
摘 要: 基于傳統(tǒng)的PCA方法,提出了推廣的PCA人臉識(shí)別方法。推廣的PCA方法先對訓(xùn)練圖像矩陣集進(jìn)行分塊,再利用傳統(tǒng)PCA對分塊得到的子訓(xùn)練矩陣集進(jìn)行分析,得到多個(gè)變換矩陣,通過這些變換矩陣將訓(xùn)練圖片和測試圖片投影到特征空間進(jìn)行鑒別。與傳統(tǒng)PCA方法相比,提高了主元的維數(shù),有效地增加了識(shí)別的精度。在FERET人臉庫上的試驗(yàn)結(jié)果表明,所提出的方法在識(shí)別性能上明顯優(yōu)于傳統(tǒng)的PCA方法,識(shí)別率得到了提高。
關(guān)鍵詞: 主成分分析; 特征抽取; 推廣的PCA; 特征矩陣; 人臉識(shí)別
人臉識(shí)別是模式識(shí)別研究領(lǐng)域的重要課題,也是一個(gè)目前非常活躍的研究方向[1,2]。它一般可描述為:給定一個(gè)靜止或視頻圖像,利用已有的人臉數(shù)據(jù)庫來確認(rèn)圖像中的一個(gè)或多個(gè)人。近年來,關(guān)于人臉圖像線性鑒別分析方法的研究激起了人們的廣泛興趣,其焦點(diǎn)是如何抽取有效的鑒別特征和降維。特征抽取研究肩負(fù)兩方面的使命:尋找針對模式的最具鑒別性的描述,以使此類模式的特征能最大程度地區(qū)別于彼類;在適當(dāng)?shù)那闆r下實(shí)現(xiàn)模式數(shù)據(jù)描述的維數(shù)壓縮,當(dāng)描述模式的原始數(shù)據(jù)空間對應(yīng)較大維數(shù)時(shí),這一點(diǎn)會(huì)非常有意義,甚至必不可缺[3]。
在人臉圖像識(shí)別中,主成分分析PCA(Principal Component Analysis)[4],又稱K-L變換,被認(rèn)為是最成功的線性鑒別分析方法之一,目前仍然被廣泛地應(yīng)用在人臉等圖像識(shí)別領(lǐng)域。本質(zhì)上PCA方法的目的是在最小均方意義下尋找最能代表原始數(shù)據(jù)的投影。SIROVICH 和KIRBY最初使用PCA有效地表示人臉[5]。由于人臉結(jié)構(gòu)的相似性,他們認(rèn)為可以收集一些人臉圖像作為基圖(特征圖),任何人臉圖像可以近似地表示為該人臉樣本的均值與部分基圖的加權(quán)和。1991年,TURK和 PENDAND提出了著名的“Eigenfaces”方法。1997年,BELHUMEAR P N、HESPANHA J P、KRIENGMAN D J在主成分分析的基礎(chǔ)上又給出了“Fisherfaces”方法。
以上方法在處理人臉等圖像識(shí)別問題時(shí),遵循一個(gè)共同的過程,即首先將圖像矩陣轉(zhuǎn)化為圖像向量,然后以該圖像向量作為原始特征進(jìn)行線性鑒別分析。由于圖像矢量的維數(shù)一般較高,比如,分辨率為100×80的圖像對應(yīng)的圖像向量的維數(shù)高達(dá)8 000,在如此高維的圖像向量上進(jìn)行線性鑒別分析不僅會(huì)遇到小樣本問題,而且經(jīng)常需要耗費(fèi)大量的時(shí)間,有時(shí)還受研究條件的限制(比如機(jī)器內(nèi)存小),導(dǎo)致不可行。針對這個(gè)問題,人們相繼提出不少解決問題的方法。概括起來,這些方法可分為以下兩類:從模式樣本出發(fā),在模式識(shí)別之前,通過降低模式樣本特征向量的維數(shù)達(dá)到消除奇異性的目的,可以降低圖像的分辨率實(shí)現(xiàn)降維;從算法本身入手,通過發(fā)展直接針對于小樣本問題的算法來解決問題[6,7]。
本文基于主成分分析的思想,從原始數(shù)字圖像出發(fā),在模式識(shí)別之前,先對整個(gè)圖像訓(xùn)練矩陣集進(jìn)行分塊,該塊中的圖像盡可能具有同樣的性質(zhì),從而更接近于高斯分布;再用PCA方法對每個(gè)分塊得到的子圖像訓(xùn)練矩陣進(jìn)行分析,得到多個(gè)變換矩陣,通過這些變換矩陣將訓(xùn)練圖片向量和測試圖片向量投影到特征空間進(jìn)行鑒別。這樣做主要基于如下考慮:在傳統(tǒng)的PCA算法中,要求訓(xùn)練集符合高斯分布,得到的結(jié)果才是理想的,但是實(shí)際操作中訓(xùn)練樣本由于光照、表情、姿態(tài)等因素遠(yuǎn)離高斯分布,而改進(jìn)的PCA算法通過對其進(jìn)行歸類訓(xùn)練子訓(xùn)練集(由于影響因素較小,更接近于高斯分布)提取主元,同時(shí)該方法可以增加主元的維數(shù),能提供更多的有效特征。在著名的FERET人臉庫上的試驗(yàn)結(jié)果表明,本文提出的方法在識(shí)別性能上明顯優(yōu)于傳統(tǒng)的PCA方法,識(shí)別率有顯著提高。

1.2 特征抽取
原始圖像的維數(shù)較大,不利于直接用于分類,必須對原始數(shù)據(jù)進(jìn)行降維。如何找出能代表原始圖像的低維數(shù)據(jù)是進(jìn)行分類的關(guān)鍵。

2 推廣的PCA方法
2.1 思想與最優(yōu)投影矩陣
傳統(tǒng)PCA的模型中存在諸多的假設(shè)條件,決定了它存在一定的限制,在有些場合可能會(huì)效果不好甚至失效。傳統(tǒng)的PCA算法要求標(biāo)準(zhǔn)訓(xùn)練樣本矩陣符合高斯分布,也就是說,如果考察的數(shù)據(jù)的概率分布并不滿足高斯分布或是指數(shù)型的概率分布,那么PCA將會(huì)失效。在這種模型下,不能使用方差和協(xié)方差來很好地描述噪音和冗余,對教化之后的協(xié)方差矩陣并不能得到很合適的結(jié)果。

3 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)是在FERET人臉庫上進(jìn)行的。FERET人臉庫由200個(gè)人、每人7幅圖組成:第1幅圖是人臉的正面照,第2~5幅圖是人臉角度的變換,第6幅圖表情的變換,第7幅圖是亮度的變化。每幅圖的分辨率是80×80。圖1是FERET人臉庫的某一人的7幅圖像。

FERET數(shù)據(jù)庫中每張圖片都有一個(gè)類別標(biāo)號(hào),代表其不同因素下采集的圖片,比如標(biāo)號(hào)00012_930831_fa_a,其中00012表示類別ID,930831表示樣本生成時(shí)間,fa表示人臉偏轉(zhuǎn)角度,a表示光照強(qiáng)度。本文的實(shí)驗(yàn)就是根據(jù)不同的圖像標(biāo)號(hào)來劃分?jǐn)?shù)據(jù)集合,從而達(dá)到外在因素較少的情況下,數(shù)據(jù)盡可能地滿足簡單的高斯分布。
將每類的前4幅圖作為訓(xùn)練樣本,后3幅圖作為測試樣本,這樣訓(xùn)練樣本總數(shù)為800,測試樣本為600。首先,利用傳統(tǒng)的PCA算法,即不對標(biāo)準(zhǔn)訓(xùn)練樣本矩陣集進(jìn)行分塊,計(jì)算出不同能量系數(shù)下的識(shí)別率。再利用推廣的PCA算法,分別實(shí)驗(yàn)兩種情況:(1)將各個(gè)類訓(xùn)練樣本的前兩幅圖組合為訓(xùn)練樣本矩陣1,將各個(gè)類的訓(xùn)練樣本的第3、4幅圖組合為訓(xùn)練樣本矩陣2,這樣就將傳統(tǒng)PCA中的訓(xùn)練矩陣集分為兩個(gè)子訓(xùn)練矩陣集。對這兩個(gè)子訓(xùn)練矩陣集進(jìn)行計(jì)算得到變換矩陣[P1,P2]。再將測試樣本和訓(xùn)練樣本通過[P1,P2]投影到特征空間,對不同能量系數(shù)的情況計(jì)算得到識(shí)別率。(2)將每類的4個(gè)訓(xùn)練樣本圖片分別組合為四子訓(xùn)練矩陣集,然后用同樣的方法計(jì)算識(shí)別率。得到的實(shí)驗(yàn)結(jié)果如圖2所示。
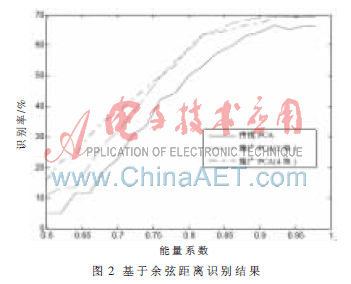
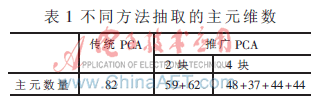
本文分別采用余弦分類器進(jìn)行分辨率的計(jì)算。從圖中可以看出,對推廣的PCA的具體應(yīng)用其識(shí)別率均優(yōu)于傳統(tǒng)的PCA方法。進(jìn)一步分析其原因:推廣的PCA通過對標(biāo)準(zhǔn)訓(xùn)練樣本矩陣集進(jìn)行分塊,對每一個(gè)子訓(xùn)練矩陣集抽取主元,雖然單個(gè)子訓(xùn)練集抽取的主元維數(shù)可能比較低,但是由于有多個(gè)子訓(xùn)練矩陣集,所以總體看來其抽取的主元維數(shù)還是較傳統(tǒng)的PCA主元維數(shù)多,因此能提高識(shí)別的精度。表1為當(dāng)能量系數(shù)為0.9時(shí)不同方法抽取的主元維數(shù)。
本文提出了推廣的PCA的人臉識(shí)別方法,其本質(zhì)是通過對標(biāo)準(zhǔn)訓(xùn)練樣本矩陣集做分塊,并對其子塊分別作PCA,抽取子塊的主元。這樣做是為了使影響因素較小,更接近于高斯分布,并且提高了主元的維數(shù),在分類器進(jìn)行分類時(shí)能夠更好地減少誤差,便于模式識(shí)別。本實(shí)驗(yàn)使用環(huán)境為 Microsoft Windows XP,硬件配置為Petium4,3.0 GHz CPU的計(jì)算機(jī),優(yōu)化算法采用Matlab編寫。
在試驗(yàn)中發(fā)現(xiàn),對同一數(shù)據(jù)庫,對樣本矩陣采用不同的分塊,獲得的最高識(shí)別率一般不同,如何尋求最佳分塊方式有待進(jìn)一步研究。
參考文獻(xiàn)
[1] ZHAO W, CHELLAPPA R, PHILLIPS P J, et al. Face recognition: A literature survey[J]. Acm Computing Surveys, 2003,35(4):399-459.
[2] TURK M, PENTLAND A. Face recognition using eigenfaces[A]. Proc. IEEE Conference on Computer Vision and Pattern Recognition[C].USA, Howaii, Maui:IEEE,1991:586-590.
[3] 徐勇.幾種線性與非線性特征抽取方法及人臉識(shí)別應(yīng)用[D].南京:南京理工大學(xué),2004.
[4] 邊肇祺,張學(xué)工.模式識(shí)別(第2版)[M].北京:清華大學(xué)出版社,1999.
[5] 陳伏兵.人臉識(shí)別中鑒別特征抽取若干方法研究[D].南京:南京理工大學(xué),2006.
[6] TURK M, PENTLAND A. Eigenfaces for recognition[J]. Journal of Cognitive Neurosciences,1991,3(1):77-86.
[7] ZHOU Ji Liu, ZHOU Ye.Research advances on the theory of face recognition[J]. Journal of Computer Aided Design and Computer Graphics, 1991,11(2):180-184.