
摘 要: 數(shù)據(jù)挖掘中的關聯(lián)規(guī)則挖掘近些年一直是人們研究的熱點。但是關聯(lián)規(guī)則挖掘的經(jīng)典算法Apriori存在著挖掘效率低、系統(tǒng)開銷大等問題。AprioriTid、DIC等算法,也僅從某一方面進行了改進。針對上述問題,提出了一種新的改進算法,新算法從三大方面對原有的算法進行了改進,以此提高算法的效率,降低系統(tǒng)的開銷。
關鍵詞: 數(shù)據(jù)挖掘;關聯(lián)規(guī)則; Apriori; AprioriTid; DIC
數(shù)據(jù)庫中大量的數(shù)據(jù)與數(shù)據(jù)之間存在著某種聯(lián)系,這種數(shù)據(jù)之間的聯(lián)系就屬于一種重要的知識,也是進行數(shù)據(jù)挖掘的對象,即關聯(lián)規(guī)則挖掘[1]。在眾多的關聯(lián)規(guī)則挖掘算法中最著名的是Apriori算法[2]。它的基本思想是使用一種逐層搜索的迭代算法。但是Apriori算法也有明顯的缺點:每次都會產(chǎn)生大量的候選頻繁項集,而且候選頻繁項集呈指數(shù)級增長。每產(chǎn)生一個頻繁項目集就需要掃描一次完整的數(shù)據(jù)庫。這些都需要耗費巨大的系統(tǒng)資源而且算法的執(zhí)行速度、效率也比較低。因此人們提出了許多改進的Apriori算法,本文吸取前人的經(jīng)驗提出了一種新的改進Apriori算法,稱為Apriori-Evo算法。
1 Apriori算法分析
Apriori算法的基本步驟是:首先掃描事務數(shù)據(jù)庫D中的事務,統(tǒng)計各個項目出現(xiàn)的次數(shù)來產(chǎn)生頻繁項目集L1,然后由L1×L1進行連接運算生成候選2-項集C2,掃描數(shù)據(jù)庫統(tǒng)計各個候選2-項集出現(xiàn)的次數(shù),確定其中的頻繁2-項集L2。再由L2×L2進行連接運算產(chǎn)生候選3-項集C3,一直反復進行這個過程生成頻繁k-項集Lk,直到無法再生成頻繁項目集為止。

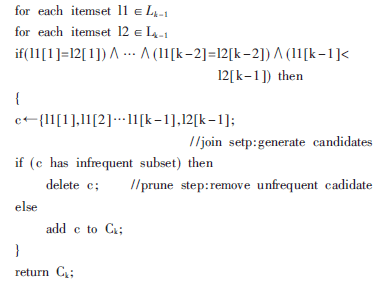
代碼中apriori_gen( )函數(shù)[3]主要完成兩個動作:連接和剪枝運算。Lk-1與Lk-1進行連接生成候選頻繁項集。然后剪枝部分利用Apriori的性質(zhì)刪除掉包含非頻繁子集的候選。
Apriori算法的主要缺點是會產(chǎn)生大量的候選項集,如果頻繁1-項集有10 000個,則候選2-項集的個數(shù)將超過10 000 000個,算法實現(xiàn)時,大量的候選2-項集都被存放在哈希樹中,對它們的統(tǒng)計和測試所需要的開銷會很大;每產(chǎn)生一個頻繁項目集就需要將整個事務數(shù)據(jù)庫掃描一遍,大大降低了系統(tǒng)I/O效率。
2 對Apriori算法的改進
關聯(lián)規(guī)則具有如下性質(zhì):
(1)對于項目集X和它的任意子集Y,如果X是頻繁的,則它的子集Y一定也是頻繁的。
(2)對于項目集X和它的任意子集Y,如果Y是非頻繁項目集,則X也一定不是頻繁項目集。
(3)X是k維項目集,如果頻繁項目集Lk-1中包含的X的子集個數(shù)小于k,則X不可能是頻繁項目集。
利用它的性質(zhì)對Apriori算法從以下三方面進行了改進。
(1)在剪枝階段減少掃描Lk-1的次數(shù)
進行剪枝的工作原理是:根據(jù)關聯(lián)規(guī)則的性質(zhì),Ck中的一個項集如果是頻繁項集,那么它一定有K個k-1項頻繁子集,且這K個k-1項頻繁子集一定都在Lk-1當中。因此以往的對Ck的剪枝過程都是先取出一個候選k項集,然后產(chǎn)生它的K個k-1項子集,再掃描一次Lk-1查看這K個k-1項子集是否都在Lk-1中,如果不是則剪掉這個候選k項集,如此循環(huán)。如果產(chǎn)生m條候選k項集,就需掃描Lk-1項集m次。然而頻繁項集具有性質(zhì)3[4]。所以不需要掃描Lk-1次。首先進行Lk-1×Lk-1的連接運算生成所有的候選項集Ck,然后取出Lk-1中的第一個頻繁k-1項集,查看該k-1項集是Ck中哪些k項集的子集,如果是子集,則對相應的k項集進行計數(shù)。然后再從Lk-1中取出第二個頻繁k-1項集,再到Ck中去查看它是哪些k項集的子集,直到Lk-1中的各個項集都比對完成。最后,查看Ck中的每個k項集,如果它的計數(shù)小于k,則它不可能是頻繁k項集,需要刪除。因為頻繁k項集一定有k個k-1項子集存放在Lk-1中。這樣整個剪枝步驟只需要掃描Lk-1一次,提高了剪枝步驟的效率和開銷。

(3)對用于連接的頻繁項目集進行精簡,減少無用候選的產(chǎn)生。
對于產(chǎn)生的頻繁項目集Lk-1,Apriori算法直接用它連接產(chǎn)生候選頻繁項目集Ck。但實際上Lk-1中的有些項目集已經(jīng)對產(chǎn)生Lk不起作用了,包含這些項目集的候選k-項集一定不是頻繁的,因此可以對頻繁項目集Lk-1進行精簡。
根據(jù)頻繁項集的性質(zhì)[7],當要用Lk-1連接產(chǎn)生Ck時,首先統(tǒng)計Lk-1中各個項目出現(xiàn)的次數(shù),如果該項目出現(xiàn)的次數(shù)小于k-1,則該項目所在的項目集不用來鏈接生成Ck[8]。


實驗結(jié)果表明,改進的Apriori-Evo算法確實在關聯(lián)規(guī)則數(shù)據(jù)挖掘的速度和效率方面有很大的提高,而且隨著事務數(shù)據(jù)的增多,提升效果更加明顯。
新的算法從三個方面對原有的算法進行了改進,減少了產(chǎn)生的候選頻繁項集Ck中項集的數(shù)據(jù),也減少了剪枝過程中的運算次數(shù),在統(tǒng)計支持度階段減少了需要掃描的數(shù)據(jù)庫中的事務數(shù)。而且計算機進行向量運算和位運算速度更快,程序也會更容易實現(xiàn)。實驗證明,新算法在系統(tǒng)的開銷和時間效率上都有很大的提高。
參考文獻
[1] HAN J,KAMBER M.數(shù)據(jù)挖掘:概念與技術[M]. 范明,孟小峰,譯.北京:機械工業(yè)出版社,2001.
[2] AGRAWAL R, IMIEL NSKI T , SWAM I A. Mining association rules between sets of items in large database[A]. In Proc. of the ACM SIGMOD Intl Conf. on Management of Data[C]. Washington D. C. , 1993:207-216.
[3] AGRAWAL R, SRIKANT R. Fast algorithms for mining association rules[C].Morgan Kaufmann, San Francisco, CA: Proceedings of the 24th International Conference on Very Large Databases,1998:478-499.
[4] 李緒成,王保保. 挖掘關聯(lián)規(guī)則中Apriori 算法的一種改進[J]. 計算機工程,2002,7(28):104-105.
[5] 羅芳,李志亮.一種基于壓縮矩陣的Apriori改進算法[J]. 科技資訊,2010(4):19.
[6] 劉以安,羊斌.關聯(lián)規(guī)則挖掘中對Apriori算法的一種改進研究[J].計算機應用,2007,27(2):418-420.
[7] 盛立,劉希玉,高明.挖掘關聯(lián)規(guī)則中AprioriTid算法的改進[J].山東師范大學學報(自然科學版),2005,20(4): 20-22.
[8] 葉福蘭,施忠興.Apriori算法的改進及應用[J].現(xiàn)代計算機,2009(9):95-126.