
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2011)08-0056-03
數(shù)字視頻縮小和放大(簡(jiǎn)稱縮放)是視頻處理的一個(gè)重要分支,是基于對(duì)數(shù)字視頻每幀圖像的處理來(lái)實(shí)現(xiàn)的。常見(jiàn)的縮放算法有最近鄰域法、雙線性插值法、拋物線插值法、雙三次插值法和牛頓插值法等基于多項(xiàng)式的插值算法[1],較容易在FPGA硬件上實(shí)現(xiàn);也有B樣條插值法、基于小波插值和有理插值等比較復(fù)雜的算法,難以在FPGA上實(shí)現(xiàn)。
近年來(lái)隨著液晶平板顯示器件的廣泛應(yīng)用,對(duì)于定標(biāo)器的研究越來(lái)越多且研究成果也很豐富。但定標(biāo)器的縮放比例有限,一般在0.5~4之間,在這個(gè)范圍內(nèi)采用2階或3階多點(diǎn)插值算法,圖像的邊緣和細(xì)節(jié)可以較好保存。但是采用定點(diǎn)插值法,當(dāng)文字縮小比例較大時(shí),會(huì)丟失較多的細(xì)節(jié),出現(xiàn)字體筆畫(huà)斷裂或者鋸齒現(xiàn)象。而采用低階算法(例如多點(diǎn)均值插值),參與運(yùn)算的點(diǎn)較多,可以有效提高文字的顯示質(zhì)量。
1 系統(tǒng)架構(gòu)
系統(tǒng)架構(gòu)如圖1所示,先對(duì)輸入視頻的分辨率進(jìn)行檢測(cè),將檢測(cè)值送至MCU,MCU用其確定縮放步長(zhǎng);然后對(duì)視頻進(jìn)行縮小操作。如果要對(duì)信號(hào)進(jìn)行放大,則繞過(guò)該模式;接著將視頻數(shù)據(jù)送至IFIFO緩存,由仲裁器和DDR2控制器實(shí)現(xiàn)4個(gè)通道數(shù)據(jù)的幀率變換后,視頻數(shù)據(jù)送至OFIFO模塊;接著數(shù)據(jù)被送至放大模塊,完成放大操作。如果要對(duì)視頻信號(hào)進(jìn)行縮小,則繞過(guò)該模式;最后將完成處理的RGB視頻信號(hào)輸出。整個(gè)縮放過(guò)程所需要的縮放步長(zhǎng)、通道選擇等配置信號(hào)全部由MCU通過(guò)本地總線配置FPGA。


其中,f(x,y)為縮小圖像某點(diǎn)的像素值,f(xi,yi)為圖像子塊中各點(diǎn)的像素值。
實(shí)現(xiàn)結(jié)果如圖5所示,較好地保證了文字的正常顯示。

4 幀率變換
4.1 輸入緩存 IFIFO
每一路IFIFO都需要在FIFO中數(shù)據(jù)量大于1/2 FIFO深度時(shí)向仲裁模塊發(fā)送占用DDR2總線的請(qǐng)求信號(hào)REQ,應(yīng)答信號(hào)AGREE有效時(shí),向DDR2控制器發(fā)送數(shù)據(jù)。當(dāng)完成一定量的讀出數(shù)據(jù)時(shí),往仲裁模塊發(fā)送一個(gè)發(fā)送結(jié)束信號(hào)END,仲裁模塊接收到END信號(hào)后將DDR2總線控制權(quán)收回,IFIFO等待下一次應(yīng)答。
4.2 輸出緩存OFIFO
其實(shí)現(xiàn)原理與IFIFO類似,只是該模塊的輸入端工作在DDR2工作時(shí)鐘域,輸出模塊工作在幀率變換后的視頻圖像的像素時(shí)鐘域。
4.3 仲裁
共有4路輸入和4路輸出占用DDR2帶寬,需要?jiǎng)澐謺r(shí)間片來(lái)保證各個(gè)通道能夠順暢地顯示,優(yōu)先級(jí)依次為第1、2、3、4通道讀,第1、2、3、4通道寫(xiě)。本模塊采用狀態(tài)機(jī)控制,狀態(tài)機(jī)在上述8個(gè)狀態(tài)中循環(huán)跳轉(zhuǎn),然后跳回IDEL狀態(tài),開(kāi)始下一輪循環(huán)。
仲裁模塊的另一個(gè)任務(wù)就是讀寫(xiě)DDR2地址的生成。將DDR2的存儲(chǔ)空間劃分為4個(gè)部分,每個(gè)部分存儲(chǔ)一路視頻信號(hào),每路視頻信號(hào)存儲(chǔ)3幀。同時(shí)讀DDR2時(shí),命令設(shè)置為讀操作;寫(xiě)DDR2時(shí),命令設(shè)置為寫(xiě)操作。
現(xiàn)就一路視頻實(shí)現(xiàn)幀率變換討論如下:創(chuàng)建3個(gè)指針?lè)謩e指向3幀數(shù)據(jù)的DDR2空間基地址,系統(tǒng)啟動(dòng)時(shí),讀指針rd_pointer、當(dāng)前寫(xiě)指針current_wr_pointer和之前寫(xiě)指針pre_wr_pointer分別按照?qǐng)D6所示的狀態(tài)圖在3個(gè)基地址之間跳轉(zhuǎn)。

最近鄰域插值法存在很強(qiáng)的波瓣,頻率響應(yīng)較差。當(dāng)圖像中包含像素值有變化的細(xì)微結(jié)構(gòu)時(shí),最近鄰插值會(huì)在圖像中產(chǎn)生人為的痕跡,造成圖像模糊或產(chǎn)生人為噪聲點(diǎn)。
線性插值法頻譜的旁瓣遠(yuǎn)小于主瓣,帶阻特性較好。但通帶內(nèi)高頻成分衰減過(guò)快,會(huì)使得插值后的圖像變模糊。
四點(diǎn)立方插值通帶內(nèi)高頻成分衰減明顯變慢,且旁瓣不超過(guò)1%,具有較好的高頻響應(yīng)特性,縮放后的圖像能夠保持更多細(xì)節(jié)。
六點(diǎn)立方插值算法的頻率響應(yīng)特性更加優(yōu)越,通帶內(nèi)高頻成分衰減更慢且旁瓣更低。
四點(diǎn)立方插值較好地保持了圖像的細(xì)節(jié),實(shí)現(xiàn)難度和占用邏輯資源適中。六點(diǎn)立方插值雖然實(shí)現(xiàn)效果更好,但是占用的邏輯資源較多。故本設(shè)計(jì)采用四點(diǎn)立方插值算法實(shí)現(xiàn)視頻的放大操作。
5.2 插值基函數(shù)
圖像插值縮放具有二維可分解的特點(diǎn),可以將二維圖像的插值分解為分別沿x和y方向的一維信號(hào)插值[3]。一維方向上,利用插值點(diǎn)的四個(gè)臨近像素點(diǎn)進(jìn)行三次插值, Keys將sinc離散函數(shù)進(jìn)行泰勒級(jí)數(shù)展開(kāi)后,使三次分段多項(xiàng)式和原始信號(hào)的泰勒級(jí)數(shù)展開(kāi)式盡可能多項(xiàng)吻合,以此推導(dǎo)出插值基函數(shù)表達(dá)式[4]。
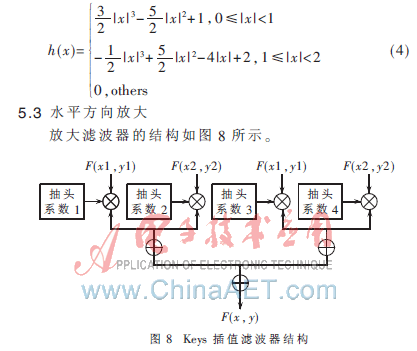
5.3.1 抽頭系數(shù)的產(chǎn)生
將插值的系數(shù)存在ROM中,這樣雖然使用三次方插值,但是不用在FPGA中實(shí)現(xiàn)三次方的運(yùn)算,提高了運(yùn)算速度。例如原圖像一行有3個(gè)像素,要求插值后的圖像一行有8個(gè)像素,則新圖像一行的第5個(gè)點(diǎn)在原圖像中映射的坐標(biāo)為[(5-1)×2/7]+1=15/7=2+1/7≈
′b0010.1001,整數(shù)2為其原圖像中左邊臨近的像素點(diǎn)坐標(biāo)為2,1/7表示其與坐標(biāo)為2的原圖像像素的距離為1/7。此時(shí)將小數(shù)部分1001作為地址讀出存儲(chǔ)在該地址的抽頭系數(shù),將其送給卷積器。
5.3.2 插值參考點(diǎn)控制
放大時(shí),對(duì)縮放步長(zhǎng)進(jìn)行累加,當(dāng)小數(shù)向個(gè)位數(shù)進(jìn)位時(shí),開(kāi)始讀取一個(gè)新的數(shù)據(jù)。例如計(jì)算插值后圖像某個(gè)點(diǎn)時(shí),采用原圖像的x4、x5、x6、x7作為插值參考點(diǎn),則當(dāng)步長(zhǎng)累加器有進(jìn)位時(shí),讀取下一個(gè)像素值x8,同時(shí)將x5、x6、x7移到x4、x5、x6的寄存器位置,而x8則存入之前x7的位置,這樣就可以實(shí)現(xiàn)從原圖像向目標(biāo)圖像的地址映射,避免從目標(biāo)圖像到原圖像地址映射過(guò)程出現(xiàn)的乘法運(yùn)算。
5.4 行緩存
行緩沖存儲(chǔ)器的主體為若干個(gè)存儲(chǔ)容量相同的雙口隨機(jī)存儲(chǔ)器(DRAM),每個(gè)DRAM存儲(chǔ)一行的有效像素?cái)?shù)據(jù)。
為了確保行緩存不溢出,開(kāi)辟6個(gè)行緩存器,存儲(chǔ)時(shí)按順序1-2-3-4-5-6-1循環(huán)存放,讀取時(shí)按循環(huán)次序讀取。
5.5 垂直方向放大
垂直方向放大濾波器架構(gòu)和水平方向一樣,只是插值參考點(diǎn)來(lái)自于不同的行緩存空間里相同地址的數(shù)據(jù)。
本文采用Xilinx公司的Virtex-5系列XC5VLX50T-1FFG1136C型號(hào)的FPGA實(shí)現(xiàn),可用用戶IO管腳480個(gè),滿足4路視頻信號(hào)輸入、4路視頻信號(hào)輸出和一路16 bit本地總線需求。內(nèi)部可用Slice 7 200個(gè), Block RAM Blocks最大為2 160 KB,滿足4路視頻信號(hào)每路緩存6行數(shù)據(jù)需求。輸入DVI視頻信號(hào)用Silicon Image公司的SiI 1161解碼成并行RGB數(shù)據(jù)送至FPGA,輸出的并行RGB視頻信號(hào)用SiI 1160編碼成DVI視頻信號(hào)輸出顯示。實(shí)驗(yàn)結(jié)果表明,在4個(gè)通道輸入均為352×288(CIF格式)分辨率、均放大為1 920×1 080輸出顯示時(shí),無(wú)方塊效應(yīng),輸出穩(wěn)定順暢;在4個(gè)通道輸入均為1 920×1 080分辨率、均縮小為352×288輸出顯示時(shí),畫(huà)面質(zhì)量良好,且文字筆畫(huà)圓潤(rùn),無(wú)筆畫(huà)斷裂或者模糊不清的現(xiàn)象。
參考文獻(xiàn)
[1] 林媛.圖像縮放算法研究及其FPGA實(shí)現(xiàn)[D].廈門(mén):廈門(mén)大學(xué),2006.
[2] 高健,茅時(shí)群,周宇玫,等.一種基于映射圖像子塊的圖像縮小加權(quán)平均算法[J].中國(guó)圖像圖形學(xué)報(bào),2006,11(10):1460:1463.
[3] 張輝,胡廣書(shū).基于二維卷積的圖像插值實(shí)時(shí)硬件實(shí)現(xiàn)[J].清華大學(xué)學(xué)報(bào)(自然科學(xué)版),2007,47(6):885:888.
[4] KEYS R G.Cubic convolution interpolation for digital image processing[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1981,29(6):1153-1160.