
摘 要: 提出一種人體行為識(shí)別模型和前景提取方法。針對(duì)人體運(yùn)動(dòng)過(guò)程中產(chǎn)生新的行為問(wèn)題,該模型用分層Dirichlet過(guò)程聚類人體特征數(shù)據(jù)來(lái)判斷人體運(yùn)動(dòng)過(guò)程中是否有未知的人體行為模式;用無(wú)限隱Markov模型對(duì)含有未知行為模式的特征向量進(jìn)行行為模式的有監(jiān)督的學(xué)習(xí),由管理者將其添加到規(guī)則與知識(shí)庫(kù)中。當(dāng)知識(shí)庫(kù)的行為模式達(dá)到一定規(guī)模時(shí),系統(tǒng)便可以無(wú)監(jiān)督地對(duì)人體行為進(jìn)行分析,其分析采用Markov模型中高效的Viterbi解碼算法來(lái)完成。對(duì)于前景的提取,提出了基于背景邊緣模型與背景模型相結(jié)合的前景檢測(cè)方法,此方法能夠有效避免光照、陰影等外部因素的影響。仿真實(shí)驗(yàn)證明,本文提出的方法在實(shí)時(shí)視頻監(jiān)控中的人體行為識(shí)別方面有獨(dú)特的優(yōu)勢(shì)。
關(guān)鍵詞: 行為模式;嵌套的狄利克雷過(guò)程;無(wú)限隱Markov模型;行為識(shí)別
人的行為理解與描述是近年來(lái)被廣泛關(guān)注的研究熱點(diǎn),它是指對(duì)人的運(yùn)動(dòng)模式進(jìn)行分析和識(shí)別,并用自然語(yǔ)言等加以描述。行為理解可以簡(jiǎn)單地被認(rèn)為是時(shí)變數(shù)據(jù)的分類問(wèn)題,即將測(cè)試序列與預(yù)先標(biāo)定的代表典型行為的參考序列進(jìn)行匹配。對(duì)于人的行為識(shí)別,參考文獻(xiàn)[1]概括為以下兩種方法:
(1)模板匹配方法。參考文獻(xiàn)[2-5]都采用模板匹配技術(shù)的行為識(shí)別方法。首先將圖像序列轉(zhuǎn)換為一組靜態(tài)形狀模式,然后在識(shí)別過(guò)程中和預(yù)先存儲(chǔ)的行為標(biāo)本來(lái)解釋圖像序列中人的運(yùn)動(dòng)。
(2)空間方法。基于狀態(tài)空間模型的方法定義每個(gè)靜態(tài)姿勢(shì)作為一個(gè)狀態(tài),這些狀態(tài)之間通過(guò)某種概率聯(lián)系起來(lái)。目前,狀態(tài)空間模型已經(jīng)被廣泛地應(yīng)用于時(shí)間序列的預(yù)測(cè)、估計(jì)和檢測(cè),最有代表性的是HMMs。每個(gè)狀態(tài)中可用于識(shí)別的特征包括點(diǎn)、線或二維小區(qū)域。
本文從兩個(gè)方面來(lái)闡述視頻監(jiān)控系統(tǒng)中的人體行為識(shí)別:(1)行為描述,即在視頻幀中提取人體特征,并對(duì)人體行為進(jìn)行描述;(2)行為識(shí)別,通過(guò)基于數(shù)理統(tǒng)計(jì)的Markov模型訓(xùn)練得到的行為檢測(cè)器來(lái)實(shí)現(xiàn)。針對(duì)行為描述,本文采用背景邊緣法來(lái)提取視頻前景,通過(guò)背景邊緣法來(lái)獲取人體的邊界輪廓,背景法可獲取前景人體區(qū)域。由于背景法受光照影響較大,通過(guò)這種方法提取的人體區(qū)域不夠完整,但通過(guò)人體邊界和人體區(qū)域相加,再進(jìn)行形態(tài)學(xué)的閉運(yùn)算,就能得到較完整的前景目標(biāo)。對(duì)于行為識(shí)別,首先利用HDP-iHMM進(jìn)行人體行為狀態(tài)的確定,即確定是否有新的人體行為模式產(chǎn)生,如果有新的行為狀態(tài),則進(jìn)行iHMM的行為模式的學(xué)習(xí);如果沒(méi)有新的行為狀態(tài),則用已訓(xùn)練的HMM進(jìn)行行為檢測(cè)。
本文的創(chuàng)新點(diǎn)是在人體前景獲取的過(guò)程中利用了兩種背景模型的結(jié)合。在行為檢測(cè)方面,應(yīng)用HDP-iHMM確定是否有未知人體行為,利用HMM來(lái)進(jìn)行行為的檢測(cè),這樣能使檢測(cè)系統(tǒng)不斷地學(xué)習(xí),當(dāng)知識(shí)庫(kù)的行為模式達(dá)到一定規(guī)模時(shí),系統(tǒng)便可以無(wú)監(jiān)督地對(duì)人體行為進(jìn)行檢測(cè)。
1 人體行為描述
參考文獻(xiàn)[2]、[6]為了理解人體行為,采用最常用的背景減除法來(lái)提取運(yùn)動(dòng)的人體,利用當(dāng)前圖像與背景圖像的差分來(lái)檢測(cè)出前景運(yùn)動(dòng)區(qū)域的一種技術(shù),但這種方法對(duì)光照和外來(lái)無(wú)關(guān)事件的干擾等特別敏感。為了解決這個(gè)問(wèn)題,本文采用背景邊界模型和背景模型的結(jié)合來(lái)檢測(cè)前景,通過(guò)這兩種模型的結(jié)合,再應(yīng)用形態(tài)學(xué)運(yùn)算,就能獲得一個(gè)相對(duì)較完整的人體前景。
1.1 人體前景提取
背景邊緣模型通過(guò)統(tǒng)計(jì)視頻圖像中每個(gè)位置在連續(xù)時(shí)間內(nèi)出現(xiàn)邊緣的概率計(jì)算得到:

(3)通過(guò)一些數(shù)學(xué)運(yùn)算結(jié)合兩種模型獲取f(x,y),然后對(duì)f(x,y)進(jìn)行形態(tài)學(xué)運(yùn)算,來(lái)填充前景孔洞,為特征計(jì)算奠定基礎(chǔ)。
1.2 特征計(jì)算
在提取了前景后,為了分析人的活動(dòng)和行為模式,進(jìn)一步提取和計(jì)算一些人體特征數(shù),本文的研究著重于以下圖像特征值:
(1)長(zhǎng)寬比(A):A=L/W,A值包含了行為模式識(shí)別的重要信息。這一特征可以識(shí)別人體是站立或是別的姿勢(shì)。
(2)矩形度(R):R=A0/AR,其中A0是人體的面積,AR是最小封閉矩形的面積。矩形擬合因子的值限定在0和1之間。
(3)協(xié)方差矩陣(C):

2 行為的識(shí)別模型
對(duì)未知行為的學(xué)習(xí)過(guò)程如圖1所示。當(dāng)HDP聚類過(guò)程中發(fā)現(xiàn)有新行為產(chǎn)生時(shí),則用iHMM的Beam抽樣算法學(xué)習(xí)未知行為模式,將定性的行為模式添加到規(guī)則和知識(shí)庫(kù)。



該多層模型的對(duì)應(yīng)圖形化表示如圖2所示。在本文中,βk′為轉(zhuǎn)移到狀態(tài)k′的轉(zhuǎn)換概率的先驗(yàn)均值,α為控制針對(duì)先驗(yàn)均值的可變性。如果固定β=(1/k,…,1/k,0,0…),本文K個(gè)條目的值為l/k,而其余為0;當(dāng)且僅當(dāng)k′∈{1,…,K}時(shí),達(dá)到狀態(tài)k′的轉(zhuǎn)換概率為非零。

3 系統(tǒng)仿真實(shí)驗(yàn)
3.1 未知行為模式的定性
(1)設(shè)初始行為狀態(tài)為4個(gè),然后進(jìn)行抽樣獲取訓(xùn)練HDP-iHMM模型的樣本,對(duì)模型進(jìn)行訓(xùn)練,同時(shí)對(duì)樣本進(jìn)行聚類,可得到如圖3(a)的聚類圖,模型狀態(tài)轉(zhuǎn)移矩陣如圖4(a)所示,模型觀察值轉(zhuǎn)移矩陣如圖4(d)。


(2)獲取一個(gè)檢測(cè)樣本,通過(guò)已經(jīng)訓(xùn)練好的模型來(lái)驗(yàn)證模型的有效性。將包含5個(gè)狀態(tài)的樣本進(jìn)行檢測(cè),會(huì)發(fā)現(xiàn)有一種新的行為,系統(tǒng)提示需要進(jìn)行知識(shí)庫(kù)更新。將這種新產(chǎn)生的行為進(jìn)行定義后添加到知識(shí)庫(kù)中,并用這個(gè)樣本作為訓(xùn)練樣本來(lái)訓(xùn)練一個(gè)與此行為相對(duì)應(yīng)的模型,將訓(xùn)練結(jié)果保存到知識(shí)庫(kù)中,同時(shí)對(duì)樣本進(jìn)行聚類,可得到如圖3(b)所示的聚類圖,模型狀態(tài)裝轉(zhuǎn)移矩陣如圖4(b),模型觀察值轉(zhuǎn)移矩陣如圖4(e)。由圖可看出,行為狀態(tài)增加了1個(gè),由4個(gè)變成5個(gè)。最后,用包含狀態(tài)5和狀態(tài)6的樣本進(jìn)行檢測(cè),同樣,系統(tǒng)就會(huì)有新的行為的提示信息。重復(fù)上述過(guò)程,可得到如圖3(c)所示的聚類圖,模型狀態(tài)轉(zhuǎn)移矩陣如圖4(c)所示,模型觀察值轉(zhuǎn)移矩陣如圖4(f)所示。由圖4可看出,狀態(tài)又增加了1個(gè),由5個(gè)變成6個(gè)。
通過(guò)聚類圖可看出,能將代表新的人體行為特征向量聚為一類,圖3中的虛線橢圓表示一個(gè)新的聚類,從最初的4類到新增一類后的5類和新增兩類后的6類。
以上描述了HDP-iHMM在識(shí)別未知行為方面的有效性,通過(guò)iHMM可以對(duì)未知行為進(jìn)行確定和描述,為行為檢測(cè)和預(yù)測(cè)做好準(zhǔn)備。在本仿真統(tǒng)中,本文用HDP-iHMM確定未知行為,在事件數(shù)目確定后,用HMM實(shí)現(xiàn)行為的識(shí)別。通過(guò)iHMM和HMM的結(jié)合,增加了行為識(shí)別的主動(dòng)性和智能性。
3.2 行為識(shí)別
3.2.1 前景獲取
背景邊緣模型是記錄背景模型的邊緣像素位置信息,通過(guò)背景邊緣圖與當(dāng)前視頻幀的邊緣圖像在相同位置像素的比較來(lái)判斷該位置的像素點(diǎn)是否為前景目標(biāo)像素點(diǎn)。通過(guò)與背景檢測(cè)的比較,驗(yàn)證本文方法的優(yōu)點(diǎn),這種前景幀判斷方法相對(duì)于其他常見(jiàn)的前景判斷方法不但簡(jiǎn)單而且魯棒性好,圖5給出了兩種方法的比較實(shí)例。從圖中可以看出,由于受光照和陰影等因素的影響,背景法因?yàn)楣庹盏耐蛔兪沟脵z測(cè)結(jié)果為整個(gè)畫面,不太理想。而本文的方法則受光線的變化影響較小。由此可見(jiàn),對(duì)于前景檢測(cè),本方法能夠很好地避免光照和人體陰影的影響,能夠較好地檢測(cè)前景目標(biāo)。

3.2.2 模型的學(xué)習(xí)和行為識(shí)別
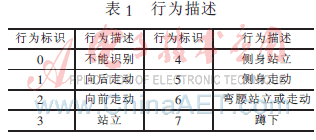
對(duì)系統(tǒng)行為識(shí)別能力的實(shí)驗(yàn)以視頻監(jiān)控中人體行為的識(shí)別為例。首先通過(guò)iHMM對(duì)未知行為模式進(jìn)行定性和描述。表1為系統(tǒng)已經(jīng)能識(shí)別的行為描述,讓人體特征數(shù)據(jù)通過(guò)本文的識(shí)別系統(tǒng),識(shí)別系統(tǒng)將會(huì)返回一個(gè)行為標(biāo)識(shí),通過(guò)行為標(biāo)識(shí)索取行為描述。
對(duì)于本文仿真實(shí)驗(yàn),采用的訓(xùn)練樣本就是獲取的人體特征向量。以“站立”、“側(cè)身走動(dòng)”和“蹲下”所對(duì)應(yīng)的特征向量為訓(xùn)練樣本,分別用S1、S2、S3表示來(lái)說(shuō)明模型的訓(xùn)練過(guò)程。訓(xùn)練的收斂誤差用聯(lián)合相關(guān)性的穩(wěn)定性來(lái)衡量,收斂誤差根據(jù)收斂的精確度而定。訓(xùn)練過(guò)程中隨著迭代次數(shù)的增加,最大似然估計(jì)值的對(duì)數(shù)值也在不斷地增加,直到達(dá)到收斂誤差為止。由于訓(xùn)練樣本的差異,聯(lián)合相關(guān)性穩(wěn)定在不同的迭代次數(shù)之后。但從圖6中可以看出,每個(gè)訓(xùn)練樣本都達(dá)到了收斂。

模型對(duì)視頻監(jiān)控中人體行為的識(shí)別能力,HMM通過(guò)搜索最佳狀態(tài)序列,以最大后驗(yàn)概率為準(zhǔn)則來(lái)找到識(shí)別結(jié)果。在本系統(tǒng)中采用25幀/s的視頻輸入,來(lái)分析視頻序列中人體的行為,同時(shí)驗(yàn)證本文識(shí)別系統(tǒng)的識(shí)別準(zhǔn)確率。圖7為對(duì)人體“站立”行為的識(shí)別,圖8為對(duì)人體“蹲下”行為的識(shí)別。從圖中可以看出,采用的基于統(tǒng)計(jì)學(xué)的行為識(shí)別模型能夠很好地識(shí)別不同時(shí)刻人的同一行為。

在整個(gè)小男孩的行為識(shí)別過(guò)程中,由于存在許多相關(guān)因素的影響,會(huì)出現(xiàn)識(shí)別錯(cuò)誤的情況。本文在整個(gè)跟蹤過(guò)程中統(tǒng)計(jì)了跟識(shí)別錯(cuò)誤率,其結(jié)果如圖9所示。從圖9可以看出,隨著跟蹤處理幀數(shù)的增加,跟蹤錯(cuò)誤率總圍繞某一值上下波動(dòng),本文統(tǒng)計(jì)跟蹤錯(cuò)誤率大約是18%。
從時(shí)間復(fù)雜度方面考慮,整個(gè)系統(tǒng)包括兩個(gè)部分:(1)離線的未知行為確定和行為模式學(xué)習(xí)系統(tǒng);(2)在線的行為識(shí)別系統(tǒng)。對(duì)于在線系統(tǒng),其行為識(shí)別算法采用應(yīng)用比較廣泛的Viterbi算法。因?yàn)槔萌怕使诫m然可以計(jì)算系統(tǒng)的輸出概率,但無(wú)法找到一條最佳的狀態(tài)轉(zhuǎn)移路徑。而Viterbi算法,不僅可找到一條足夠好的轉(zhuǎn)移路徑,而且可得到該路徑對(duì)應(yīng)的輸出概率。同時(shí),Viterbi算法計(jì)算輸出概率所需要的計(jì)算量要比全概率公式的計(jì)算量小很多。這些可以說(shuō)明本文的行為識(shí)別系統(tǒng)實(shí)時(shí)性較好,識(shí)別算法時(shí)間復(fù)雜度小。對(duì)于離線系統(tǒng),仿真試驗(yàn)已經(jīng)驗(yàn)證了對(duì)未知行為的確定能力和行為模式的學(xué)習(xí)能力,而且離線系統(tǒng)對(duì)實(shí)時(shí)性要求較低。
本文的重點(diǎn)是對(duì)視頻流中人體行為識(shí)別的研究,這是計(jì)算機(jī)視覺(jué)中一個(gè)重要的研究領(lǐng)域之一。仿真實(shí)驗(yàn)演示了視頻監(jiān)控中人體行為識(shí)別的全過(guò)程,提出了用背景邊緣模型來(lái)提取前景圖像,從仿真實(shí)驗(yàn)可看出此方法有較好的提取效果,而且能夠有效避免光照和陰影等外部因素的影響。此外,在行為識(shí)別方面,應(yīng)用NDP_iHMM來(lái)確定行為狀態(tài)數(shù),在狀態(tài)數(shù)確定以后將無(wú)限iHMM變成有限HMM,這樣提高了系統(tǒng)的普適性,通過(guò)iHMM與HMM結(jié)合,解決了在系統(tǒng)行為狀態(tài)可變情況下的人體行為識(shí)別問(wèn)題。
參考文獻(xiàn)
[1] 王亮,胡衛(wèi)明,譚鐵牛.人運(yùn)動(dòng)的視覺(jué)分析綜述[J].計(jì)算機(jī)學(xué)報(bào),2005,25(3).
[2] CUI Y, WENG J. Hand segmentation using learning-based prediction and verification for hand sign recognition[C]. Proceedinys of IEEE Conference on Computer Vision and Pattern Recognition, Puerto Rico, 1997: 88-93.
[3] POLANA R, NELSON R. Low level recognition of human motion[C]. Proceedinys of IEEE Workshop on Motion of Non-Rigid and Articulated Objects, Austin, TX, 1994: 77-82.
[4] BOBICK A, DAVIS J. Real-time recognition of activity using temporal templates[C]. Proceedinys of IEEE Workshop on Applications of Computer Vision, Sarasota, Florida, 1996: 39-42.
[5] DAVIS J, BOBICK A. The representation and recognition of action using temporal templates[R]. MIT Media Lab, Perceptual Computing Group, Technical report: 1997: 402.
[6] XIANG Tao, GONG Shao Gang . Video behavior profiling for anomaly detection[J]. IEEE Transactions On Pattern Analysis and Machine Intelligence, 2008, 30(5):893-908.