[4]。利用最大簡約方法構(gòu)建系統(tǒng)發(fā)生樹,實(shí)際上是一個對給定分類單元所有可能的樹進(jìn)行比較的過程,針對某一個可能的樹,首先對每個位點(diǎn)祖先序列的核苷酸組成做出推斷,然后統(tǒng)計(jì)每個位點(diǎn)闡明差異的核苷酸最小替換數(shù)目。在整個樹中,所有簡約信息位點(diǎn)最小核苷酸替換數(shù)的總和稱為樹的長度或樹的代價。通過比較所有可能的樹,選擇其中長度最小、代價最小的樹作為最終的系統(tǒng)發(fā)生樹,即最大簡約樹[5]。
2 遺傳算法基本理論
遺傳算法(genetic algorithm)由美國HOLAND教授于1975年首次提出,是一類通過模擬生物界自然選擇和自然遺傳機(jī)制的隨機(jī)化搜索算法[3]。遺傳算法首先對問題的解進(jìn)行編碼,然后從一組隨機(jī)產(chǎn)生的初始解(稱為群體)開始搜索過程。群體中的每個個體是問題的一個解,稱為染色體。遺傳算法主要通過交叉、變異、選擇運(yùn)算實(shí)現(xiàn),染色體的好壞用適應(yīng)度來衡量。根據(jù)適應(yīng)度的大小從上一代和后代中選擇一定數(shù)量的個體,作為下一代群體再繼續(xù)進(jìn)化,這樣經(jīng)過若干代之后,算法收斂于最好的染色體,它很可能就是問題的最優(yōu)解或次優(yōu)解。遺傳算法中使用適應(yīng)度的概念來度量群體中的每個個體在優(yōu)化計(jì)算中達(dá)到最優(yōu)解的優(yōu)良程度[6]。
3 模擬退火算法基本理論
模擬退火算法來源于固體退火原理,將固體加溫至充分高,再讓其徐徐冷卻,加溫時,固體內(nèi)部粒子隨溫度升高變?yōu)闊o序狀,內(nèi)能增大;而徐徐冷卻時粒子漸趨有序,使每個溫度都達(dá)到平衡態(tài),最后在常溫時達(dá)到基態(tài),內(nèi)能減為最小。根據(jù)Metropolis準(zhǔn)則,將內(nèi)能E模擬為目標(biāo)函數(shù)值f,溫度T演化成控制參數(shù)t,由初始解i和t0開始,對當(dāng)前解重復(fù)“產(chǎn)生新解→計(jì)算目標(biāo)函數(shù)差→接受或舍棄”的迭代,并逐步衰減t值,算法終止時的當(dāng)前解即為所得近似最優(yōu)解。退火過程由冷卻進(jìn)度表控制,并具有以一定的概率接受惡化解的特點(diǎn)[7]。
4 基于遺傳算法和模擬退火算法的最大簡約法
雖然從發(fā)現(xiàn)了“早熟”現(xiàn)象,并對它所提出的改進(jìn)策略有多種,但都是從遺傳算子本身尋找改進(jìn)方法,并沒有根本解決“早熟”現(xiàn)象,它仍然是困擾遺傳算法的一個問題,所以當(dāng)把遺傳算法應(yīng)用在進(jìn)化樹構(gòu)建中時,并沒有達(dá)到令人完全滿意的效果。遺傳算法把握總體的能力較強(qiáng),但局部搜索能力較差;而模擬退火算法具有較強(qiáng)的局部搜索能力,因此,為了克服遺傳算法和模擬退火算法各自的缺點(diǎn),發(fā)揮它們的優(yōu)勢,本文利用模擬退火算法對遺傳算子進(jìn)行改進(jìn),使遺傳算法與模擬退火算法相結(jié)合,并應(yīng)用在簡約法構(gòu)建進(jìn)化樹上。
(1)編碼方式、適應(yīng)度函數(shù)和種群的初始化
由于輸入數(shù)據(jù)是核苷酸序列,由A,C,G,T(U)所組合而成,因此直接使用這四個字母,將輸入的每一個核苷酸序列看成一個編碼,不需要進(jìn)行額外操作。
使用簡約法意義下的樹長作為適應(yīng)度函數(shù),其值為進(jìn)化樹的適應(yīng)值,為了加速算法的收斂,定義歷史最大簡約樹為整個搜索過程中出現(xiàn)的具有歷史最低適應(yīng)值的樹。
根據(jù)輸入的物種序列,隨機(jī)產(chǎn)生初始群體。
(2)選擇退火算子
將生成的初始群體中的PopSize個個體進(jìn)行適應(yīng)度評價,個體適應(yīng)度值越大,該個體被遺傳到下一代的概率也越大。采用隨機(jī)聯(lián)賽選擇方法,聯(lián)賽規(guī)模N取值為2。
①隨機(jī)選擇初始群體兩個個體Pi、Pj,計(jì)算其個體適應(yīng)度值f(Pi)和f(Pj)。
②如果f(Pi)<f(Pj),則選擇個體Pi遺傳到下一代;否則,以概率P接受個體Pi;
③重復(fù)①、②操作直到新的一代群體中也包含PopSize個個體。
(3)復(fù)制操作
對種群里的PopSize棵進(jìn)化樹依照適應(yīng)值得分進(jìn)行排序。由于適應(yīng)值就是最大簡約法的樹長,得分越低,進(jìn)化樹差異越小,所以得分越低的進(jìn)化樹排序越靠前。將種群里的進(jìn)化樹排序完成后,復(fù)制過程也就結(jié)束了。
(4)交叉退火算子
挑選經(jīng)復(fù)制過程后的第一棵進(jìn)化樹,也就是適應(yīng)值最小的進(jìn)化樹,將這棵經(jīng)由最優(yōu)適應(yīng)值進(jìn)化樹所產(chǎn)生的樹標(biāo)記為α;再由復(fù)制過程產(chǎn)生的PopSize棵進(jìn)化樹中,隨機(jī)挑選出一棵,復(fù)制此進(jìn)化樹,將其標(biāo)記為β;接著β再去與α進(jìn)行交配:由β進(jìn)化樹隨機(jī)選擇分支,將此分支標(biāo)記為δ,接著將α樹中移除δ分支所包含的所有物種,同時刪除α樹中多余的分支。將δ分支插入到α樹中得分最高的位置。插入之后,就得到了一棵新的進(jìn)化樹。完成這樣的一串動作之后,也就是完成了一次交配:α樹與β樹經(jīng)由交配結(jié)合而形成了一棵新的進(jìn)化樹。重復(fù)以上操作以概率Pc完成對父代的交叉操作。圖1~圖5所示為一個交叉過程。

分別計(jì)算父代和子代的適應(yīng)度值,進(jìn)行前文所述的退火操作。具體操作過程如下:
①選取適應(yīng)值最小的樹α及任意的樹β,并由β隨機(jī)選擇分支。
②將父代個體α、β進(jìn)行交叉,生成子代個體α,計(jì)算個體適應(yīng)度f(α),f(α′)。
③進(jìn)行退火操作,如果f(α)<f(α),則用α′代替α,否則,以概率P接受α′。
④循環(huán)步驟②、③,直到以概率Pc完成所有父代個體的交叉操作。
(5)變異退火算子
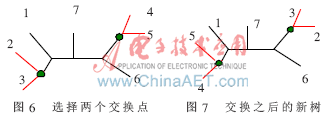
由復(fù)制過程產(chǎn)生的PopSize棵進(jìn)化樹中,隨機(jī)挑選一棵。對挑出的這棵進(jìn)化樹隨機(jī)選取兩個不同的內(nèi)部節(jié)點(diǎn)作為交換點(diǎn),并交換這兩個交換點(diǎn),同時移動交換點(diǎn)以下的所有節(jié)點(diǎn)和分支。這樣就完成了一次突變過程。圖6所示為選擇兩個交換點(diǎn),圖7是兩個點(diǎn)交換之后形成的新樹。
具體操作過程如下:
①隨機(jī)選擇個體Pi的兩個內(nèi)部節(jié)點(diǎn)做變異生成新個體Pi′;
②計(jì)算個體適應(yīng)度值f(Pi)和f(Pi′)。如果f(Pi′)<f(Pi),則用Pi′代替Pi;否則,以概率P接受Pi′;
③重復(fù)步驟①、②。
(6)更新初始群體
將復(fù)制過程、交配過程和突變過程產(chǎn)生的樹作為新的族群,作為下一次迭代的初始群體。若當(dāng)前群體中最佳個體的適應(yīng)度比總的迄今為止的最好個體的適應(yīng)度還要高,以當(dāng)前群體中的最佳個體作為新的迄今為止的最好個體,同時用該個體替換掉當(dāng)前群體中的最差個體。
(7)結(jié)束條件
①群體進(jìn)化的代數(shù)超過最大代數(shù)值時;
②進(jìn)化代數(shù)超過一定值而適應(yīng)度值不再提高時,這個值為適應(yīng)代數(shù)。
最后一代中適應(yīng)度值最高的個體即為最優(yōu)解。
5 實(shí)驗(yàn)結(jié)果
對于基于簡約法的建樹方法,可以從運(yùn)行時間和樹長兩個指標(biāo)來衡量。對遺傳退火簡約法,以TreeBASE(http://treebase.org/treebase/)所提供的序列資料作為測試數(shù)據(jù)的來源進(jìn)行了數(shù)據(jù)實(shí)驗(yàn)和模擬實(shí)驗(yàn)。并選擇了與 PHYLIP軟件做對比,本算法主要涉及的參數(shù)為:群體規(guī)模PopSize=100,最大進(jìn)化代數(shù)MaxGeneration=200,交叉概率Pc=0.6,變異概率Pm=0.1,生成的初始群體用參數(shù)P0表示,選擇算子聯(lián)賽規(guī)模N=2。接受惡化解的概率公式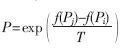 ,實(shí)驗(yàn)結(jié)果如表1所示。
,實(shí)驗(yàn)結(jié)果如表1所示。
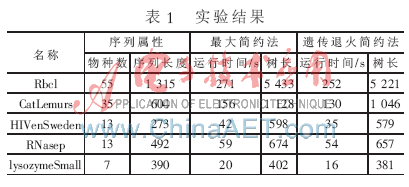
從表1可以看出,設(shè)計(jì)的遺傳退火簡約算法要比最大簡約法具有更高的運(yùn)算效率和準(zhǔn)確性。
構(gòu)建發(fā)生樹的研究是生物信息學(xué)中的一個熱點(diǎn),已建立和發(fā)展了許多新的技術(shù)和方法,但由于問題的復(fù)雜性,目前還沒有一種最優(yōu)算法能在適當(dāng)?shù)臅r間內(nèi)計(jì)算得到其精確解。本文中的改進(jìn)算法相比原有算法性能上有了提高,但是仍有不足的地方,需要進(jìn)一步地完善。
參考文獻(xiàn)
[1] 呂寶忠,鐘揚(yáng).分子進(jìn)化與系統(tǒng)發(fā)育[M].北京:高等教育出版社,2002.
[2] 張陽德.生物信息學(xué)[M].北京:科學(xué)出版社,2004.
[3] 李敏強(qiáng).遺傳算法的基本理論與應(yīng)用[M].北京:科學(xué)出版社,2002.
[4] 鐘揚(yáng),王莉,張亮.生物信息學(xué)[M].北京:高等教育出版社,2003.
[5] 孫嘯,陸祖宏,謝建明.生物信息學(xué)基礎(chǔ)[M].北京:清華大學(xué)出版社,2005.
[6] TIENG K, OPHIR F. Parallel computation in biological sequence analysis[J]. IEEE Transaction on parallel and Distributed Systems, 1998,9(3):21-25.
[7] 丁永生.計(jì)算智能—理論、技術(shù)與應(yīng)用[M].北京:科學(xué)出版社,2004.