
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2010)09-0050-04
計(jì)算機(jī)斷層成像技術(shù)CT(Computed Tomography)作為一種新型的成像方式已經(jīng)被廣泛應(yīng)用于醫(yī)學(xué),、工業(yè)等領(lǐng)域,。三維CT相對(duì)于傳統(tǒng)二維CT有空間分辨率高,各向同性的優(yōu)勢(shì)[1],。但是由于三維圖像重建運(yùn)算量大,,重建時(shí)間長的問題已成為制約其走向?qū)嵱玫钠款i。
目前,,重建加速研究主要集中在通過改進(jìn)算法的軟件加速及利用GPU,、FPGA進(jìn)行的硬件加速。其中,,F(xiàn)PGA由于具有極佳的并行計(jì)算能力及可重構(gòu)可定制的特點(diǎn)[2],,利用FPGA實(shí)現(xiàn)CT重建加速正逐漸引起研究人員的注意。
2002年Miriam Leeser[3]首次利用FPGA對(duì)二維CT重建進(jìn)行了加速,重建規(guī)模為512^2時(shí)需要3.6 s,。2003年Iain Goddard[4]首次對(duì)三維CT重建FDK算法中的反投影過程用FPGA實(shí)現(xiàn)加速,,重建規(guī)模為512^3時(shí),反投影過程需要38.7 s,;2008年Benno Heigl[5]用9塊FPGA協(xié)調(diào)配合完成了FDK算法中濾波及反投影部分的加速,,重建規(guī)模為512^3時(shí),該過程共需要9 s,。2009年Nikhil Subramanian[6]利用FPGA作為協(xié)處理器用Impulse c語言開發(fā)實(shí)現(xiàn)了二維CT重建過程的加速,,重建規(guī)模為512^2時(shí),反投影過程需要38.4 ms,。
在FPGA內(nèi)實(shí)現(xiàn)硬件加速是通過全數(shù)據(jù)流的形式處理,,脫離了指令的操作。為了充分利用FPGA的片內(nèi)資源以獲得更高的加速效果,,本文設(shè)計(jì)了一種并行無等待流水線的處理結(jié)構(gòu),,同時(shí)對(duì)核心算法電路進(jìn)行資源優(yōu)化,在保持高度并行性的同時(shí)保證了較高的資源利用率,。
1 FDK算法


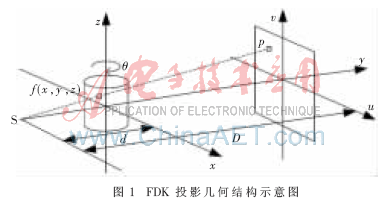
在FDK算法中,,反投影的計(jì)算復(fù)雜度與時(shí)間消耗都是最大的,是制約重建速度的瓶頸所在,,因此本文研究在FPGA內(nèi)實(shí)現(xiàn)反投影部分的加速方法,。
2 FPGA反投影加速實(shí)現(xiàn)
反投影過程需要對(duì)重建物體旋轉(zhuǎn)一周所采集到的數(shù)據(jù)進(jìn)行處理。實(shí)際情況中采集數(shù)據(jù)的過程是離散的,,且每一個(gè)分度下投影數(shù)據(jù)的處理過程不相關(guān),。基于這種可并行性,,用FPGA加速的思路是并行計(jì)算反投影過程,,并且在保證每一個(gè)反投影單元速度最快時(shí)并行盡可能多的反投影單元。
2.1 無等待流水線的設(shè)計(jì)
重建物體體素的反投影流程有3個(gè)步驟,。首先根據(jù)圖1的幾何關(guān)系定位出重建體素在探測(cè)器上的位置,;然后從存儲(chǔ)器中讀取相應(yīng)數(shù)據(jù);最后對(duì)所讀取數(shù)據(jù)進(jìn)行雙線性插值,。
通過流水線設(shè)計(jì),,雙線性插值部分可以在每一個(gè)時(shí)鐘更新一個(gè)數(shù)據(jù),但是每更新一個(gè)數(shù)據(jù)需要從數(shù)據(jù)存儲(chǔ)空間讀取4個(gè)數(shù)據(jù)來計(jì)算,,如果花費(fèi)4個(gè)時(shí)鐘周期來讀取這4個(gè)數(shù)據(jù),,就會(huì)造成前級(jí)數(shù)據(jù)讀取時(shí)間大于后級(jí)雙線性插值時(shí)間,雙線性插值處理單元會(huì)產(chǎn)生空泡,??张莸漠a(chǎn)生,,不但制約了后級(jí)處理單元的計(jì)算速度,也造成FPGA內(nèi)資源利用率的降低,。
為了解決上述問題,,提高處理速度以及資源利用率,分析雙線性插值過程所讀取4個(gè)數(shù)據(jù)之間的關(guān)系,,如圖2所示,。
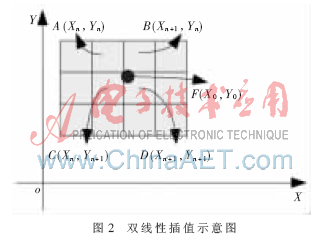

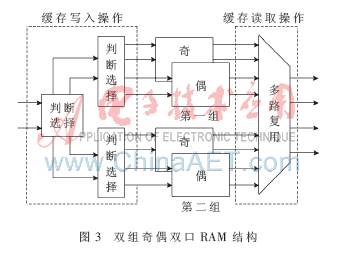
圖3中兩組共四個(gè)存儲(chǔ)空間均為FPGA片內(nèi)設(shè)計(jì)的雙口RAM。通過數(shù)據(jù)預(yù)取技術(shù)以及兩組RAM之間的乒乓操作避免了雙線性插值時(shí)隨機(jī)訪問外部存儲(chǔ)器帶來的延遲,。在反投影處理中,,第一組RAM處于數(shù)據(jù)寫入過程時(shí),分別向該組兩塊RAM寫入探測(cè)器上奇數(shù)行數(shù)據(jù)與偶數(shù)行數(shù)據(jù),。同時(shí)另一組RAM中的數(shù)據(jù)進(jìn)行雙線性插值,。計(jì)算完成后,兩組RAM進(jìn)行讀寫狀態(tài)的互換,,完成一次乒乓循環(huán),。在投影尋址單元中,計(jì)算出A(Xn,,Yn)的縱坐標(biāo)Yn,,對(duì)其奇偶性進(jìn)行判斷,當(dāng)其為奇數(shù)時(shí),,從兩塊RAM中所取數(shù)據(jù)與地址分別為:
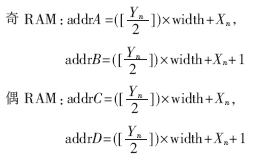

通過這種雙組奇偶雙口RAM緩存結(jié)構(gòu)的設(shè)計(jì)在不增加片內(nèi)存儲(chǔ)資源消耗的前提下一個(gè)時(shí)鐘周期內(nèi)取出四個(gè)數(shù)據(jù),,消除了空泡,實(shí)現(xiàn)了無等待流水線,,在一個(gè)時(shí)鐘周期內(nèi)可更新一個(gè)重建點(diǎn)的結(jié)果,。
單條反投影流水線設(shè)計(jì)原理如圖4所示,。圖中總體邏輯與時(shí)序控制模塊通過狀態(tài)機(jī)實(shí)現(xiàn)對(duì)流水線的控制,;緩存寫入控制單元對(duì)投影數(shù)據(jù)的寫入操作進(jìn)行判斷與控制;重建點(diǎn)生成器產(chǎn)生重建點(diǎn)坐標(biāo),,并根據(jù)此坐標(biāo)由讀地址生成器計(jì)算雙線性插值數(shù)據(jù)的地址,,同時(shí)通過查表找出空間系數(shù)sin?茲與cos?茲;循環(huán)累加控制器完成對(duì)各分度下反投影結(jié)果的歸約過程,。
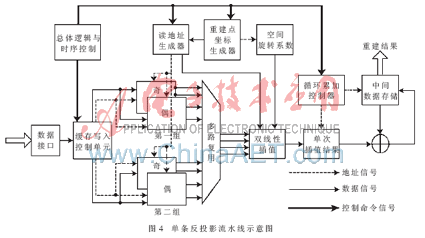
2.2 并行流水線處理結(jié)構(gòu)
基于各個(gè)分度下反投影過程的不相關(guān)性,,在FPGA內(nèi)設(shè)計(jì)一種基于分度的并行流水線處理結(jié)構(gòu),如圖5所示,。數(shù)據(jù)控制接口以及時(shí)序狀態(tài)控制模塊完成對(duì)輸入數(shù)據(jù)的分配調(diào)度,,通過多條反投影流水線并行計(jì)算后,由循環(huán)歸約單元完成反投影結(jié)果的歸約,。

假如投影分度數(shù)為360,,理想情況是在FPGA內(nèi)部實(shí)現(xiàn)360條并行的反投影流水線,,但由于FPGA片內(nèi)資源的限制無法達(dá)到如此高的并行性,因此需要對(duì)每一次并行計(jì)算結(jié)果進(jìn)行存儲(chǔ),,并完成累加計(jì)算,。設(shè)計(jì)循環(huán)歸約單元完成上述操作。當(dāng)有N條并行流水線并行計(jì)算
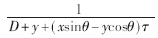
在FPGA內(nèi)設(shè)計(jì)時(shí),,預(yù)先算出該公因式的值,,然后通過移位寄存的方法進(jìn)行延遲同步,使之在相應(yīng)的節(jié)拍打入到指定的計(jì)算單元,。雖然這樣增加了乘法運(yùn)算,,但是將三次除法運(yùn)算優(yōu)化為一次,節(jié)省了大量的資源,。表1給出了優(yōu)化前后資源占有情況對(duì)比,。
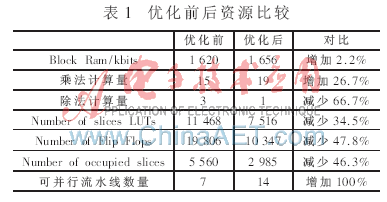
通過優(yōu)化,在XC5VLX330 FPGA內(nèi)部可以并行14條反投影流水線,,相比優(yōu)化以前,,流水線數(shù)增加1倍。
3 實(shí)驗(yàn)結(jié)果與分析
通過編寫Verilog語言程序,,在XC5VLX330 FPGA上進(jìn)行綜合仿真,,采取14條并行反投影流水線對(duì)Shepp-Logan標(biāo)準(zhǔn)體模進(jìn)行重建,得到圖6所示結(jié)果,。
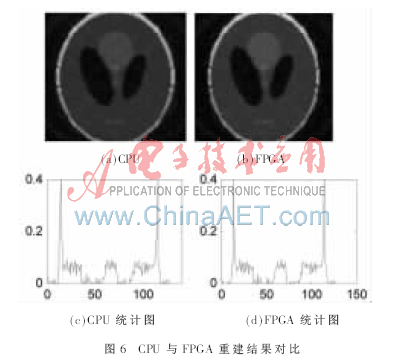
圖6(a)為CPU重建圖像的一個(gè)切片,,圖6(b)為FPGA加速重建的圖像切片,圖6(c),,圖6(d)分別為圖6(a),,圖6(b)切片圖像中心橫線的統(tǒng)計(jì)圖,從圖中可以看出FPGA加速重建結(jié)果的精度達(dá)到要求,。表2給出FPGA與CPU對(duì)不同規(guī)模數(shù)據(jù)進(jìn)行重建時(shí)速度對(duì)比,,計(jì)算機(jī)CPU為Inter Xeon E5430 2.66 GB,內(nèi)存為16 GB,。

可以看出,,通過FPGA加速FDK算法中的反投影過程加速比達(dá)到了115,具有顯著效果,。獲得加速比的原因由FPGA的體系結(jié)構(gòu)所決定,,其基于數(shù)據(jù)流的處理方式脫離了指令的操作,保證每一個(gè)時(shí)鐘周期都是用來計(jì)算,。當(dāng)采取多條流水線并行處理時(shí),,加速比進(jìn)一步提高,加速比與在FPGA內(nèi)并行流水線數(shù)目成正比,。
本文在FPGA上實(shí)現(xiàn)了對(duì)三維CT重建過程的加速,。針對(duì)FDK算法中計(jì)算復(fù)雜度最高的反投影過程,,通過雙組奇偶雙口RAM的緩存結(jié)構(gòu)實(shí)現(xiàn)了無等待流水線,達(dá)到每一個(gè)時(shí)鐘周期可更新一個(gè)重建點(diǎn)的速度,。另外通過優(yōu)化電路設(shè)計(jì)降低了單條流水線的資源占有率,,在XC5VLX330上實(shí)現(xiàn)了14條流水線的并行處理,在保證重建圖像質(zhì)量的同時(shí),,取得了115倍的加速比,。在利用FPGA實(shí)現(xiàn)CT重建加速時(shí),影響加速效果的主要因素是FPGA內(nèi)部資源利用率以及數(shù)據(jù)傳輸效率,,隨著未來FPGA以及存儲(chǔ)器技術(shù)的發(fā)展,,F(xiàn)PGA可以實(shí)現(xiàn)更快的CT重建速度。
參考文獻(xiàn)
[1] 包尚聯(lián).現(xiàn)代醫(yī)學(xué)影像物理學(xué)[M].北京:北京大學(xué)醫(yī)學(xué)出版社,,2003.
[2] 劉佳,,焦斌亮.FPGA的發(fā)展趨勢(shì)及其新應(yīng)用[J].電子技術(shù),2008(4).
[3] LEESER M.Parallel-beam backprojection:an FPGA implementation optimized for medical imaging[J].Proc of the Tenth Int.Symposium on FPGA.2002(2):217-226.
[4] GODDARD I.High-speed cone-beam reconstruction:an embedded systems approach[J].Proceedings of SPIE,,2003:483-491.
[5] Benno Heig.High-speed reconstruction for C-arm computed tomography[C].Proceedings of the 9th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine.2008:25-28.
[6] Nikhil Subramanian.A C-to-FPGA solution for accelerating tomographic reconstruction[D].University of Washington,,
2009.
[7] 張劍,陳志強(qiáng).三維錐形束CT成像FDK重建算法發(fā)展綜述[J].中國體視學(xué)與圖像分析,,2005(2):116-121.