
0 引言
隨著遙感技術的發(fā)展,遙感圖像的分辨率也越來越高,。飛行器上搭載的遙感成像設備也從過去的低分辨率向現(xiàn)在的高分辨率在轉(zhuǎn)變,。遙感成像設備分辨率提高的同時,也對飛行器的數(shù)據(jù)下傳鏈路提出了更高的帶寬要求,。而相應的地面數(shù)據(jù)接受設備,,也需要具備對高速實時數(shù)據(jù)的存儲和處理能力。同樣在測試設備方面,,為了對大容量存儲設備進行高速數(shù)據(jù)的傳輸測試,,相應的地面檢測設備也應該具備高速數(shù)據(jù)的輸出功能。因此,,急需開發(fā)出具備高速實時數(shù)據(jù)接收和高速數(shù)據(jù)輸出功能的高速數(shù)據(jù)采集存儲系統(tǒng),。
從目前此類系統(tǒng)的技術指標來看,往往只能達到100Mbps到150Mbps的數(shù)據(jù)接收和數(shù)據(jù)輸出功能,。而根據(jù)目前的應用需求來看,,高速數(shù)據(jù)流的數(shù)據(jù)傳輸速率往往在200Mbps以上甚至達到300Mbps。對于這種高速數(shù)據(jù)流,,目前的系統(tǒng)就難以連續(xù)無錯的進行存儲和處理,,往往會因為數(shù)據(jù)傳輸速率超過系統(tǒng)能處理的極限,導致出現(xiàn)丟失數(shù)據(jù)或者系統(tǒng)功能不正常,,狀態(tài)不穩(wěn)定等問題,。
本文中介紹的高速數(shù)據(jù)采集存儲系統(tǒng)的設計目標就是對傳輸速率最高為300Mbps的數(shù)據(jù)流進行無錯接收存儲,并能實現(xiàn)最高為300Mbps的高速數(shù)據(jù)流輸出,以便于對大容量存儲設備進行檢測,。
1 系統(tǒng)總體介紹
高速數(shù)據(jù)采集存儲系統(tǒng)是在32位的計算機系統(tǒng)上實現(xiàn)的,,數(shù)據(jù)傳輸也是利用32位,33MHz的PCI總線來完成,。數(shù)據(jù)存儲是利用兩塊SATA接口的硬盤組成的RAID0磁盤陣列來實現(xiàn)的,。整個系統(tǒng)的核心是數(shù)據(jù)傳輸接口卡,它完成外部數(shù)據(jù)到計算機內(nèi)存的傳輸,。然后運行的驅(qū)動程序再將內(nèi)存中的數(shù)據(jù)存儲到硬盤上,。因此,,整個系統(tǒng)的設計也就分為數(shù)據(jù)傳輸接口卡的設計和驅(qū)動及應用程序設計兩大部分,。
2 數(shù)據(jù)傳輸接口卡設計
數(shù)據(jù)傳輸接口卡從功能上分為PCI總線接口,存儲緩沖區(qū),,中斷模塊,,傳輸控制模塊,緩沖區(qū)控制以及DMA控制六個模塊,,如圖2-1中所示,。當工作于數(shù)據(jù)輸入時,傳輸控制模塊根據(jù)緩沖區(qū)情況啟動傳輸,,傳輸過程中緩沖區(qū)控制模塊將數(shù)據(jù)讀出送到PCI總線上,,DMA控制模塊控制著PCI總線上數(shù)據(jù)傳輸?shù)倪M行。傳輸結(jié)束以后,,中斷模塊發(fā)出中斷信號提示驅(qū)動程序?qū)鬏數(shù)絻?nèi)存中的數(shù)據(jù)進行處理,。下面主要介紹PCI總線接口模塊,DMA控制模塊,,存儲緩沖區(qū)模塊以及傳輸控制模塊幾個核心模塊的設計,。
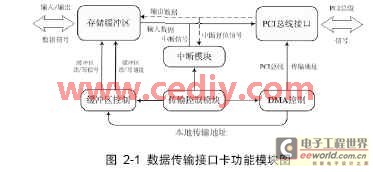
2.1 PCI總線接口模塊的設計
PCI總線接口模塊完成的工作主要是PCI總線命令的解碼,地址以及數(shù)據(jù)的鎖存,。實現(xiàn)PCI接口常用的方法是采用現(xiàn)成的PCI總線接口協(xié)議芯片(PLX905X系列等),,如文獻[2]中數(shù)據(jù)采集板的設計就是采用的這種方法。但是由于這些協(xié)議芯片往往不是針對空間應用而專門開發(fā)的,,從可靠性方面考慮,,不能采用這種設計方案。在本方案中,,整個接口的設計是在使用Xilinx公司提供的LogiCORE PCI v3.0的IP核(IP Core)的基礎上實現(xiàn)的,。LogiCORE PCI v3.0是Xilinx公司提供的用于PCI總線接口設計的IP 核,在它的基礎上可以根據(jù)實際應用的需要很方便的定制和實現(xiàn)PCI總線接口,。由于IP 核本身實現(xiàn)了配置空間以及總線命令的解碼和地址的鎖存,,所以設計者只需要專注于PCI傳輸狀態(tài)機和本地控制信號的設計。采用這種實現(xiàn)方式雖然比直接使用PCI接口專用芯片更為復雜,但是整個設計可以集成于一片高可靠性的FPGA之中,,從而有效的提高了整個設計的可靠性,。
2.2 DMA控制模塊的設計
為了滿足高速率數(shù)據(jù)傳輸?shù)男枰⑶以跀?shù)據(jù)傳輸?shù)耐瑫r不占用CPU,,所以必須采用DMA的方式來傳輸數(shù)據(jù),。由于PCI總線上的DMA傳輸是通過PCI設備本身的DMA控制功能來完成的,而不是依靠總線上單獨的DMA控制設備來實現(xiàn),,所以在設計時必須實現(xiàn)DMA控制模塊,。DMA控制模塊在數(shù)據(jù)傳輸周期發(fā)出控制命令以及更新地址。其中傳輸?shù)刂房刂瓶梢砸蕾囈唤M傳輸?shù)刂芳拇嫫鱽韺崿F(xiàn),,而傳輸?shù)目刂瓶梢酝ㄟ^PCI傳輸狀態(tài)機給出的信號來產(chǎn)生控制信號,。
2.3 存儲緩沖區(qū)模塊的設計
為了保證數(shù)據(jù)的連續(xù)不間斷傳輸,每次傳輸只傳輸半個緩沖區(qū)的數(shù)據(jù),,而外部數(shù)據(jù)總是在兩個半?yún)^(qū)之間切換儲存,,因此不會造成數(shù)據(jù)的丟失和不連續(xù)。
一個典型的PCI總線上的寫數(shù)據(jù)傳輸時序如圖2-2中所示,。首先用于傳輸?shù)臄?shù)據(jù)必須要提前從本地的緩沖區(qū)中讀出,,然后出現(xiàn)在總線AD信號線上,當IRDY信號和TRDY信號同時有效時(為低電平時),,被目標設備獲取,。當傳輸結(jié)束時,最后一個從本地緩沖區(qū)中預讀出的數(shù)據(jù)(如圖中陰影的數(shù)據(jù)3),,并不會被傳輸?shù)侥繕嗽O備,。而本地的緩沖區(qū)控制模塊會認為數(shù)據(jù)已經(jīng)傳輸,這時如果不采取措施就會導致數(shù)據(jù)丟失,。
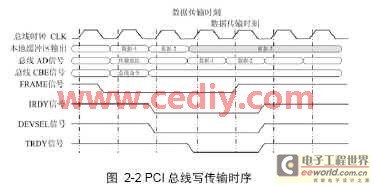
在傳輸結(jié)束的時候,,PCI總線傳輸狀態(tài)機會切換到備份數(shù)據(jù)的狀態(tài),在這個狀態(tài)下,,緩沖區(qū)的控制模塊會檢測是否存在已經(jīng)讀出而未傳輸?shù)臄?shù)據(jù),,如果存在這樣的情況,控制模塊則采取措施防止數(shù)據(jù)丟失,。對于雙口RAM這種存儲結(jié)構(gòu)而言,,數(shù)據(jù)讀出以后,只要沒有在同一地址寫入數(shù)據(jù),,那么數(shù)據(jù)是不會丟失的,,因此要實現(xiàn)前面的功能只需要簡單的修改一下讀指針目前指向的地址就可以實現(xiàn)。
2.4 傳輸控制模塊的設計
傳輸控制模塊的核心是一個傳輸控制狀態(tài)機,。它通過檢測存儲緩沖區(qū)的情況,,來控制傳輸?shù)倪M行,。當輸入緩沖區(qū)中數(shù)據(jù)存儲滿或輸出緩沖區(qū)空以后,自動請求一次數(shù)據(jù)傳輸,,由此保證數(shù)據(jù)流的連續(xù),。
3 驅(qū)動與應用程序的開發(fā)
驅(qū)動程序的開發(fā)是采用標準的WDM(Windows Driver Model)設備驅(qū)動程序模型,利用DriverStudio的驅(qū)動程序開發(fā)工具包來進行開發(fā)的,。關于WDM的驅(qū)動程序模型,,限于篇幅的原因就不作詳細的介紹。
一個典型的數(shù)據(jù)傳輸過程是這樣進行的,。首先驅(qū)動程序完成設備的初始化,,如在內(nèi)存中開辟緩沖區(qū),硬件設備的初始化等等,。完成初始化以后硬件就處于等待傳輸?shù)臓顟B(tài),。當用戶通過應用程序發(fā)出傳輸數(shù)據(jù)的指令以后,驅(qū)動程序處理這一請求,,并對硬件發(fā)出指令開始數(shù)據(jù)傳輸,。由于數(shù)據(jù)傳輸?shù)臅r間可能比較長,所以應用程序采用多線程的設計,,傳輸線程會等待驅(qū)動程序在傳輸結(jié)束時發(fā)出的信號,而同時應用程序還能完成與用戶的交互工作,。當傳輸結(jié)束后,,驅(qū)動程序向硬件寫入停止指令,中止傳輸,,并向應用程序發(fā)出傳輸結(jié)束信號,。驅(qū)動程序?qū)贸绦虻耐ㄐ攀峭ㄟ^創(chuàng)建Win32事件來實現(xiàn)通信的。
4 設計的仿真和驗證
為了驗證設計的正確性,,首先需要對設計進行邏輯功能仿真,。為了驗證設計是否能正常的工作在PCI總線上,那么就需要仿真PCI總線上的各種總線事務,,驗證設計是否能響應各種總線命令,。仿真是在Xilinx公司提供的PCI總線接口仿真實例的基礎上實現(xiàn)的。按照PCI總線規(guī)范設計了一個簡單的總線仲裁器,,用來仿真主設備申請總線占用的過程,。此外還設計了一個PCI總線上的從設備,用來仿真主設備與從設備之間的數(shù)據(jù)傳輸過程,。此外還仿真了總線上對設備的自動配置過程,。通過觀察仿真波形圖,發(fā)現(xiàn)設計完全滿足PCI總線的數(shù)據(jù)傳輸規(guī)范,,而且數(shù)據(jù)傳輸?shù)慕Y(jié)果正確,。
在仿真驗證正確的基礎上,,將設計實現(xiàn)于Xilinx公司型號為virtexII2v1000-fg456-5的FPGA中。將數(shù)據(jù)接口卡安裝于測試計算機上,,利用數(shù)據(jù)接口卡的自回路數(shù)據(jù)傳輸功能以及單向輸入輸出功能,,對系統(tǒng)進行了驗證和性能測試,結(jié)果如表格1中所示,。
從結(jié)果可以看出,,當輸入輸出速率保持在160Mbps以下時,可以保證自身回路數(shù)據(jù)傳輸無錯進行,,但是當速率提高到200Mbps以后,,傳輸就會出現(xiàn)數(shù)據(jù)丟失,導致接收的數(shù)據(jù)與發(fā)送數(shù)據(jù)不一致,。因此,,為了保證數(shù)據(jù)的無錯傳輸,自身回路數(shù)據(jù)傳輸測試速率應該不高于160Mbps,。
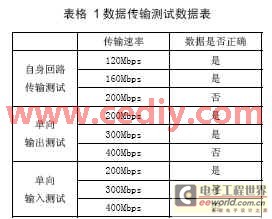
單向輸入輸出測試時,,當輸入速率或者輸出速率小于300Mbps,系統(tǒng)的功能是完全正確的,,而當工作于400Mbps的時候,,則會出現(xiàn)數(shù)據(jù)丟失的情況。與自身回路傳輸測試的數(shù)據(jù)比較可以看出,,當在自身回路數(shù)據(jù)傳輸測試速率為200Mbps的時候,,由于此時系統(tǒng)接收和輸出同時進行,共同分時使用總線,,此時相當于單獨接收或者單獨輸出測試時400Mbps的傳輸速率,。兩次測試結(jié)果的一致性也說明了測試的可靠性。
5 結(jié)語
通過對系統(tǒng)的測試驗證,,證明了本設計能夠完全滿足高速實時數(shù)據(jù)流對數(shù)據(jù)采集存儲系統(tǒng)的要求,。為了方便以后進一步的工作,在測試時也對緩沖區(qū)大小和傳輸速率之間的關系進行了簡單的測試,。將緩沖區(qū)大小從8KB改變到16KB以后,,傳輸速率只是稍微有些提高,對性能的改善十分不明顯,。結(jié)果說明簡單的擴大硬件緩沖區(qū)并不會帶來數(shù)據(jù)傳輸速率的明顯改觀,,同時還會占用FPGA內(nèi)部寶貴的RAM資源。究其原因在于,,數(shù)據(jù)傳輸速率主要受到32位/33MHzPCI總線帶寬自身的限制,,以及硬盤讀寫的峰值速率的限制,而并不是緩沖區(qū)大小的影響??梢灶A見如果采用64位/66MHz的PCI總線并采用更多的磁盤來構(gòu)成RAID磁盤陣列以提高磁盤讀寫速率,,那么整體的性能會有很大的提升,。