
文獻標識碼: A
文章編號: 0258-7998(2011)02-0095-04
隨著RFID技術在物聯(lián)網(wǎng)中的大量應用,大量標簽進入閱讀器的識別范圍,閱讀器應能準確及時地識別出所有標簽。但是同一RFID系統(tǒng)中所有的標簽工作在相同的頻率,同一時刻多個標簽從閱讀器獲得能量并向閱讀器發(fā)送信息,這時就會出現(xiàn)相互干擾,使閱讀器不能正確識別標簽,稱為標簽沖突。為此出現(xiàn)了防沖突協(xié)議,以解決識別過程中多個標簽的信道共享和訪問沖突的問題。在無源電子標簽系統(tǒng)中,存在著如下約束:標簽自身不能提供電能,需要閱讀器在通信時為它提供能量;識讀范圍內(nèi)的標簽總數(shù)未知,標簽間不能通信;標簽的內(nèi)存和計算能力有限。因此,理想的防沖突協(xié)議應當具有如下特點:(1)標簽端電路簡單;(2)最小的識別時延,閱讀器與標簽的通信數(shù)據(jù)量應盡可能少,識別時間應盡可能短;(3)識別過程中電能消耗盡可能少,否則可能因電能不足而不能完成識別;(4)識別率應能達到100%,即處于識別范圍內(nèi)的所有標簽都能全部正確識別[1]。
現(xiàn)有的各種防沖突協(xié)議可以分為兩類:隨機性協(xié)議和確定性協(xié)議[2]。隨機性協(xié)議發(fā)生沖突時標簽延遲一個隨機時間后響應閱讀器,目前形成了以 Aloha為基礎的隨機性協(xié)議簇,如純 Aloha、時隙Aloha、幀時隙Aloha。確定性協(xié)議中,閱讀器不斷發(fā)送要查詢的標簽ID的前綴,與前綴匹配的標簽響應閱讀器,閱讀器根據(jù)檢測到?jīng)_突信息,將待識別的標簽進行分組,在組內(nèi)重復進行上述查詢過程(識別修正下次發(fā)送的查詢前綴),直至識別出一個標簽。對每一組內(nèi)所有標簽進行識別,閱讀器范圍內(nèi)的所有標簽都被識別。確定性協(xié)議按照識別過程中標簽是否需要內(nèi)存儲器可以分為內(nèi)存協(xié)議和無內(nèi)存協(xié)議,目前形成了以二進制樹搜索協(xié)議為基礎的系列協(xié)議,如位仲裁搜索(BA)、查詢樹搜索(Q-tree)、基本二進制搜索(BS)、動態(tài)二進制搜索(DBS)、自適應二進制搜索(ABS)[1]、具有后退索引的二進制搜索(BDBS)[2]及其他改進協(xié)議[3-5]。隨機性協(xié)議比確定性協(xié)議識別速度快,但存在不穩(wěn)定工作區(qū)間, 理論吞吐量被限制在 1/e以內(nèi),會導致“標簽饑餓問題”, 即特定的標簽可能會在很長一段時間內(nèi)都無法被正確識別。確定性協(xié)議能提供100%的識別成功率,因而得到了廣泛的應用。
本文提出了一種時間優(yōu)先級分組二進制樹搜索協(xié)議TGBS(Time-based Grouping Binary Splitting),該協(xié)議以確定性協(xié)議為基礎,首先根據(jù)進入閱讀器識別范圍內(nèi)的時間長短將范圍內(nèi)的標簽進行分組,然后再利用動態(tài)二進制樹搜索協(xié)議對組內(nèi)標簽進行識別。該協(xié)議對先進入閱讀器范圍內(nèi)的標簽先識別,符合先來先服務的思想。同時由于將眾多標簽先按時間分組,降低了各組內(nèi)標簽的沖突概率,縮短了識別時間。該協(xié)議實現(xiàn)簡單,標簽端開銷小,僅需要在每個標簽中設定一個時間計數(shù)器(分組計數(shù)器)。
1 二進制樹搜索協(xié)議
基于二進制樹的防沖突協(xié)議必須解決好以下三個問題:(1)沖突檢測方法,確定通信信道處于何種狀態(tài)(空閑、沖突、使用)。目前普遍采用曼徹斯特編碼來檢測沖突。(2)以何種策略來搜索樹。目前有確定地址法和隨機地址法。確定地址法以ID中的每一位(0或1)決定是搜索左子樹還是右子樹,具有吞吐率高,搜索樹深度確定的優(yōu)點,在二進制樹搜索協(xié)議中得到廣泛使用。(3)在一個沖突解決期CRI(Conflict Resolution in-Interval)內(nèi)到達的新標簽, 應以何種策略決定是否參與信道的競爭。可分為阻塞型信道訪問策略和自由信道訪問策略。前者要求在CRI內(nèi)到達的新標簽不能加入到當前CRI中, 直到當前CRI結束, 然后加入下一次CRI的信道競爭; 后者則是任何新到達的標簽都被加入到當前CRI競爭中。一般情形下,在二進制搜索協(xié)議中均假定RFID沖突解決過程有比較明顯的間歇性和突發(fā)性。如超市自動結帳系統(tǒng)、出入庫管理系統(tǒng)等每隔一段時間就會有一批數(shù)據(jù)集中到達, 在短時間內(nèi), 閱讀器必須讀出所有的數(shù)據(jù),然后閱讀器停止工作等待下一批數(shù)據(jù)的到達。因此可以假定“RFID系統(tǒng)在一個CRI內(nèi)不會有新的標簽到達”[6]。在上述前提下,出現(xiàn)了基本二進制搜索、動態(tài)二進制搜索、自適應二進制搜索等典型算法及其他改進算法[7]。下面的分析中假定標簽ID的長度為N,有M個標簽待識別。
1.1 基本二進制搜索算法
基本二進制搜索算法中,閱讀器發(fā)送一長度為N的查詢序列號,各個標簽將自身的ID與接收的序列號比較,其值小于或等于查詢序列號的標簽返回其ID。閱讀器檢測信道的沖突情況,按確定地址法先后選擇進入左子樹和右子樹,修正發(fā)出的查詢序列號,重復沖突檢測過程,直至識別出一個標簽(到達葉結點),然后將其去激活(不再響應閱讀器命令)。重復上述過程,直到完成所有標簽的識別(樹搜索)。
完成所有標簽的識別過程主要由閱讀器發(fā)出查詢命令的次數(shù)、發(fā)送命令參數(shù)的長度及標簽響應數(shù)據(jù)的長度決定。在基本二進制樹搜索協(xié)議中,閱讀器在發(fā)送的序列號和標簽返回的序列號長度均為N,而請求命令中最高沖突位后面的部分被置為1,對標簽的識別無用,同時標簽返回命令中最高沖突位的前部分對閱讀器來說是已知的,也是多余的。在識別出一個標簽后又從樹根開始下一輪的識別,沒有充分利用前面檢測到的沖突信息,來減少查詢次數(shù)。
1.2 對基本二進制搜索協(xié)議的改進
對二進制樹形搜索協(xié)議的改進主要從減少查詢次數(shù)、減少發(fā)送數(shù)據(jù)和響應數(shù)據(jù)的長度著手。
1.2.1降低通信數(shù)據(jù)位長度的改進
降低數(shù)據(jù)長度的改進協(xié)議主要有動態(tài)二進制搜索協(xié)議、引入預處理的二進制搜索協(xié)議、傳輸沖突位位置的二進制搜索協(xié)議[8]。
動態(tài)二進制協(xié)議中,閱讀器檢測到最高沖突位(假設第M位)后,下一次查詢命令的序列號是最高沖突位在前的(N-M)位加上1位0。各個標簽將自身ID號的前N-M+1位與查詢序列號比較,匹配標簽返回其序列號的后面M-1位。在一次發(fā)送和響應過程中,發(fā)送數(shù)據(jù)長度和標簽響應數(shù)據(jù)長度的和為N,與基本二進制協(xié)議中一次發(fā)送和響應數(shù)據(jù)的長度2N相比降低了50%。
預處理的二進制樹搜索協(xié)議在基本算法之前進行一次預處理:閱讀器第一次發(fā)送查詢命令,所有標簽都返回自己的ID,閱讀器檢測所有沖突位,有沖突的標簽為1,無沖突的標記為0。將此沖突信息發(fā)給各標簽,以后各標簽只返回有沖突標記的位。這樣也可降低發(fā)送和響應的數(shù)據(jù)位長度。
傳輸沖突位位置的二進制樹搜索協(xié)議在發(fā)送查詢命令時不是發(fā)送查詢ID或前綴,而是根據(jù)檢測到的沖突信息發(fā)送最高沖突位的位置信息,這對ID長度較長的標簽,也可降低發(fā)送的數(shù)據(jù)長度。
1.2.2 降低查詢次數(shù)的改進
降低查詢次數(shù)的方法主要有基于堆棧的二進制搜索、基于分組的二進制搜索等協(xié)議。
基于堆棧的二進制搜索協(xié)議[9]將搜索過程中發(fā)送的查詢命令參數(shù)放入堆棧,在識別出一個標簽從堆棧中取出上一次的查詢命令修改后即可進入另一右子樹的搜索,不需要再次從根結點搜索來識別下一個結點。這樣可以大大減少發(fā)送查詢命令的次數(shù)。
基于分組的二進制搜索協(xié)議[4,9-11]則是根據(jù)某種策略將待識別標簽進行分組,然后依次識別出各組標簽。分組后組內(nèi)標簽碰撞概率降低,再利用二進制搜索協(xié)議就可以降低查詢次數(shù)。如ABS協(xié)議、自適應多叉樹協(xié)議、不平衡完全區(qū)組協(xié)議。
此外降低查詢次數(shù)的協(xié)議是基于只有1位碰撞位的互斥特性,可以直接識別兩個標簽。
2 時間優(yōu)先級分組的二進制搜索協(xié)議
隨著RFID在物聯(lián)網(wǎng)中的大量應用,出現(xiàn)了這樣一種場景[12]:在RFID應用于物流生產(chǎn)線、傳送帶、物流等快速移動領域時,多個標簽以分組的形式快速進入閱讀器的識別范圍內(nèi),然后又快速移出。如圖1所示。虛線表示閱讀器的閱讀范圍,多個標簽以分組的形式(如一個托盤)依次通過閱讀器。

在這種場景下,使以前的二進制搜索協(xié)議遇到了挑戰(zhàn)。“RFID系統(tǒng)在一個 CRI 內(nèi)不會有新的標簽到達”這一假定不太適用。在標簽快速移動的場景下,在識別前一標簽組的過程(沖突解決期)內(nèi)有新的標簽到達,而新進入的標簽采用自由信道訪問策略則會加大先進入標簽組的識別延時。如圖2所示。
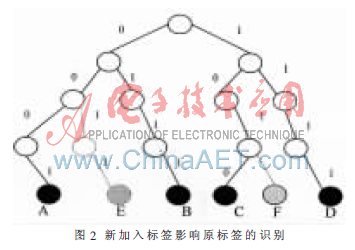
當先進入的標簽A、B、C、D利用二進制搜索協(xié)議識別標簽B時,有兩個標簽E、F進入,其中標簽E位于B的左邊,標簽F位于標簽B的右邊。此時由于標簽E的ID前綴與查詢前綴ID不匹配,將不影響B(tài)右邊結點的C、D的識別延遲。但結點F的加入,造成了和結點C、D的沖突,為解決此沖突,加大了識別結點C和D的延遲時間。如果進一步考慮識別出結點F后閱讀器的讀寫數(shù)據(jù)的通訊時間,則識別結點D的時間將進一步延遲。若有多個后進入的標簽都位于結點D的前面,就可能導致結點D已經(jīng)離開閱讀器的讀寫范圍,造成漏讀。但由于標簽在快速移動,導致標簽離開了閱讀器的識別范圍,從而導致了漏讀現(xiàn)象。因此,必須對二進制搜索協(xié)議進行改進。
時間優(yōu)先級二進制協(xié)議采用先進先出FIFO(First In First Out)的服務原則,結合標簽分組識別的思想,按照標簽進入閱讀器閱讀范圍的時間長短進行確定識別優(yōu)先級,并根據(jù)優(yōu)先級將標簽劃分為若干待識別標簽組,按照時間優(yōu)先級的高低依次識別各組標簽。該協(xié)議與二進制搜索協(xié)議的實現(xiàn)過程不同的地方有:
(1)在閱讀器中設置一查詢優(yōu)先級變量Q, 每個標簽中各設一個動態(tài)優(yōu)先級變量P。標簽在獲得能量后,將其動態(tài)優(yōu)先級P設定為0。
(2)閱讀器每隔一定時間T,發(fā)出一個優(yōu)先級更新命令,各標簽收到此命令后,將動態(tài)優(yōu)先級P加1。
(3)閱讀器在發(fā)送查詢命令時,除了發(fā)送查詢前綴外,還附加一查詢優(yōu)先級Q,Q的取值按照輪詢的方法來賦值即Q依次為Pmax,Pmax-1,…,1,0,其中Pmax為標簽中動態(tài)優(yōu)先級的最大值。
(4)標簽在響應查詢命令時,只有其動態(tài)優(yōu)先級P與查詢優(yōu)先級Q相符的標簽才返回其ID的后輟部分。
(5)對于相同優(yōu)先級的防沖突過程,采用基于堆棧的動態(tài)二進制搜索協(xié)議。
3 協(xié)議性能分析
二進制搜索協(xié)議的性能主要從降低識別延時和提高識別率來考慮,延遲時間主要由識別過程中要傳輸?shù)臄?shù)據(jù)量多少決定,具體由查詢命令次數(shù)及每次查詢中傳輸?shù)臄?shù)據(jù)位來決定。時間分組二進制搜索協(xié)議,在每次查詢命令參數(shù)中增加優(yōu)先級這一參數(shù),增加了每次的傳輸通信量,但由于將閱讀器范圍內(nèi)的標簽進行了分組,每組內(nèi)標簽的個數(shù)大大減少,降低了組內(nèi)標簽碰撞的概率,降低了查詢次數(shù),總體上降低了傳輸通信量,減少了識別延時。下面將時間分組二進制搜索協(xié)議與動態(tài)二進制搜索協(xié)議、基于堆棧的動態(tài)二進制搜索協(xié)議進行比較,以說明其性能的提高。設閱讀器范圍內(nèi)有N個標簽,標簽ID長度為L位,依據(jù)時間分組的組數(shù)為G。
對于動態(tài)二進制搜索協(xié)議,其查詢次數(shù)為N(N+1)/2, 每次查詢的數(shù)據(jù)量為(L+1)/2,則總的傳輸數(shù)據(jù)量S1為:
圖3顯示了堆棧動態(tài)二進制協(xié)議與時間分組二進制協(xié)議的通信數(shù)量。其中L為32位,P=4。可以看出識別一組內(nèi)標簽的數(shù)據(jù)量遠小于識別所有標簽的數(shù)據(jù)量,即識別延時大大降低。
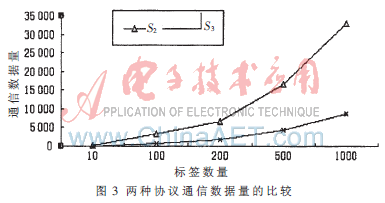
圖4顯示了在L=32,N=500的情況下,分組數(shù)P與數(shù)據(jù)量的變化關系。可以看出隨著分組數(shù)的增加,識別一組內(nèi)標簽所需的延時將急劇降低。

動態(tài)二進制搜索協(xié)議在面向越來越普及的快速移動的物聯(lián)網(wǎng)應用時遇到了漏讀率提高的新挑戰(zhàn)。本文提出了一種時間優(yōu)先級分組的二進制搜索協(xié)議TGBS。TGBS協(xié)議按照先來先服務(FCFS)的公平原則,將進入閱讀器范圍內(nèi)的多個標簽按進入時間的長短進行優(yōu)先級分組,并按優(yōu)先級高低進行分組識別。與動態(tài)二進制搜索協(xié)議相比,在標簽內(nèi)只需增加一個優(yōu)先級變量,電路實現(xiàn)簡單;閱讀器發(fā)送查詢命令時增加查詢優(yōu)先級參數(shù),盡管單次查詢發(fā)送的數(shù)據(jù)量有所增加,但分組后組內(nèi)碰撞標簽數(shù)大幅減少,后進入的標簽組不對先進入的標簽組產(chǎn)生識別干擾,可以有效地保證先進入的標簽能完整地正確識別,降低了標簽漏讀率。理論分析和仿真表明,在移動場景下在識別的準確率上,協(xié)議比動態(tài)二進制協(xié)議更優(yōu)。
參考文獻
[1] PRAPASSARA P, BELASTANTIC. Unified q-ary tree for RFID tag anti-collision resolution[C]. the 20th Australasian Database Conference.2009.
[2] 魏欣. RFID標簽及閱讀器防沖突算法研究[D].成都:電子科技大學,2009.
[3] 丁治國,朱學永,郭立,等.自適應多叉樹防碰撞算法研究[J]. 自動化學報,2010,36(2):237-241.
[4] 李世煜,馮全源,魯飛. 基于 BIBD(4,2,1)的 RFID防碰撞算法[J].計算機工程,2009,35(3):279-281.
[5] 向垂益,何怡剛,李兵,等.動態(tài)二進制樹搜索算法的改進[J]. 計算機工程, 2010,36(2):260-262.
[6] 馮波,李錦濤,鄭為民. 一種新的RFID標簽識別防沖突算法[J]. 自動化學報,2008,34(6):632-638.
[7] DONG Her Shih, SUN Po Ling, YEN D C. Taxonomy and survey of RFID anti-collision protocols[J]. Computer Communications,2006(29):2150-2166.
[8] SHI X L, SHI X W, HUANG Q L, et al. An enhanced binary anti-collision algorithm of backtracking in RFID system[J]. Progress In Electromagnetics Research B,2008(4):263-271.
[9] MYUNG J, LEE W J, SRIVASTAVA J. Adaptive binary splitting for effcient RFID tag anti-collision[J].IEEE Communications Letters,2006,10(3):144-146.
[10] WANG Tsan Pin. Enhanced binary search with cutthrough operation for anti-collision in RFID systems[J]. IEEE Communications Letters,2006,10(4):236-238.
[11] 尹君,何怡剛,李兵,等.基于分組動態(tài)幀時隙的RFID防碰撞算法[J]. 計算機工程,2009,35(20):267-269.
[12] 趙曦,張有光. 一種新穎的 RFID多標簽防碰撞算法[J].北京航空航天大學學報,2008(3):276-279.