
摘 要: 針對軟件無線電中自動調(diào)制模式識別在信噪比大范圍變化下的精度和速度問題,,提出了一種帶有參考訓練的分類識別結(jié)構(gòu),,通過構(gòu)造有效的三維特征矢量和加權擇多判決分類器,對BPSK,、QPSK,、FSK、PM,、MSK五類信號進行調(diào)制模式識別,。仿真結(jié)果驗證了該方法的可行性和有效性。
關鍵詞: 自動調(diào)制模式識別,;特征矢量,;加權擇多判決
軟件無線電技術已經(jīng)成為最近幾年通信界研究和開發(fā)的熱點。它的主要目的是建立一個通用平臺,,讓不同制式和傳輸速率的通信信號互聯(lián)互通,,實現(xiàn)資源的最優(yōu)利用。軟件無線電的通信體制決定了通信的接收方無法根據(jù)某一特定的解調(diào)方式,、在特定的頻段上進行解調(diào)解碼,。對這種多速率、多模式的寬帶信號進行解調(diào),,首先需要解決的問題就是如何自動識別接收信號的調(diào)制模式,,然后再分析對應該調(diào)制模式的各種調(diào)制參數(shù),如頻點,、帶寬,、波特率等。自動調(diào)制模式識別的實現(xiàn)對軟件無線電技術的發(fā)展起著重要作用,。
對于自動調(diào)制模式識別,,國內(nèi)外已取得不少研究成果[1-2]??偨Y(jié)起來,,識別方式大致分為兩類:基于判決理論的識別和基于統(tǒng)計理論的識別?;谂袥Q理論的識別方式依賴于先驗概率進行分類判決,;而基于統(tǒng)計理論的識別方式主要依靠特征提取和構(gòu)造合適的分類器進行識別。后者不需要假設條件,,易于進行盲識別和算法的高效實現(xiàn),,因而應用范圍更廣,。其中特征提取的研究初期僅限于對時頻特征的分析,隨著研究的深入,,逐漸引入了譜相關理論,、小波理論、矩理論,、循環(huán)累量和高階累量[3]進行調(diào)制特征的提取,。
而分類器的設計主要是線性分類器、非線性分類投影,、神經(jīng)網(wǎng)絡[4],、支持向量機等理論的應用。統(tǒng)計識別效果的好壞往往取決于特征提取,,并且正向著低預處理,、低復雜度、盲識別,、高識別精度的方向發(fā)展[5],。
本文針對低算法復雜度、較高識別精度,、較快識別速度的要求,,結(jié)合應用需要,從常用的五類調(diào)制信號(BPSK,、QPSK,、FSK、PM,、MSK)中有選擇性地提取三類特征構(gòu)成特征矢量,通過加權擇多判決進行分類[6],。在不同的信噪比下的仿真結(jié)果表明,,本文提出的方法能夠較好地分類識別這五類調(diào)制模式。
1 系統(tǒng)構(gòu)成
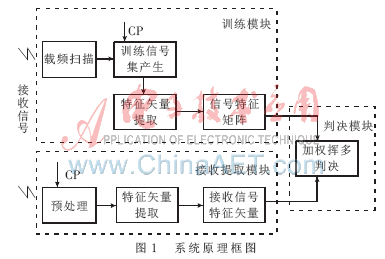
系統(tǒng)的原理框圖如圖1所示,,共包括三個模塊:訓練模塊,、接收提取模塊和判決模塊。訓練模塊主要負責掃描載頻,,以掃描得到的載頻為參量,,隨機產(chǎn)生五類幅度歸一化的調(diào)制信號,并對每類信號進行三維特征矢量提取,,構(gòu)成3×5大小的信號特征矩陣,,作為調(diào)制模式分類判決的依據(jù)。接收提取模塊將接收到的信號進行幅度歸一化的預處理,,特征提取后得到接收信號的三維特征矢量,。判決模塊主要負責結(jié)合信號特征矩陣,,對接收信號的特征矢量進行判決,判定識別接收到的信號的調(diào)制模式,。訓練模塊和接收提取模塊使用同步的系統(tǒng)時鐘CP,,以保證兩個模塊的采樣方式一致[7-8]。
2 特征矢量與加權擇多判決
2.1 三維特征矢量
基于統(tǒng)計理論的識別方式分為特征提取和分類判決兩個步驟,,提高其識別速度和精度的關鍵在于如何選取合適的分類特征,。一個合適的分類特征不但可以使分類器的設計變得簡單,還可以使分類識別的精度和速度大大提高,。
本設計在確定所選用的特征量之前,,先從時頻特征、矩特征和高階累量中選取了14種,,在不同信噪比下進行測試,,結(jié)合系統(tǒng)對識別速度的要求,最終選取了以下三類特征量作為分類特征,。其中Ns為采樣點數(shù),。
第一類特征量:

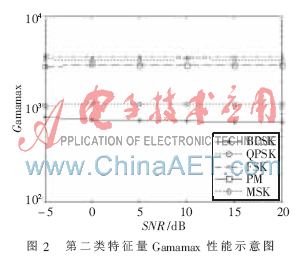
優(yōu)選的特征量能夠在信噪比一定的情況下,將不同的調(diào)制模式區(qū)別開來,。也就是說,,在一定的信噪比下,不同調(diào)制模式的信號的該項特征量的數(shù)值之間差異很大,,可以用來區(qū)別不同的調(diào)制模式,。比如第二類特征量Gamamax的性能如圖2所示,在每種信噪比下,,不同調(diào)制模式信號的Gamamax特征值都具有一定的區(qū)分度,,因而可以作為特征量被用來進行調(diào)制模式的分類識別。
三類特征量進行組合,,便可得到三維特征矢量[Fmd,,Gamamax,Aad],。訓練模塊在不同信噪比的情況下實時訓練,,產(chǎn)生相應的3×5信號特征矩陣。而接收提取模塊直接從預處理后的信號中提取出三維特征矢量,,直接送到判決模塊中進行分類,。
2.2 加權擇多判決
由上述分析可知,通過單維特征就可以對接收信號進行調(diào)制模式分類,,但信源信號經(jīng)過信道衰落和疊加上信道噪聲以后,,會在幅頻特性和相頻特性上產(chǎn)生很大的起伏和抖動。所以為了在較大信噪比范圍內(nèi)獲得更高的分類精度,,有必要采用多維特征矢量,。同時,,為了盡量提高系統(tǒng)分類的速度,僅篩選出以上三類特征量組成三維特征矢量,。
常用的矢量分類器有線性分類器,、神經(jīng)網(wǎng)絡和支持向量機等。本系統(tǒng)基于提高分類實時性的考慮,,采用了一種加權擇多判決的方法,,其原理如下。


(2)執(zhí)行x1=(varmax-var(f1x)),、y1=(varmax-var(f2y)),、z1=(varmax-var(f3z)),完成權重的計算過程,。其中varmax是F中所有元素方差的最大值,,var(f1x)是元素f1x的方差。則x1越大,,說明f1x的方差越小,,誤判的概率也就越小。
(3)擇多判決,。如果x(y,、z)等于i,則將x1(y1,、z1)累加到Sum(i)中,,i=1,2,,3,。Sum中最大值的下標即為分類判決的最后輸出結(jié)果;數(shù)值1~5,,分別代表BPSK,、QPSK、FSK,、PM和MSK這五類調(diào)制模式。
這種加權擇多判決分類方法只涉及到復雜度較低的加減運算和查找運算,,求方差的運算也可以采用遞推的方式進行,,而沒有擬合函數(shù)、核函數(shù)參數(shù)的求解過程,。所以在運行速度上具有一定的優(yōu)勢,。
3 仿真結(jié)果與性能分析
本系統(tǒng)的實驗仿真平臺采用了Lyrtech公司提供的LSP研發(fā)工具。LSP快速原型開發(fā)平臺集成了MATLAB/Simulink軟件仿真環(huán)境和DSP+FPGA的快速原型開發(fā)板,,硬件資源豐富,、結(jié)構(gòu)靈活,,有較強的通用性,適用于模塊化設計,,從而能夠提高算法效率,。同時,其開發(fā)周期較短,,系統(tǒng)易于維護和擴展,,為用戶提供了一個從軟件仿真到硬件測試的系統(tǒng)級開發(fā)流程。仿真過程中,,調(diào)制模式識別主要針對BPSK,、QPSK、FSK,、PM和MSK這五類,。
信號產(chǎn)生部分的參數(shù)設定為:采樣頻率統(tǒng)一為fs=1 000 Hz,采樣點數(shù)統(tǒng)一為NS=50 000,,載頻fc=100 Hz(BPSK,、QPSK、PM)或為400 Hz(MSK),,F(xiàn)SK的兩個載頻分別設為100 Hz和50 Hz,。噪聲設定為高斯白噪聲。信噪比分為-5 dB,、0 dB,、5 dB、10 dB,、15 dB,、20 dB六種情況,進行特征提取和分類識別算法的仿真,。為避免單次分類的個體誤差,,整個仿真過程采用蒙特卡羅仿真,每類調(diào)制模式在每種信噪比下的特征提取和加權擇多分類判決都進行了5 000次仿真實驗,,測試結(jié)果如表1和圖3所示,。
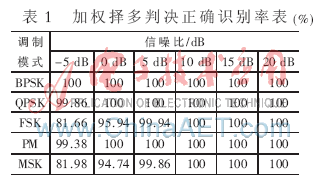
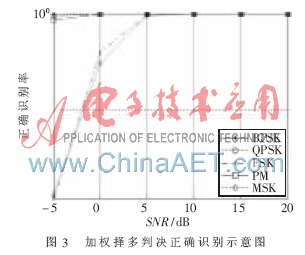
由表1和圖3可以看出,采用Fmd特征量,、Gamamax特征量和Aad特征量組成的三維特征矢量及加權擇多判決分類方法,,對BPSK、QPSK,、FSK,、PM、MSK五類調(diào)制模式進行識別,,在-5 dB低信噪比的情況下,,有一定的誤判率,;當信噪比超過0 dB以后,正確識別概率在94%以上,,基本能滿足對識別精度的要求,。
整個系統(tǒng)的計算過程主要由特征提取和加權擇多判決兩部分構(gòu)成。如果計算長度為N,,則特征提取部分Fmd特征量計算的復雜度為O(N×logN),,Gamamax特征量計算的復雜度也為O(N×logN),Aad特征量計算的復雜度為O(N),;所以訓練模塊和特征提取模塊的總計算復雜度為O(N×logN),。加權擇多判決部分的計算復雜度為O(3×5),也就是為O(1),。因此系統(tǒng)總的計算復雜度為O(N×logN),。為了提高運算速度可以考慮降低N,但N過小則會影響特征矢量計算的準確性,,所以在N保持一個適當?shù)闹禃r,,系統(tǒng)的實時性可以得到保證。
本文針對軟件無線電中的自動調(diào)制模式識別中的精度和速度問題,,提出了一種帶有參考訓練的分類識別結(jié)構(gòu),,有選擇性地設計了一種三維特征矢量和加權擇多判決分類識別方法,以提高調(diào)制模式識別的準確性和實時性,。對BPSK,、QPSK、FSK,、PM,、MSK五類信號在大動態(tài)信噪比范圍內(nèi)的仿真,結(jié)果驗證了該系統(tǒng)的有效性,。對系統(tǒng)計算復雜度的分析說明了提高計算速度的方法和原則,。但仍需在低預處理、低復雜度和盲識別方面進一步研究,、改進,。
參考文獻
[1] DOBRE O A, ABDI A,, BAR-NESS Y,, et al. Survey of automatic modulation classification techniques: classical approaches and new trends[J]. Communications, IET,, 2007(2):137-156.
[2] 肖為民,,許希武.軟件無線電綜述.電子學報[J].1998,,26(2):65-70.
[3] CHEN Ji Li,, CHEN He Jie. Automatic digital modulation identification basing on decision method and cumulants[C]. Proceedings of 2005 IEEE International Workshop on VLSI Design and Video Technology,, 2005. 2005:264-267.
[4] PARK Cheol-Sun, KIM Dae Young. A novel robust feature of modulation classification for reconfigurable software radio[J]. IEEE Transactions on Consumer Electronics,, 2006,,52(4):1193-1200.
[5] HOSOYA H, KAMISAWA T,, KURODA M,, et al. Automatic modulation identification for linear digital modulation[C]. 14th IEEE Proceedings on Personal, Indoor and Mobile Radio Communications,, 2003. PIMRC 2003. 2003:1810-1814.
[6] CHEN Qi Xing,, ZHOU Guo Zhong. Demodulation-oriented automatic modulation identification algorithm[C]. 4th International Conference on Wireless Communications, Networking and Mobile Computing,, 2008. WiCOM’08. 2008:1-5.
[7] 韓國棟,,鄔江興.調(diào)制參數(shù)提取的譜相關方法[J].航天電子對抗,2001(3):34-36.
[8] 李琳,,張爾揚.軟件無線電中的關鍵技術[J].通信電聲,,1999(3):52-54.