
摘 要: 闡述了我國(guó)擁有自主知識(shí)產(chǎn)權(quán)的音視頻編碼技術(shù)標(biāo)準(zhǔn)——AVS標(biāo)準(zhǔn)的熵解碼算法,介紹了基于AVS標(biāo)準(zhǔn)的熵解碼器的設(shè)計(jì)。根據(jù)碼流的特點(diǎn)劃分硬件模塊,采用筒形移位器結(jié)構(gòu)提高解碼并行性,應(yīng)用Verilog硬件描述語(yǔ)言、EDA軟件ModelSim仿真、QuartusII軟件綜合,并通過(guò)了Altera公司的Cyclone系列FPGA芯片的下載驗(yàn)證,證明該設(shè)計(jì)能夠?qū)崿F(xiàn)AVS碼流的實(shí)時(shí)解碼功能。
關(guān)鍵詞: AVS;熵解碼;可編程邏輯門(mén)陣列;Verilog 硬件描述語(yǔ)言
AVS標(biāo)準(zhǔn)是《信息技術(shù) 先進(jìn)音視頻編碼》系列標(biāo)準(zhǔn)的簡(jiǎn)稱,是我國(guó)具備自主知識(shí)產(chǎn)權(quán)的第二代信源編碼標(biāo)準(zhǔn)。AVS標(biāo)準(zhǔn)包括系統(tǒng)、視頻、音頻、數(shù)字版權(quán)管理等四個(gè)主要技術(shù)標(biāo)準(zhǔn)和一致性測(cè)試等支撐標(biāo)準(zhǔn)。
目前音視頻產(chǎn)業(yè)可以選擇的信源編碼標(biāo)準(zhǔn)有四個(gè):MPEG-2、MPEG-4、AVC(也稱JVT、H.264)和AVS。從制訂者分,前三個(gè)標(biāo)準(zhǔn)是由MPEG專家組完成的,第四個(gè)是我國(guó)自主制定的。從發(fā)展階段分,MPEG-2是第一代信源標(biāo)準(zhǔn),其余三個(gè)為第二代標(biāo)準(zhǔn)。從主要技術(shù)指標(biāo)——編碼效率比較,MPEG-4是MPEG-2的1.4倍,AVS和AVC相當(dāng),都是MPEG-2的兩倍以上。
AVC標(biāo)準(zhǔn)中,對(duì)預(yù)測(cè)殘差有兩種熵編碼的方式:基于上下文的自適應(yīng)變長(zhǎng)碼(CAVLC)和基于上下文的自適應(yīng)二進(jìn)制算數(shù)編碼(CABAC);對(duì)于非預(yù)測(cè)殘差,采用指數(shù)哥倫布碼或CABAC編碼,視編碼器的設(shè)置而定[1]。
AVS標(biāo)準(zhǔn)所用的熵編碼技術(shù)相比于以前有了很多改進(jìn),它的語(yǔ)法元素和殘差系數(shù)是由定長(zhǎng)碼和指數(shù)哥倫布碼構(gòu)成的,其中指數(shù)哥倫布碼和語(yǔ)法元素之間存在多種映射關(guān)系。
1 AVS標(biāo)準(zhǔn)熵解碼算法描述
在整個(gè)AVS視頻的解碼過(guò)程中,熵解碼模塊位于系統(tǒng)的最前端,負(fù)責(zé)從壓縮后的碼流中解析出宏塊頭信息以及量化系數(shù),供后續(xù)的幀內(nèi)預(yù)測(cè)模塊和幀間預(yù)測(cè)模塊使用。而熵解碼模塊又可以大體分為兩個(gè)部分:解析K階指數(shù)哥倫布碼部分和解析語(yǔ)法元素部分。
解析K階指數(shù)哥倫布碼時(shí),首先從比特流的當(dāng)前位置開(kāi)始尋找第一個(gè)非零比特,并將找到的零比特個(gè)數(shù)記為leadingZeroBits,然后根據(jù)leadingZeroBits計(jì)算CodeNum。用偽代碼描述如下:
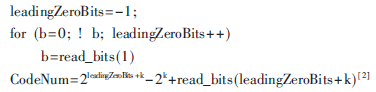
由于AVS視頻中所有的語(yǔ)法元素以及經(jīng)過(guò)變換和量化的殘差系數(shù)都是以指數(shù)哥倫布碼的形式映射成二進(jìn)制碼流的,因此在解析出K階指數(shù)哥倫布碼的CodeNum后,下一步就是要還原出各種語(yǔ)法元素和殘差系數(shù)。
在AVS標(biāo)準(zhǔn)中規(guī)定了四種映射方式:ue(v)、se(v)、me(v)和ce(v)。其中ue(v)、se(v)和me(v)所描述的語(yǔ)法元素采用0階的指數(shù)哥倫布碼,ce(v)用來(lái)描述殘差系數(shù),可以采用0階、1階、2階或者3階指數(shù)哥倫布碼。它們的解析過(guò)程如下:
ue(v):無(wú)符號(hào)直接映射,語(yǔ)法元素的值等于CodeNum;
se(v):有符號(hào)映射,映射關(guān)系為:當(dāng)CodeNum=k時(shí),語(yǔ)法元素值為(-1)k+1×Ceil(k÷2)
me(v):分為MbCBP和MbCBP422兩種模式,分別根據(jù)CodeNum的值,查找相對(duì)應(yīng)的表來(lái)得到語(yǔ)法元素的值。
ce(v):ce(v)描述的語(yǔ)法元素可以采用0階、1階、2階或3階指數(shù)哥倫布碼進(jìn)行解析,還有19個(gè)相關(guān)的碼表,對(duì)于階數(shù)的確定規(guī)則以及碼表的切換規(guī)則,在AVS標(biāo)準(zhǔn)中都有詳細(xì)的說(shuō)明。解析時(shí),首先語(yǔ)法元素trans_coefficient等于CodeNum,如果trans_coefficient小于59,可以根據(jù)trans_coefficient的值查找相關(guān)的碼表得到殘差系數(shù);如果trans_coefficient大于等于59,解析下一個(gè)ce(v)語(yǔ)法元素,得到一個(gè)新的CodeNum,escape_level_diff等于CodeNum,然后根據(jù)trans_coefficient和escape_level_diff求得殘差系數(shù)[3]。
2 熵解碼器的硬件設(shè)計(jì)
由于熵解碼器位于整個(gè)解碼結(jié)構(gòu)的最前端,所有后續(xù)模塊中需要用到的數(shù)據(jù)都是熵解碼模塊從原始碼流中解析出來(lái)的,因此熵解碼器性能的優(yōu)劣直接影響到整個(gè)AVS視頻解碼器的性能。
從前面的介紹中可以了解到,經(jīng)過(guò)指數(shù)哥倫布編碼后形成的碼流中,每個(gè)碼的碼長(zhǎng)不固定,而且前后具有很大的相關(guān)性,這樣在解碼時(shí)就必須逐位讀取數(shù)據(jù),解析完一個(gè)碼字后才能解析下一個(gè)碼字。這種串行解碼的方式嚴(yán)重限制了熵解碼器的性能,所以需要找到一種能夠并行解碼的方式。這里的并行解碼并不是指同時(shí)對(duì)好幾個(gè)碼進(jìn)行解碼,而是針對(duì)一個(gè)變長(zhǎng)碼的多個(gè)位來(lái)說(shuō)的。具體來(lái)說(shuō)就是一次讀入N位數(shù)據(jù),通過(guò)比較操作,得到碼長(zhǎng),使得解碼可以在確定的時(shí)間長(zhǎng)度內(nèi)進(jìn)行,而不是隨著碼長(zhǎng)的不同而變化。顯然,這將提高硬件的復(fù)雜度,但是換來(lái)了解碼速度的提高[4]。
整個(gè)熵解碼器可以分為四個(gè)模塊:數(shù)據(jù)準(zhǔn)備模塊、解指數(shù)哥倫布碼模塊、語(yǔ)法元素解析模塊和解碼控制模塊。硬件結(jié)構(gòu)如圖1所示。

下面通過(guò)分析碼流數(shù)據(jù)的解析過(guò)程來(lái)逐個(gè)說(shuō)明各個(gè)模塊的功能和實(shí)現(xiàn)。
2.1 數(shù)據(jù)準(zhǔn)備模塊
這個(gè)模塊的功能是為后邊的解指數(shù)哥倫布碼模塊準(zhǔn)備好未解碼數(shù)據(jù),要求解指數(shù)哥倫布碼模塊解完一個(gè)碼,數(shù)據(jù)準(zhǔn)備模塊就要在碼流中將解完的碼移走,并準(zhǔn)備好下一個(gè)要解的碼字送給下一模塊。硬件結(jié)構(gòu)如圖2所示。
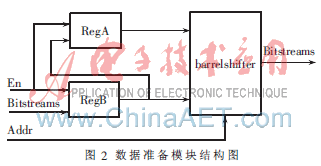
RegA和RegB是兩個(gè)32位的寄存器,其中RegB直接從未解碼碼流中讀取數(shù)據(jù),RegA則接收RegB中的數(shù)據(jù),兩個(gè)寄存器共同組成barrelshifter的輸入。
barrelshifter是一個(gè)64位輸入、32位輸出的暫存器,每次輸出都將剛解完的一個(gè)碼字移出,以保證輸出的32位數(shù)據(jù)中最低位為下一個(gè)要解碼的碼字的開(kāi)始。移位的位數(shù)由輸入的地址Addr來(lái)決定,即輸出64位輸入的[Addr,Addr+31]位。
當(dāng)En信號(hào)有效時(shí),更新數(shù)據(jù),將RegB中的數(shù)據(jù)存到RegA中,再?gòu)拇a流中讀取新的32位數(shù)據(jù),存到RegB中。其中Addr和En信號(hào)由解指數(shù)哥倫布碼模塊給出。
2.2解指數(shù)哥倫布碼模塊
這個(gè)模塊的功能是接收上一模塊準(zhǔn)備好的未解碼數(shù)據(jù),計(jì)算出從最低位開(kāi)始的一個(gè)指數(shù)哥倫布碼的CodeNum,并根據(jù)這個(gè)碼的碼長(zhǎng)算出筒形移位器的移位地址。模塊結(jié)構(gòu)如圖3所示。

由于上一個(gè)模塊準(zhǔn)備好的未解碼碼流是一個(gè)以新的指數(shù)哥倫布碼的開(kāi)始為最低位的32位碼流,因此要計(jì)算出這個(gè)碼的CodeNum,首先要算出這個(gè)碼的碼長(zhǎng),然后在這32位數(shù)據(jù)中截取出這個(gè)碼字,才可以計(jì)算它的CodeNum。根據(jù)指數(shù)哥倫布碼的結(jié)構(gòu),碼長(zhǎng)與這個(gè)碼的前導(dǎo)零個(gè)數(shù)M和階數(shù)K有密切關(guān)系,可以總結(jié)出一個(gè)公式:CodeL=2×M+K+1。碼長(zhǎng)計(jì)算模塊就是根據(jù)這個(gè)原理來(lái)計(jì)算碼長(zhǎng)的,首先通過(guò)一組比較器檢測(cè)從最低位開(kāi)始有幾個(gè)零,然后根據(jù)上述公式得到碼長(zhǎng)。對(duì)于階數(shù)K,解ue(v)、me(v)和se(v)語(yǔ)法元素時(shí),階數(shù)K為0。解ce(v)時(shí),當(dāng)前解碼碼字的階數(shù)在解碼上一個(gè)碼字時(shí)可以得出。
累加器模塊是一個(gè)模為32的加法器,將碼長(zhǎng)計(jì)算模塊計(jì)算出來(lái)的碼長(zhǎng)CodeL累加到上一次的移位地址上,得到一個(gè)新的移位地址,筒形移位器根據(jù)這個(gè)新的地址,將本次解碼的碼字移出,準(zhǔn)備好下一個(gè)未解碼碼流。En為進(jìn)位輸出,當(dāng)累加器的En為1時(shí),說(shuō)明已經(jīng)解完了32位數(shù)據(jù),這時(shí)需要對(duì)RegA和RegB進(jìn)行數(shù)據(jù)更新。
計(jì)算碼字的CodeNum時(shí),首先根據(jù)碼長(zhǎng)計(jì)算模塊算出來(lái)的碼字長(zhǎng)度,從上一模塊準(zhǔn)備好的未解碼碼流中把本次要解碼的碼字截取出來(lái),拋棄無(wú)用的位,然后再根據(jù)公式CodeNum=2leadingZeroBits+k-2k+read_bits(leadingZeroBits+k)計(jì)算這個(gè)碼字的CodeNum。顯然這個(gè)公式太過(guò)復(fù)雜,不適合直接硬件化,但是經(jīng)過(guò)分析公式以及指數(shù)哥倫布碼的結(jié)構(gòu),可以改造一下公式。因?yàn)橹笖?shù)哥倫布碼的結(jié)構(gòu)為前面M個(gè)前導(dǎo)0,中間一個(gè)1,后面M+K位數(shù)據(jù)組成,而read_bits(leadingZeroBits+k)即為后面M+K位數(shù)據(jù)的碼字值,2leadingZeroBits+k正好為中間那個(gè)1的碼字值,所以一個(gè)碼字的CodeNum就等于這個(gè)碼字的碼字值減去2k,這樣對(duì)CodeNum的計(jì)算就大大簡(jiǎn)化了。
2.3 語(yǔ)法元素解析模塊
顧名思義,這個(gè)模塊就是最終解析出語(yǔ)法元素含義的模塊,它接收上一模塊計(jì)算出來(lái)的CodeNum值,然后主要通過(guò)查表的方式解析出這個(gè)碼字所代表的語(yǔ)法元素含義,結(jié)構(gòu)如圖 4所示。
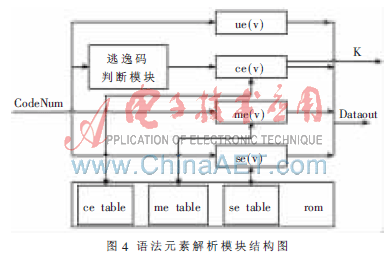
這里主要介紹下最復(fù)雜的ce(v)部分的解析過(guò)程。
逃逸碼判斷模塊:在解析ce(v)語(yǔ)法元素時(shí),首先要判斷是否為逃逸碼,即CodeNum<59時(shí),按照正常ce(v)語(yǔ)法元素解析規(guī)則解析;CodeNum≥59時(shí),下一碼字為逃逸碼,則按照逃逸碼解析規(guī)則解析。
ce(v)語(yǔ)法元素解析模塊:正常ce(v)語(yǔ)法元素的解析過(guò)程為:以CodeNum的值為索引,查找當(dāng)前碼表,得到(run、level),然后根據(jù)標(biāo)準(zhǔn)中的碼表切換規(guī)則進(jìn)行碼表切換,并得到下一碼字的階數(shù)K。解析逃逸碼的解析過(guò)程為:令transcoefficient等于CodeNum,得到run=(transcoefficient-59)/2。以當(dāng)前碼表為索引,查表得到對(duì)應(yīng)的MaxRun,如果run>MaxRun,則RefAbslevel=1,否則以run為索引查當(dāng)前碼表,得到RefAbslevel。解析下一個(gè)語(yǔ)法元素,得到一個(gè)新的Codenum,escape_level_diff等于CodeNum。如果transcoefficient為奇數(shù),則level等于-(RefAbslevel+escape_level_diff);如果transcoefficient為偶數(shù),則level等于(RefAbslevel+escape_level_diff)。最后再按照標(biāo)準(zhǔn)中的碼表切換規(guī)則進(jìn)行碼表切換,等待解析下一個(gè)語(yǔ)法元素。
3 測(cè)試與驗(yàn)證
將本文提出的熵解碼器結(jié)構(gòu)設(shè)計(jì)用Verilog HDL實(shí)現(xiàn),用ModelSim在綜合前進(jìn)行仿真,仿真模型如圖5所示。AVS標(biāo)準(zhǔn)參考軟件產(chǎn)生測(cè)試碼流數(shù)據(jù),將測(cè)試碼流數(shù)據(jù)輸入硬件描述語(yǔ)言仿真模型,然后將輸出數(shù)據(jù)與標(biāo)準(zhǔn)輸出對(duì)比,實(shí)現(xiàn)仿真功能。經(jīng)過(guò)測(cè)試,硬件熵解碼后的數(shù)據(jù)與軟件熵解碼后的數(shù)據(jù)完全一致。
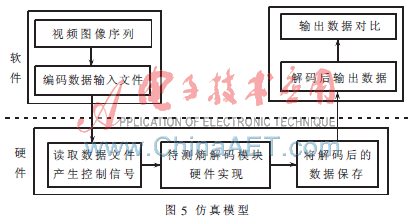
整個(gè)電路使用Altera的QuartusII 9.0軟件進(jìn)行綜合,使用的LE總數(shù)為1 906個(gè)。變字長(zhǎng)解碼器模塊是AVS解碼器的一部分,綜合后與其他部分集成,通過(guò)了FPGA驗(yàn)證,采用CycloneII系列的EP2C35型FPGA,其最高頻率能達(dá)到94 MHz,可以實(shí)現(xiàn)AVS高清晰度視頻的實(shí)時(shí)解碼。圖6為ce(v)解碼模塊的功能仿真結(jié)果圖。

本文提出了一種基于AVS標(biāo)準(zhǔn)的熵解碼器的硬件結(jié)構(gòu),從總體設(shè)計(jì)到各個(gè)模塊的設(shè)計(jì)都使用了流水線、并行處理、可重用設(shè)計(jì)等硬件設(shè)計(jì)的思想和方法;采用Verilog硬件描述語(yǔ)言實(shí)現(xiàn),并通過(guò)FPGA進(jìn)行了驗(yàn)證,達(dá)到了標(biāo)準(zhǔn)清晰度實(shí)時(shí)解碼的要求。
參考文獻(xiàn)
[1] 王忠平.AVS和H.264雙模解碼器SoC混成架構(gòu)的設(shè)計(jì)與研究[D].上海:上海交通大學(xué),2008.
[2] AVS聯(lián)合工作組.信息技術(shù):先進(jìn)音視頻編碼第2部分:視頻. 2006.
[3] 徐龍,鄧?yán)冢瓵VS熵解碼器的VLSI設(shè)計(jì)[J].計(jì)算機(jī)研究與發(fā)展,2009.
[4] 張楚.AVS和H.264雙標(biāo)準(zhǔn)可變長(zhǎng)解碼器設(shè)計(jì)[D].西安: 西北工業(yè)大學(xué),2007.