
摘 要: 局部嵌入分析(LEA)是圖嵌入化的局部線性嵌入(LLE)方法。在頭姿態(tài)估計(jì)問題上,選擇局部鄰域時(shí)只考慮屬于同一類的姿態(tài),但失去了相鄰姿態(tài)的幾何拓?fù)湫畔ⅰ榇耍岢鲆环N改進(jìn)的鄰域選擇方法,充分利用先驗(yàn)姿態(tài)信息,使降維后的流形更加平滑,同類姿態(tài)互相靠近,不同類姿態(tài)之間的距離隨著姿態(tài)差值變大而增大,且能夠使訓(xùn)練及測(cè)試樣本的低維流形更加靠近,降低了估計(jì)誤差。在Facepix人臉數(shù)據(jù)庫(kù)上的實(shí)驗(yàn)證明了該方法的有效性。
關(guān)鍵詞: 頭部姿態(tài)估計(jì);流形學(xué)習(xí);圖嵌入;局部嵌入分析;局部線性嵌入
頭部姿態(tài)估計(jì)是計(jì)算機(jī)視覺和圖像模式識(shí)別領(lǐng)域中的一個(gè)重要研究課題,近年來受到了越來越多的關(guān)注[1]。在人臉識(shí)別中,如果得到的人臉圖像是非正面的,識(shí)別的效果會(huì)大大降低,而如果預(yù)先估計(jì)人臉姿態(tài)后選擇合適的視角模型進(jìn)行識(shí)別,將會(huì)提高非正面人臉的識(shí)別率[2]。由于通過人臉的姿態(tài)可以得知人注視的方向,所以姿態(tài)估計(jì)在理解人的注意力等方面有很高的研究?jī)r(jià)值。
對(duì)于頭部姿態(tài)估計(jì)問題,現(xiàn)有的方法大致可分為基于表觀的方法和基于模型的方法兩大類[3]。基于表現(xiàn)的方法是通過對(duì)含有各種姿態(tài)的人臉圖像進(jìn)行學(xué)習(xí),建立一個(gè)能夠估計(jì)姿態(tài)的分類器。這種方法對(duì)圖像的分辨率要求不高,并且不需要或者需要較少的面部特征點(diǎn),能夠估計(jì)角度較大范圍的姿態(tài)。基于模型的方法是利用某種幾何模型來表示人臉的結(jié)構(gòu)和形狀,并通過提取某些特征,在模型和圖像之間建立起對(duì)應(yīng)關(guān)系。這種方法嚴(yán)重地依賴于特征點(diǎn)的定位結(jié)果,當(dāng)圖像旋轉(zhuǎn)較大角度時(shí),部分面部特征將丟失,無法進(jìn)行估計(jì),所以估計(jì)的姿態(tài)范圍較小。
1 基于流形學(xué)習(xí)的頭部姿態(tài)估計(jì)
基于流形學(xué)習(xí)的頭部姿態(tài)估計(jì)屬于表觀類方法,它的基本思想是考慮每個(gè)高維頭姿態(tài)圖像都處于一個(gè)有姿態(tài)變化的連續(xù)流形中。目前已經(jīng)吸引了一些學(xué)者對(duì)它進(jìn)行研究,例如HU N等人[4]提出了通過對(duì)特定人的姿態(tài)流形的學(xué)習(xí),在假定姿態(tài)流形不變的情況下,利用預(yù)測(cè)網(wǎng)絡(luò)來估計(jì)其他人的圖像的姿態(tài)的方法;FU Y[5]等使用了圖嵌入GE(Graph Embedding)[6]結(jié)合流形學(xué)習(xí)算法進(jìn)行人臉的姿態(tài)估計(jì)研究。
流形學(xué)習(xí)LLE[7](Locall Linear Embedding)算法是通過建立局部鄰域權(quán)重圖將數(shù)據(jù)由高維降至低維,但其鄰域均采集自同一流形,對(duì)于姿態(tài)估計(jì),這將導(dǎo)致姿態(tài)估計(jì)與人有關(guān)。FU Y[5]等人提出了一種改進(jìn)的LLE即LEA(Locall Embed Analysis):利用數(shù)據(jù)集的已知類別信息選擇局部鄰域時(shí),只考慮屬于同一類(即同一姿態(tài))的數(shù)據(jù)點(diǎn),并結(jié)合圖嵌入理論,使改進(jìn)后的LLE近似線性。這樣對(duì)于姿態(tài)估計(jì)將大大提高姿態(tài)估計(jì)的身份無關(guān)性。但這又帶來一個(gè)新的問題:屬于同一類的數(shù)據(jù)集映射到低維空間中后,退化成為一點(diǎn),失去了幾何拓?fù)湫畔ⅲ⑶宜朽徲蚓鶠橥悩颖?即不同人的相同姿態(tài)),這使得降維后的流形失去了其相鄰姿態(tài)間的平滑性。
本文對(duì)FU Y等人提出的LEA方法做了進(jìn)一步的改進(jìn):由于鄰域的選擇是流形學(xué)習(xí)算法至關(guān)重要的第一步,關(guān)系到鄰域樣本權(quán)值的計(jì)算及最后的降維結(jié)果。因此,本文在構(gòu)造鄰域時(shí)通過改進(jìn)鄰域距離表示方法,更好地選擇鄰域,使樣本的鄰域更好地重構(gòu)樣本本身,以解決LEA降維后的流形不能很好地保持高維時(shí)所具有的幾何拓?fù)浣Y(jié)構(gòu)的不足,并使訓(xùn)練流形和測(cè)試流形更加靠近,減少姿態(tài)估計(jì)誤差。



對(duì)于頭部姿態(tài)估計(jì)問題,本文提出算法的流程為:
(1)訓(xùn)練姿態(tài)流形
①裁剪圖片,使圖片僅包含頭部姿態(tài)部分,并對(duì)圖片預(yù)處理、歸一化,使所有圖片有相同大小。
②提取特征作為訓(xùn)練特征(也可以不提取,直接用圖片像素作為特征),并將特征用一個(gè)列向量來表示。
③根據(jù)式(6)計(jì)算樣本點(diǎn)之間的距離,求出鄰域矩陣,接著求解式(3),計(jì)算權(quán)值矩陣,然后求解式(5)計(jì)算投影矩陣P。
④應(yīng)用Y=PTX,計(jì)算低維映射Y。
(2)測(cè)試樣本姿態(tài)估計(jì)
①同訓(xùn)練步驟①,對(duì)測(cè)試圖片進(jìn)行裁剪、預(yù)處理、歸一化等操作。
②應(yīng)用投影矩陣P計(jì)算出測(cè)試樣本的低維表示。
③應(yīng)用KNN分類器估計(jì)測(cè)試樣本姿態(tài)。
5 實(shí)驗(yàn)
5.1 人臉庫(kù)
為了驗(yàn)證算法的有效性,本文在FacePix人臉姿態(tài)數(shù)據(jù)庫(kù)上進(jìn)行了實(shí)驗(yàn)。FacePix人臉庫(kù)是2005年由CUbiC(the Center for Cognitive Ubiquitous Computing)、Arizona State University提供,該人臉庫(kù)包含了不同姿態(tài)、不同光照的人臉,本文只介紹不同姿態(tài)的圖片:具體為30人,每人181張不同姿態(tài)的人臉圖像,姿態(tài)范圍為水平方向上從-90°~90°(負(fù)的表示向左旋轉(zhuǎn)),間隔為1°,共計(jì)5 430張分辨率為128×128的彩色人臉圖像。本文將圖片裁剪為32×32(人臉庫(kù)中的第16、21、27三人由于圖像采集不好,未被納入實(shí)驗(yàn)中)大小的圖片。人臉庫(kù)樣例及低維可視化流形如圖1所示。

5.2 實(shí)驗(yàn)結(jié)果及分析
(1)低維可視化效果
圖1(a)是FacePix人臉庫(kù)經(jīng)裁剪后的部分樣例圖,按照每行為同一人,每列為同一姿態(tài)排列,姿態(tài)從左到右分別為-90°、-60°、-30°、0°、30°、60°、90°;圖1(b)是FacePix人臉庫(kù)中第一個(gè)人的181張姿態(tài)圖像經(jīng)本文改進(jìn)的LEA算法降維后的三維嵌入流形,嵌入流形的圖片姿態(tài)按照-90°、-60°、-30°、0°、30°、60°、90°排列,鄰域K=80,特征為裁剪并處理后的灰度圖。由圖1(b)可以看出,不同姿態(tài)處在低維不同位置,且按照姿態(tài)順序呈流形分布。
(2)頭部姿態(tài)實(shí)驗(yàn)
訓(xùn)練及測(cè)試樣本三維流形如圖2所示,圖2實(shí)驗(yàn)選取的特征均為裁剪并處理后的灰度圖。圖2(a)為L(zhǎng)EA算法的低維嵌入圖,鄰域k=8,圖中顏色較深的線為人臉庫(kù)中前9個(gè)人的流形,為訓(xùn)練流形;顏色較淺的線為中間9個(gè)人應(yīng)用訓(xùn)練出的投影矩陣P投影后的結(jié)果,為測(cè)試流形。圖2(b)為本文改進(jìn)后的算法的嵌入圖,鄰域k=13,圖中不同顏色的含義同圖2(a)。通過圖中效果比對(duì)可以看出,改進(jìn)后的算法更能使測(cè)試樣本和訓(xùn)練樣本的相同姿態(tài)靠近,利于分類誤差的降低。

對(duì)LEA算法和改進(jìn)后的算法做相同條件下的對(duì)比試驗(yàn)。分別選取FacePix人臉庫(kù)中前9人、前12人、前15人、前18人做訓(xùn)練樣本,對(duì)應(yīng)的后18人、后15人、后12人、后9人做測(cè)試樣本,每人181張圖片。由于改進(jìn)后的算法仍是基于LLE算法的,所以鄰域、嵌入維數(shù)以及參與訓(xùn)練的圖片數(shù)對(duì)實(shí)驗(yàn)效果均有一定影響。實(shí)驗(yàn)中的特征均為裁剪并處理后的灰度圖。表1為實(shí)驗(yàn)的姿態(tài)估計(jì)平均誤差表。
圖3中實(shí)驗(yàn)為:低維維度m=14,訓(xùn)練樣本為9個(gè)人1 629張圖片,測(cè)試樣本為18個(gè)人3 258張圖片,LEA算法鄰域取k=8,改進(jìn)算法鄰域取k=10。圖中實(shí)線為L(zhǎng)EA算法姿態(tài)估計(jì)誤差,其平均誤差為3.44°;虛線為改進(jìn)算法姿態(tài)估計(jì)誤差,其平均誤差為2.99°(如表1所示)。
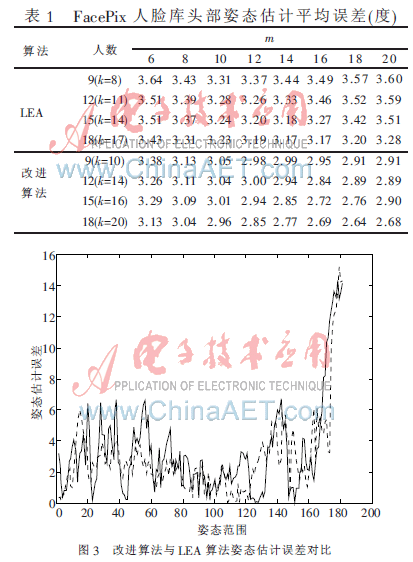
從表1及圖3可以看出,改進(jìn)后的算法與原來的算法相比,其誤差降低不少。主要原因:如圖2所示,由于LEA算法的鄰域取自同姿態(tài)樣本,其缺點(diǎn)是降維后同類樣本重合在一起,理論上是類間距離越小越好。但是由于人的差異性,同樣的姿態(tài)不同的人會(huì)有差距,所以導(dǎo)致訓(xùn)練出的流形與測(cè)試樣本的流形有很大差距。改進(jìn)算法由于適當(dāng)擴(kuò)大鄰域,既包括同類樣本又包括姿態(tài)相近的樣本,這樣訓(xùn)練流形與測(cè)試流形的差距就會(huì)縮小。
本文提出了一種對(duì)局部嵌入分析(LEA)算法改進(jìn)的頭部姿態(tài)估計(jì)方法(即一種新的鄰域選擇方法),在鄰域選擇時(shí)充分利用先驗(yàn)姿態(tài)信息,使降維后流形更加符合高維時(shí)的姿態(tài)間的幾何關(guān)系,降低姿態(tài)估計(jì)誤差。由實(shí)驗(yàn)可知,本文對(duì)LEA算法改進(jìn)的有效性。然而由于流形學(xué)習(xí)算法的實(shí)驗(yàn)結(jié)果與參數(shù)(如鄰域k、降維維度m等)有很大有關(guān),并且數(shù)據(jù)庫(kù)由于圖像裁剪不同,實(shí)驗(yàn)效果也不盡相同,因此算法還有待進(jìn)一步的研究與探討。
參考文獻(xiàn)
[1] CHUTORIAN E M, TRIVEDI M M. Head pose estimation in computer vision: a survey[J]. IEEE transactions on Pattern Analysis and Machine Intelligence, 2009,31(4):607-626.
[2] LI S Z, FU Q D. Kernal machine based learning for multi-view face detection and pose estimation[C]. Proceedings of 8th IEEE International Conference on Computer Vision. Vancouver, Canada: 2001.
[3] 馬丙鵬. 基于表觀的人臉姿態(tài)估計(jì)問題研究[M].北京:中國(guó)科學(xué)院,2009.
[4] HU N, HUANG W, RANGANATH S. Head pose estimation by non-linear embedding and mapping[C]. Proceeding. IEEE International Conference on Image Processing. 2005.
[5] FU Y, HUANG T S. Graph embedded analysis for head pose estimation[C]. Proceeding. IEEE International Conference on Automatic Face and Gesture Recognition. 2006.
[6] YAN S, XU D, ZHANG B, et al. Graph embedding: a general framework for dimensionality reduction[C]. IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 2005.
[7] ROWEIS S,SAUL L. Nonlinear dimensionality reduction by locally linear embedding [J]. Science, 2000,290:2323-2326.