
1 引 言
目前FIR濾波器的實(shí)現(xiàn)方法主要有3種:利用單片通用數(shù)字濾波器集成電路、DSP器件和可編程邏輯器件實(shí)現(xiàn)。單片通用數(shù)字濾波器使用方便,,但由于字長和階數(shù)的規(guī)格較少,,不能完全滿足實(shí)際需要。使用DSP器件實(shí)現(xiàn)雖然簡單,,但由于程序順序執(zhí)行,,執(zhí)行速度必然不快。
FPGA有著規(guī)整的內(nèi)部邏輯陣列和豐富的連線資源,,特別適合于數(shù)字信號處理任務(wù),,相對于串行運(yùn)算為主導(dǎo)的通用DSP芯片來說,其并行性和可擴(kuò)展性更好,。但長期以來,,F(xiàn)PGA一直被用于系統(tǒng)邏輯或時(shí)序控制上,,很少有信號處理方面的應(yīng)用,,其原因主要是因?yàn)樵贔PGA中缺乏實(shí)現(xiàn)乘法運(yùn)算的有效結(jié)構(gòu)。本文利用FPGA乘累加的快速算法,,可以設(shè)計(jì)出高速的FIR數(shù)字濾波器,,使FPGA在數(shù)字信號處理方面有了長足的發(fā)展。
2 Matlab設(shè)計(jì)濾波器參數(shù)
以表1的濾波器參數(shù)為例,,分析設(shè)計(jì)高速FIR數(shù)字濾波器的方法,。

利用Matlab為設(shè)計(jì)FIR濾波器提供的工具箱,選擇濾波器類型為低通FIR,,設(shè)計(jì)方法為窗口法,,階數(shù)為16,窗口類型為Hamming,,Beta為0.5,,F(xiàn)s為8.6 kHz,F(xiàn)C為3.4 kHz,,導(dǎo)出的濾波器系數(shù)如下:
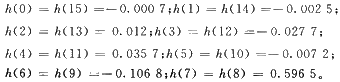
3 快速FIR濾波器算法的基本原理
(1) 分布式算法
分布式算法在完成乘加功能時(shí)是通過將各輸入數(shù)據(jù)每一對應(yīng)位產(chǎn)生的部分積預(yù)先相加形成相應(yīng)的部分積,,然后再對各部分積進(jìn)行累加得到最終結(jié)果。
對于一個(gè)N(N為偶數(shù))階線性相位FIR數(shù)字濾波器,,輸出可由式(1)表示:

(2) 乘法器設(shè)計(jì)
高性能乘法器是實(shí)現(xiàn)高性能的FIR運(yùn)算的關(guān)鍵,,分析乘法器的運(yùn)算過程,可以分解為部分積的產(chǎn)生和部分積的相加兩個(gè)步驟,。部分積的產(chǎn)生非常簡單,,實(shí)現(xiàn)速度較快,而部分積相加的過程是多個(gè)二進(jìn)制數(shù)相加的加法問題,,實(shí)現(xiàn)速度通常較慢,。解決乘法器速度問題,需要分別從這兩個(gè)方面入手,減小部分積的個(gè)數(shù),,提高部分積相加運(yùn)算的速度,。
3.1 Booth算法
Booth算法針對二進(jìn)制補(bǔ)碼表示的符號數(shù)之間的相乘,即可以同時(shí)處理二進(jìn)制正數(shù)/負(fù)數(shù)的乘法運(yùn)算,。Booth算法乘法器可以減少乘法運(yùn)算部分積個(gè)數(shù),,提高乘法運(yùn)算的速度。
下面討論一個(gè)M b×N b乘法器基本單元的設(shè)計(jì),。設(shè)乘數(shù)為A,,為M比特符號數(shù),2的補(bǔ)碼表示,,相應(yīng)各比特位的值為ai(i=0,,1,…,,M-2,,M-1),用比特串可表示為:
A=aN-1aN-2…a2a1a0 (2)
設(shè)被乘數(shù)為B,,為N比特符號數(shù),,2的補(bǔ)碼表示,相應(yīng)各比特位的值為bi(i=0,,1,,…,N-2,,N-1),,用比特串可表示為:
B=bN-1bN-2…b2b1b0 (3)
MacSoley提出了一種改進(jìn)Booth算法,將需要相加的部分積數(shù)減少為一半,,大大提高了乘法速度,。改進(jìn)Booth算法對乘數(shù)A中相鄰3個(gè)比特進(jìn)行編碼,符號數(shù)A可表示為:

改進(jìn)Booth算法根據(jù)用2的補(bǔ)碼表示的乘數(shù)比特圖案給出編碼值di,,其真值表如表2所示,。
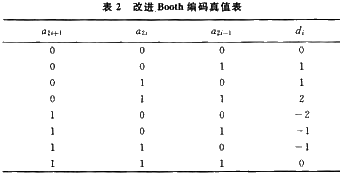
因此,應(yīng)用改進(jìn)Booth算法的乘法器運(yùn)算過程仍然包括Booth編碼過程,,即部分積產(chǎn)生過程和部分積相加過程,。所不同的是,其產(chǎn)生的部分積個(gè)數(shù)減少到原來的一半,。
3.2 Wallace樹加法
在采用改進(jìn)Booth算法將部分積數(shù)目減少為原來的一半之后,,乘法運(yùn)算的主要問題就是處理多個(gè)多比特二進(jìn)制操作數(shù)相加的問題。最直觀的算法是將多個(gè)部分積逐一累加,,但效率很低,,運(yùn)算時(shí)延巨大。
Wallace在1964年提出采用樹形結(jié)構(gòu)減少多個(gè)數(shù)累加次數(shù)的方法,稱為Wallace樹結(jié)構(gòu)加法器,。Wallace樹充分利用全加器3-2壓縮的特性,,隨時(shí)將可利用的所有輸入和中間結(jié)果及時(shí)并行計(jì)算,因而可以將N個(gè)部分積的累加次數(shù)從N-1次減少到log2N次,,大大節(jié)省了計(jì)算時(shí)延,。如圖2所示為Wallace樹結(jié)構(gòu)與CSA結(jié)構(gòu)的對照,其結(jié)構(gòu)的關(guān)鍵特征在于利用不規(guī)則的樹形結(jié)構(gòu)對所有準(zhǔn)備好輸人數(shù)據(jù)的運(yùn)算及時(shí)并行處理,。

Wallace樹結(jié)構(gòu)一般用于設(shè)計(jì)高速乘法器,,其顯著優(yōu)點(diǎn)是速度快,尤其對處理多個(gè)數(shù)相加的情況具有相當(dāng)?shù)膬?yōu)越性,,缺點(diǎn)是其邏輯結(jié)構(gòu)形式不規(guī)整,,在VLSI設(shè)計(jì)中對布局布線的影響較大。
3.3 進(jìn)位的快速傳遞
考慮到提高兩個(gè)多比特操作數(shù)相加運(yùn)算的速度,,關(guān)鍵在于解決進(jìn)位傳遞時(shí)延較大的問題,。采用以犧牲硬件資源面積換取速度的方式,以獨(dú)立的邏輯結(jié)構(gòu)單獨(dú)計(jì)算各個(gè)加法位需要的進(jìn)位輸入以及產(chǎn)生的進(jìn)位輸出,,提高進(jìn)位傳遞的速度,,從而提高加法運(yùn)算速度,。
3.3.1 四位超前進(jìn)位加法器的設(shè)計(jì)
兩個(gè)加數(shù)分別為A3A2A1A0,,B3B2BB1B0,C-1為低位進(jìn)位,。令兩個(gè)輔助變量分別為G3G2G1G0和P3P2P1P0:Gi=Ai&Bi,,Pi=Ai+Bi。G和P可用與門,、或門實(shí)現(xiàn),。
一位全加器的邏輯表達(dá)式可化為:

利用上述關(guān)系,一個(gè)4比特加法器的進(jìn)位計(jì)算就變化為下式:

由式(7)可以看出每一個(gè)進(jìn)位的計(jì)算都直接依賴于整個(gè)加法器的最初輸入,,而不需要等待相鄰低位的進(jìn)位傳遞,。理論上,每一個(gè)進(jìn)位的計(jì)算都只需要3個(gè)門延遲時(shí)間,,即同時(shí)產(chǎn)生G[i],,P[i]的與門以及或門,輸入為G[i],,P[i],,C-1的與門,以及最終的或門,。同樣道理,,理論上最終結(jié)果sum的得到只需要5個(gè)門延遲時(shí)間。
實(shí)際上,當(dāng)加數(shù)位數(shù)較大時(shí),,輸入需要驅(qū)動(dòng)的門數(shù)較多,,其VLSI實(shí)現(xiàn)的輸出時(shí)延增加很多,考慮互聯(lián)線延時(shí)的情況將會(huì)更加糟糕,。因此,,通常在芯片實(shí)現(xiàn)中設(shè)計(jì)位數(shù)較少的超前進(jìn)位加法器結(jié)構(gòu),而后以此為基本結(jié)構(gòu)構(gòu)造位數(shù)較大的加法器,。
3.3.2 進(jìn)位選擇加法器結(jié)構(gòu)
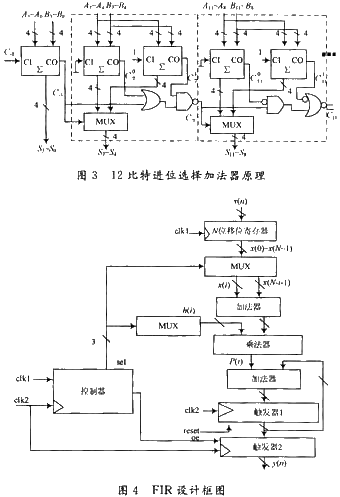
實(shí)際上,,超前進(jìn)位加法器只是提高了進(jìn)位傳遞的速度,其計(jì)算過程與行波進(jìn)位加法器同樣需要等待進(jìn)位傳遞的完成,。借鑒并行計(jì)算的思想,,人們提出了進(jìn)位選擇加法器結(jié)構(gòu),其算法的實(shí)質(zhì)是增加硬件面積換取速度性能的提高,。利用二進(jìn)制加法的特點(diǎn),,進(jìn)位或者為邏輯1,或者為邏輯0,,二者必居其一,。將進(jìn)位鏈較長的加法器分為M塊分別進(jìn)行加法計(jì)算,對除去包含最低位計(jì)算的M-1塊加法結(jié)構(gòu)復(fù)制兩份,,其進(jìn)位輸入分別預(yù)定為邏輯1和邏輯0,,于是M塊加法器可以同時(shí)并行進(jìn)行各自的加法運(yùn)算,然后根據(jù)各自相鄰低位加法運(yùn)算結(jié)果產(chǎn)生的進(jìn)位輸出,,選擇正確的加法結(jié)果輸出,。進(jìn)位選擇加法器的邏輯結(jié)構(gòu)圖如圖3所示。
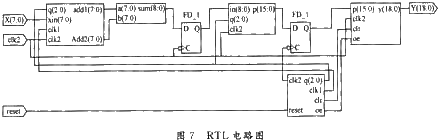
4 基于FPGA設(shè)計(jì)FIR數(shù)字濾波器
FIR數(shù)字濾波器的結(jié)構(gòu)如圖4所示,,圖中clk1為取樣時(shí)鐘(讀數(shù)時(shí)鐘),,clk2為FIR數(shù)字濾波器的工作時(shí)鐘,clk2頻率遠(yuǎn)大于clk1頻率,。其工作過程:clk1時(shí)鐘的上升沿啟動(dòng)一次計(jì)算過程,,控制器輸出reset信號使觸發(fā)器1清0;其后每個(gè)clk2周期計(jì)算一個(gè)h(i)[x(i)+x(N-i-1)]并進(jìn)行累加,,共需N/2個(gè)clk2周期完成計(jì)算,,完成計(jì)算后控制器輸出OE信號將結(jié)果輸出。
(1) 對沖激響應(yīng)系數(shù)h的處理:由Matlab設(shè)計(jì)FIR濾波器系數(shù)是一系列的浮點(diǎn)數(shù),,而FPGA不支持浮點(diǎn)數(shù)的運(yùn)算,,因此浮點(diǎn)數(shù)需轉(zhuǎn)換成定點(diǎn)數(shù),設(shè)計(jì)可采用Q值量化法,,把系數(shù)擴(kuò)大了27=128倍,,然后轉(zhuǎn)化為8位二進(jìn)制數(shù)補(bǔ)碼,。最終結(jié)果再右移7位就可等到真正結(jié)果。
(2) 本設(shè)計(jì)對于有符號數(shù)采用補(bǔ)碼表示的方法,,在設(shè)計(jì)中多次出現(xiàn)加法運(yùn)算,,可能會(huì)產(chǎn)生溢出,所以應(yīng)進(jìn)行符號位擴(kuò)展,。將符號位擴(kuò)展到輸出統(tǒng)一的最高位,,才能夠保證計(jì)算結(jié)果的正確性。
擴(kuò)展方法為:
P9P8P7P6P5P4P3P2P1P0
=P9P9P9P9P9P8P7P6P5P4P3P2P1P0
其中:P9為補(bǔ)碼的符號位,。
(3) Booth編碼處理由于存在求“-x”的運(yùn)算,,需進(jìn)行求反加1。如果每1次調(diào)用Booth編碼都進(jìn)行加1運(yùn)算,,不僅使資源大大浪費(fèi),,而且由于位數(shù)較長,也會(huì)大大影響乘法器的速度,。而本設(shè)計(jì)將加1放在Wallace樹中計(jì)算,,盡管多了1級Wallace樹,但速度和資源上都大大提高了,。
(4) 由于FIR是線性相位,,h(i)=h(15-i),可以將乘法運(yùn)算由16次減少到8次,;再通過對h(i)進(jìn)行Booth編碼可以將部分積減少到4個(gè),;最終利用Wallace樹以及超快速加法器將4個(gè)部分積的相加,得到8*8乘法器的結(jié)果,。由于將Booth編碼中的加1放在Wallace樹中,,經(jīng)過分析需要3級Wallace樹,。
5 FIR濾波器的頻率特性分析
利用Matlab中rand()和round()函數(shù)產(chǎn)生-128~128之間中100個(gè)整隨機(jī)數(shù),,求幅頻響應(yīng)如圖5所示。
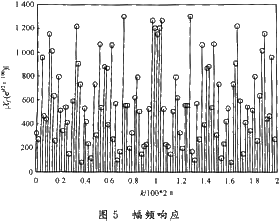
再將這100個(gè)數(shù)通過FIR濾波器,,求輸出的幅頻響應(yīng)如圖6所示,。
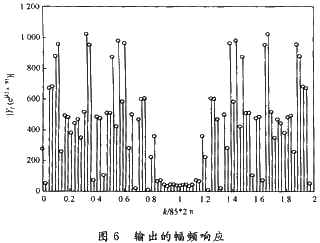
比較輸入x與輸出y的幅頻特性,可以看出FIR濾波器為低通濾波,,指標(biāo)符合設(shè)計(jì)要求,。
6 用ISE綜合分析FIR濾波器的性能分析
分析設(shè)計(jì)框圖可以看出,占用時(shí)間最長的路徑為8位加法器——乘法器——累加器,,這是影響工作頻率最主要的部分,。設(shè)計(jì)中采用流水線技術(shù),在這條路徑中增加寄存器,,將最長路徑拆分成較短路徑,,可以取得比較好的效果,,提高系統(tǒng)的工作頻率。
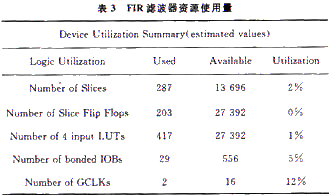
FIR濾波器的最高工作頻率如下:

可以看出最高工作頻率可以達(dá)到154.84 MHz,,實(shí)現(xiàn)了高速FIR數(shù)字濾波器的設(shè)計(jì),。