
本文提出了一種面向?qū)ΨQ體系結(jié)構(gòu)的FPGA仿真模型,該模型的核心設(shè)計(jì)思想是:分時(shí)復(fù)用仿真系統(tǒng)中的一個(gè)單元來仿真目標(biāo)系統(tǒng)中多個(gè)對(duì)稱單元的行為,,從而利用較少的硬件資源完成系統(tǒng)仿真,,提高FPGA的利用率。
1 對(duì)稱多核體系結(jié)構(gòu)FPGA仿真模型
對(duì)稱多核如SMP(Symmetry Multi-Processor)體系結(jié)構(gòu)中,,通常包含多個(gè)對(duì)稱的處理器核或計(jì)算核心,,這里統(tǒng)稱為計(jì)算核。計(jì)算核占據(jù)了多核體系結(jié)構(gòu)的主要硬件開銷,,且對(duì)稱多核體系結(jié)構(gòu)的硬件仿真平臺(tái)FPGA資源消耗隨計(jì)算核數(shù)目成線性增加,。這里提出的對(duì)稱多核體系結(jié)構(gòu)FPGA仿真模型,解耦合計(jì)算核數(shù)目與系統(tǒng)硬件開銷的線性關(guān)系,,其核心設(shè)計(jì)思想是:在構(gòu)建仿真系統(tǒng)時(shí),,使用一個(gè)與目標(biāo)系統(tǒng)中單個(gè)計(jì)算核等同的處理單元,稱為虛擬計(jì)算單元VAU(Virtual Arithmetic Unit)代替所有的對(duì)稱計(jì)算核,,通過分時(shí)復(fù)用VAU實(shí)現(xiàn)一個(gè)計(jì)算單元虛擬多個(gè)計(jì)算核的行為,。
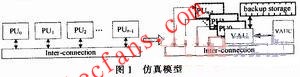
圖l中的左圖是當(dāng)前具有對(duì)稱結(jié)構(gòu)的多核體系結(jié)構(gòu)模型抽象,,n個(gè)對(duì)稱的計(jì)算核通過特定的互連結(jié)構(gòu)連接,其連接關(guān)系由目標(biāo)處理器的工作模式?jīng)Q定;右圖是本文提出的仿真模型,??梢钥闯觯抡嫦到y(tǒng)中采用一個(gè)VAU代替了目標(biāo)系統(tǒng)中所有對(duì)稱的處理單元PU,。在對(duì)目標(biāo)系統(tǒng)進(jìn)行仿真時(shí),,計(jì)算頁(yè)控制器VAUC(VAU Controller)控制1個(gè)VAU分時(shí)復(fù)用的方式工作,虛擬多個(gè)PU并行執(zhí)行,。分時(shí)的粒度與處理單元之間的耦合度相關(guān),。虛擬計(jì)算單元將目標(biāo)系統(tǒng)中并行執(zhí)行模式轉(zhuǎn)變?yōu)榇袌?zhí)行的方式進(jìn)行仿真,以時(shí)間換取空間,,減少系統(tǒng)中計(jì)算資源的消耗,。BS(Backup Storage)用于存儲(chǔ)VAU虛擬各PU執(zhí)行時(shí)的中間結(jié)果,。
2 仿真系統(tǒng)執(zhí)行模式
2.1 多核/眾核體系結(jié)構(gòu)仿真系統(tǒng)執(zhí)行模式
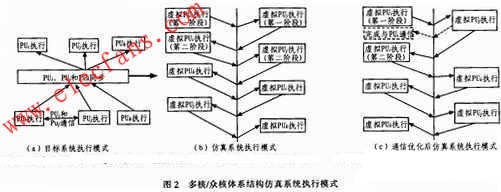
對(duì)稱多核處理器中處理單元之間的耦合度不同,,使得對(duì)應(yīng)的仿真系統(tǒng)的執(zhí)行模式也不一樣。多核/眾核體系結(jié)構(gòu)通常采用粗粒度耦合執(zhí)行的方式,。如圖2(a)所示.多個(gè)處理單元之間相互比較獨(dú)立,,其同步和通信通常處于任務(wù)級(jí),即多個(gè)處理單元間的通信和同步的次數(shù)遠(yuǎn)小于它們執(zhí)行的指令數(shù),。圖中PUi和PUj之間有一次通信,,PUi、PUj和PUk之間有一次同步,。對(duì)應(yīng)的仿真系統(tǒng)的執(zhí)行模式如圖2(b)所示,,VAU先對(duì)PUi進(jìn)行仿真,執(zhí)行到與通信點(diǎn)時(shí),,將PUi的執(zhí)行信息導(dǎo)入BS,,然后VAU對(duì)PUi進(jìn)行仿真,執(zhí)行到與通信點(diǎn)時(shí),,將PUj的執(zhí)行信息導(dǎo)入BS,,將PUi的執(zhí)行信息由BS導(dǎo)入VMU,對(duì)PUi的后續(xù)行為進(jìn)行仿真,,以此類推,,如圖2所示,箭頭每穿過中線一次,,表示計(jì)算頁(yè)切換一次仿真對(duì)象,,指向下的箭頭表示VMU的信息導(dǎo)入BS,指向上的箭頭表示BS中的信息導(dǎo)出至VMU,。為了減少現(xiàn)場(chǎng)切換的次數(shù),,對(duì)兩個(gè)PU通信時(shí)的執(zhí)行過程進(jìn)行優(yōu)化,,如圖2(c)所示,VAU仿真PUi執(zhí)行至通信點(diǎn)時(shí),,切換至PUj進(jìn)行仿真,,只有在PUj遇到其他同步或通信時(shí),才進(jìn)行現(xiàn)場(chǎng)切換,,否則VAU一直對(duì)PUj進(jìn)行仿真,,直至PUj執(zhí)行結(jié)束。PUj執(zhí)行到與通信點(diǎn)時(shí),,PUj將通信數(shù)據(jù)發(fā)送至網(wǎng)絡(luò)緩沖,,并寫入PUi對(duì)應(yīng)的存儲(chǔ)空間,如圖2(c)中虛線所示,。
2.2 SIMD體系結(jié)構(gòu)仿真系統(tǒng)執(zhí)行模式
SIMD體系結(jié)構(gòu)的處理單元之間是緊密耦合的,,所有處理單元的執(zhí)行過程都是嚴(yán)格同步的,即同一時(shí)鐘周期內(nèi)每個(gè)處理單元都對(duì)不同的數(shù)據(jù)進(jìn)行完全同樣的操作,,如圖3(a)所示,。

在SIMD體系結(jié)構(gòu)仿真系統(tǒng)中,必須在邏輯上保持這種完全同步的執(zhí)行模式,。本文采用的方式是,,一條指令流出之后,讓它在指令流水線中保持n個(gè)時(shí)鐘周期(可以在連續(xù)的n個(gè)時(shí)鐘內(nèi)都發(fā)射同一條指令),,VAU在這n個(gè)周期內(nèi)分別對(duì)各處理單元對(duì)應(yīng)的數(shù)據(jù)進(jìn)行處理,。若將n個(gè)時(shí)鐘周期看作系統(tǒng)的工作周期,則n個(gè)數(shù)據(jù)是在同一工作周期內(nèi)被處理,,如圖3(b)所示,。這樣則在邏輯上保持SIMD的執(zhí)行模式。
3 仿真系統(tǒng)評(píng)估
本文的目標(biāo)系統(tǒng)如圖4(a)所示,。它由多個(gè)計(jì)算節(jié)點(diǎn)以Torus片上網(wǎng)絡(luò)連接構(gòu)成,,其計(jì)算節(jié)點(diǎn)數(shù)目可以根據(jù)應(yīng)用需求進(jìn)行擴(kuò)展。對(duì)應(yīng)的仿真系統(tǒng)如圖4(b)所示,。在仿真系統(tǒng)中,,采用一個(gè)虛擬計(jì)算節(jié)點(diǎn)(VAU)代替目標(biāo)系統(tǒng)中的p個(gè)計(jì)算節(jié)點(diǎn),圖4(b)以p=4為例,,展示了仿真系統(tǒng)的結(jié)構(gòu),。目標(biāo)系統(tǒng)中p個(gè)計(jì)算節(jié)點(diǎn)的計(jì)算操作都由VAU以圖2的工作模式完成。VAU中包含一個(gè)現(xiàn)場(chǎng)保存存儲(chǔ)器(context backup),,用于保存目標(biāo)系統(tǒng)中p個(gè)計(jì)算節(jié)點(diǎn)的中間結(jié)果,。contextbackup的容量為每個(gè)計(jì)算節(jié)點(diǎn)中本地存儲(chǔ)器容量的p倍,這樣,context backup就有足夠的能力存儲(chǔ)p個(gè)計(jì)算節(jié)點(diǎn)的中間結(jié)果,,從而減少與外部存儲(chǔ)器的數(shù)據(jù)交換,,減少VAU的停頓時(shí)間。
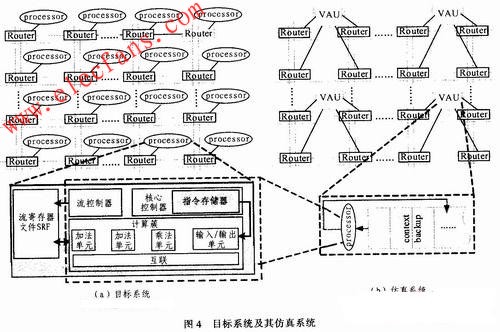
采用FPGA EP2S180(擁有143 520 ALUT,,相當(dāng)于18萬(wàn)邏輯門)實(shí)現(xiàn)了多種結(jié)構(gòu)(計(jì)算節(jié)點(diǎn)的數(shù)目不同)的目標(biāo)系統(tǒng)和基于仿真模型的仿真系統(tǒng),,并利用相應(yīng)的硬件綜合工具Quartus分析仿真系統(tǒng)的FPGA資源開銷。系統(tǒng)采用包含1個(gè)cluster的MASA流處理器作為計(jì)算節(jié)點(diǎn),。為更好地驗(yàn)證仿真模型,,流處理器中采用功能裁剪的cluster,如圖4所示,,cluster中僅包含3個(gè)計(jì)算單元和1個(gè)I/O單元,,并相應(yīng)降低指令和數(shù)據(jù)存儲(chǔ)器的容量。在仿真系統(tǒng)中,,VAU中的processor為流處理器中的核心計(jì)算部件,,context backup代替了片上存儲(chǔ)部件,其容量為SRF的p倍,。該實(shí)驗(yàn)的目的是分析所提出的仿真模型對(duì)仿真系統(tǒng)的硬件資源消耗和仿真速度的影響,。
3.1 資源消耗分析
圖5是目標(biāo)系統(tǒng)和仿真系統(tǒng)的FPGA資源消耗統(tǒng)計(jì)。由于布局布線的需求,,F(xiàn)PGA芯片的資源使用率最高通常只能達(dá)到70%~80%,。圖5中“×”標(biāo)識(shí)表示當(dāng)前配置超出EP2S180的仿真能力??梢钥闯觯诓徊捎梅抡鎯?yōu)化技術(shù)時(shí),,EP2S180可仿真的最大規(guī)模目標(biāo)系統(tǒng)為24個(gè)計(jì)算節(jié)點(diǎn),。基于本文的仿真模型,,當(dāng)p值等于4時(shí),,EP2S180的仿真能力提高至64個(gè)節(jié)點(diǎn);當(dāng)p值等于8時(shí),其仿真能力提高至96個(gè)節(jié)點(diǎn),。當(dāng)p值增大時(shí),,其仿真能力可進(jìn)一步提升。實(shí)驗(yàn)結(jié)果表明,,本文提出的仿真模型能夠增大FPGA芯片可仿真系統(tǒng)的規(guī)模,。

3.2 仿真速度分析
本文采用矩陣乘運(yùn)算,分別在8,、16,、32個(gè)節(jié)點(diǎn)的目標(biāo)系統(tǒng)和仿真系統(tǒng)上執(zhí)行,測(cè)試二者的仿真速度。目標(biāo)系統(tǒng)和仿真系統(tǒng)的工作頻率為75 MHz,。圖6展示了二者的執(zhí)行時(shí)間,。
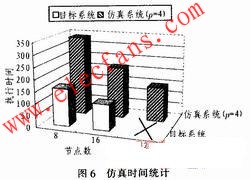
可以看出,仿真系統(tǒng)的執(zhí)行時(shí)間大于目標(biāo)系統(tǒng),。其時(shí)間增量主要是由于仿真系統(tǒng)將目標(biāo)系統(tǒng)中多個(gè)processor并行處理的任務(wù)移植到一個(gè)VAU上串行執(zhí)行造成,。仿真系統(tǒng)沒有改變目標(biāo)系統(tǒng)的數(shù)據(jù)傳輸路徑和模式,因此,,數(shù)據(jù)傳輸?shù)臅r(shí)間并沒有增加,。另外,由于VAU虛擬的p個(gè)pro-cessor共享了存儲(chǔ)空間,,仿真系統(tǒng)中消除了p個(gè)processor之間的數(shù)據(jù)傳輸時(shí)間,。雖然仿真系統(tǒng)相對(duì)于目標(biāo)系統(tǒng)執(zhí)行時(shí)間有所增加,但其時(shí)間增量處于秒級(jí),。相對(duì)于緩慢的軟件模擬器,,并綜合考慮仿真模型對(duì)FPGA仿真規(guī)模帶來的好處,因此認(rèn)為該仿真模型帶來的仿真時(shí)間增量是可以接受的,。
4 結(jié)束語(yǔ)
本文提出了面向?qū)ΨQ多核體系結(jié)構(gòu)的FPGA仿真模型,,以及基于該模型的多核/眾核、SIMD體系結(jié)構(gòu)的執(zhí)行模式,。相對(duì)于軟硬件聯(lián)合仿真方法,,該仿真模型減少了軟硬件協(xié)同邏輯并避免了設(shè)計(jì)復(fù)雜的軟件劃分算法。實(shí)驗(yàn)結(jié)果表明,,面向?qū)ΨQ多核體系結(jié)構(gòu)的FPGA仿真模型能有效地減少仿真系統(tǒng)FPGA資源的需求,,增大FPGA的仿真規(guī)模,并且其帶來的仿真時(shí)間增量是可接受的,。但該仿真模型主要是面向?qū)ΨQ體系結(jié)構(gòu),,而不適用于異構(gòu)多核系統(tǒng)等非對(duì)稱結(jié)構(gòu)。