
摘 要: 提出了一種新的XML數(shù)據(jù)流XPath查詢模型GBRender,該模型通過組著色序列來直接處理元素,具有較高的處理效率與較強的適應性。
??? 關(guān)鍵詞: XML數(shù)據(jù)流;組著色;XPath查詢
?
由于XML已經(jīng)成為Web上數(shù)據(jù)交換的標準,用于各種應用和信息源之間的數(shù)據(jù)交換,而許多應用的特征是數(shù)據(jù)以快速、實時的數(shù)據(jù)流形式持續(xù)到達,適宜用數(shù)據(jù)流建模。因此,處理XML流數(shù)據(jù)的理論和技術(shù)目前成為流數(shù)據(jù)研究領(lǐng)域中的一個熱點。XML流數(shù)據(jù)處理系統(tǒng)通常運行在Web上,用戶查詢通常用XPath[1]語言表示。由于一個用戶可以提交若干查詢,使查詢的數(shù)量十分巨大。XML流數(shù)據(jù)處理研究的一個關(guān)鍵問題是如何同時有效處理大量來自用戶的查詢并及時將結(jié)果返回給用戶。
根據(jù)數(shù)據(jù)流環(huán)境的特點,對XML數(shù)據(jù)流和處理通常有以下要求:每一個XML元素節(jié)點最多只能訪問1次;使用有限和最少的內(nèi)存空間存儲臨時數(shù)據(jù),處理算法具有盡可能小的空間復雜度;對每個節(jié)點的處理必須有很高的效率,以滿足實時處理的需要。
目前針對XML流處理系統(tǒng)所采用的主要方法是基于自動機的方法。其他方法有:基于索引的方法[2]、基于Bloom-Filter[3]的方法、Fist[4]方法等[5]。基于自動機的方法是將1個或1組XPath表達式表示為某種形式的自動機,通過狀態(tài)轉(zhuǎn)換來達到查詢所需信息的目的。基于索引的方法是在數(shù)據(jù)傳送之前加入索引信息或接收端引入某種索引機制來提高查詢效率。以上方法處理XPath的方式都是通過對XPath本身形成處理器,即處理的過程主要集中在XPath本身,而且基于索引或通過DTD的優(yōu)化或多或少都依賴于對XML結(jié)構(gòu)信息的了解。而由XML數(shù)據(jù)流的應用環(huán)境決定了很多應用是在結(jié)構(gòu)未知的情形下的數(shù)據(jù)序列查詢。基于現(xiàn)有的研究及上述問題,本文提出了一種新的XML數(shù)據(jù)流XPath查詢模型,以適合在結(jié)構(gòu)未知的情況下的XPath查詢,同時有效地減少流查詢過程中對XPath的依賴程度。
1 背景及相關(guān)問題
由于流數(shù)據(jù)處理的廣泛應用以及XML已經(jīng)成為Web上數(shù)據(jù)交換的標準,流數(shù)據(jù)處理的研究已引起廣泛的興趣。
很多研究都采用自動機方法處理XML數(shù)據(jù)流。自動機技術(shù)用于XML文件查詢的主要思想是:將1個或1組XPath表達式表示為某種形式的自動機,在要查詢的XML文件上運行自動機,自動機根據(jù)當前狀態(tài)及讀入文檔的節(jié)點判斷下一步的行動,運行結(jié)束根據(jù)自動機是否處于接收狀態(tài)來判斷文件是否符合給定的XPath的查詢條件。自動機查詢模型如圖1所示。
?

??? XFilter首次利用基于有限狀態(tài)自動機FSM(Finite State Machine)的方法來過濾XML文檔,它對每一個路徑查詢使用一個單獨的FSM,并在文檔處理的過程中,同時運行所有的FSM。YFilter在XFilter的基礎(chǔ)上進行了改進,它將所有的XPath查詢合并成一個單獨的非確定有限自動機NFA(Non-deterministic Finite Automaton)[6],并共享所有查詢的公共前綴,YFilter主要考慮了謂詞中的AND謂詞查詢,采用后置處理的方式,這種方式產(chǎn)生大量中間結(jié)果影響系統(tǒng)性能。
XEBT(XPath Evaluation Based on Tree automata)[7]利用樹自動機技術(shù)作為查詢處理器,它基于表達能力豐富的樹自動機,無須附加中間狀態(tài)或保存中間結(jié)果,就能處理支持{[]}操作符的XPath,所以能較高效地處理XPath查詢。在優(yōu)化策略上,主要包括基于DTD的XPath查詢自動機的構(gòu)造、在空間代價有限增加的情況下采用局部確定化減少并發(fā)執(zhí)行的狀態(tài)、采用自上而下和自下而上相結(jié)合的查詢處理策略等。
其他處理XML流的方法主要有基于索引(Index-Filter)的方法[2]、基于Bloom Filter[3]的方法以及FiST[5]方法。Index-Filter[2]采用基于索引的技術(shù)處理XML流數(shù)據(jù),利用XML文檔流的文檔標記動態(tài)地建立XML文檔的索引,從而避免處理一部分文檔。在Index-Filter的方法中,建立索引要花費一定的時間,而且不能單遍處理XML文檔。基于Bloom Filter的XML包過濾器具一種近似查詢方法,利用Bloom Filter方法,將XPath表達式作為字符串,將XPath與XML包之間的匹配轉(zhuǎn)換為字符串之間的匹配,從而提高查詢性能,但它只是用來處理簡單的XPath表達式且有一定的失誤率。FiST方法針對Twig Pattern提出的一種有別于YFilter的方法,將一組Twig Pattern轉(zhuǎn)換為prufer序列,并對一組Twig Pattern與XML流數(shù)據(jù)進行整體性匹配。
2 GBRender模型
2.1 GBRender相關(guān)定義
當XML以流的形式進行處理時,在邏輯上實際是以先序遍歷的形式對XML樹中的結(jié)點進行訪問,通常采用基于事件的SAX模型來進行解析。這樣,在對XML結(jié)構(gòu)未知的情況下,可以根據(jù)接收的元素信息來分析其結(jié)構(gòu),并根據(jù)得到的結(jié)構(gòu)信息為后續(xù)服務(wù)。
??? 為了用來更好地描述GBRender查詢模型,下面介紹幾個定義:
??? 定義1(組):XML的任何一個元素都有一個從根開始的標簽路徑,但很多元素都會有相同標簽路徑,即1個標簽路徑可以表示1組對應的元素。這里把XML文檔中每一個不同的標簽路徑稱為組。如圖2所示,root/person/name即為一個組。
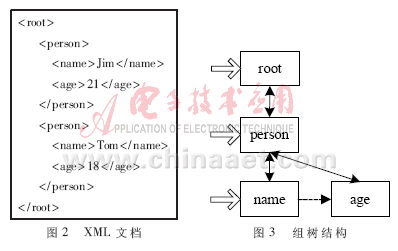
??? 定義2(組樹):組樹是在處理XML數(shù)據(jù)流過程中,記錄組、組之間關(guān)系的樹形結(jié)構(gòu)。其組織結(jié)構(gòu)如圖3所示。組樹中,各組有指向其子組的鏈接,每個組有指向父組的鏈接,同時,同一層的組串接起來以便于處理時的需要。
定義3(終結(jié)元素):XPath表達式對應的最后一個路徑元素,稱為終結(jié)元素,它表示XPath請求所需的結(jié)果。如//A/B//C,C即終結(jié)元素。
定義4(著色):尋找每一個組的標簽路徑處于XPath表達式中的哪個位置,即當前XML元素的路徑與XPath路徑的關(guān)系并標記該組,這個過程稱為著色過程。例如,組root/person/name對應XPath表達式//name的終結(jié)元素name,則可以標記該組為該XPath的終結(jié)組。
2.2 GBRender結(jié)構(gòu)模型
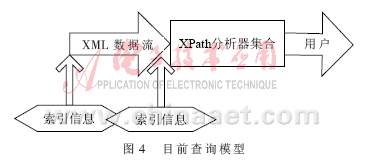
目前的XML數(shù)據(jù)流XPath查詢處理,基本結(jié)構(gòu)模型如圖4所示,以XML數(shù)據(jù)流作為XPath分析器的輸入,分析器可能有多個,也可能合并為1個。對XPath查詢包含的索引信息有2種:一是傳輸之前的索引信息;二是接收端進行處理形成的索引信息。
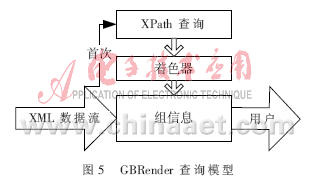
GBRender查詢模型如圖5所示,采用基于著色的方式來處理查詢,當某個組首次出現(xiàn)時,通過著色器對其與XPath的關(guān)系進行著色。著色之后,再次遇到該組時不再依賴于XPath而只依賴其記錄的組著色信息,尤其在單枝查詢的情況下,可以直接對查詢進行回應。在GBRender模型中,組著色的過程,實際上相當于XPath確定化的過程。例如,對于圖2的文檔進行//name查詢,當首次出現(xiàn)name時,其組標簽路徑為root/person/name,即是對//祖孫關(guān)系在此文檔上進行的確認化,而且當name出現(xiàn)在另一組時,會再一次進行確認化且不會相互影響。而常采用的DTD優(yōu)化策略通常也是完成確認化的工作,當遇到2個不同組均存在name標簽時,//就需要特殊處理了。
??? 為了同時響應多個XPath查詢,本文引入了著色序列的定義。
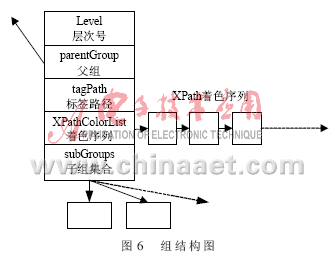
定義5(著色序列):根據(jù)XPath請求序列,對同一組生成對應的著色信息序列,此序列即稱為著色序列。因為不同的XPath有不同的著色信息,因此也稱XPath著色序列。
??? 每組均有著色序列,其組樹中組的結(jié)構(gòu)如圖6所示。
2.3 GBRender處理模型
??? 基于組樹的動態(tài)建立與組著色機制,GBRender的任意組,僅當首次出現(xiàn)時進行XPath著色處理,之后則根據(jù)著色情況進行處理。
GBRender的查詢處理,其數(shù)據(jù)輸入是XML的SAX解析事件流,包括startDocument、endDocument、startElement、endElement和Text事件,這里只給出GBRender處理模型在每一類事件的響應動作,而不討論數(shù)據(jù)緩存處理。
startDocument: initiate the GroupTree GT and context?? //初始化組樹GT
StartElement(element)?? // element為新接收元素
If(not existsGroup(element))InsertGroupAndDrawXpathColor(element);??
?? //如果不存在該組,則生成該組并進行著色產(chǎn)生著色序列
setCurrentElement(element); //置element為當前元素
??? Text (value)??? // 當前元素的值
?????? Add value into currentElement.currentValue;
?// 增加到當前元素值
? EndElement(element)??
?????? ProcessXPathColor(element);?? // 根據(jù)當前元素的著色序列信息進行處理
?????? setCurrentElement(element.parentGroup); //
??? EndDocument?
?????? cleanUp( );???? // 處理全部結(jié)束,清理
2.4 GBRender查詢模型的主要特征
? GBRender查詢模型處理的操作方向與目前主要的查詢處理不同,分析器并不是與XPath綁定,而是綁定到XML文檔結(jié)構(gòu)上,它對XPath只在組首次出現(xiàn)時進行著色的處理,之后則根據(jù)著色情況來進行處理。這種模型具有較強的靈活性,主要特點如下:
??? (1)對XML文檔結(jié)構(gòu)無需任何考慮。因為以接收的流數(shù)據(jù)為依據(jù)來動態(tài)建立組樹。根據(jù)XML流數(shù)據(jù)的順序性與元素之間關(guān)系的局部性,組樹的訪問總是發(fā)生在相鄰元素之間,因此效率很高。
??? (2)無需依賴XPath分析器。一旦著色,相當于就對該組進行了確定化。同時,對于簡單的XPath表達式在當前組即可直接判定作出處理。
??? (3)可以方便地利用現(xiàn)有的其他XPath查詢處理機制,如自動機模型。因為在某種程度上,著色類似確定化XPath,當處理復雜謂詞時,其著色信息處理可以方便地吸收自動機模型的思想。
??? (4)非常容易擴展XPath查詢數(shù)目,著色序列長度的增加對效率影響很小。
??? (5)方便進行類似關(guān)鍵詞查詢的流數(shù)據(jù)處理。如不考慮數(shù)據(jù)來源的結(jié)構(gòu),用戶只關(guān)心信息中的author或name的信息。本文模型可以很容易且高效的去完成處理,僅需傳入//author、//name的XPath表達式串,就可以應用于任意的XML流數(shù)據(jù)源。
3 GBRender的主要算法
以單枝查詢?yōu)槔喴榻BGBRender查詢模型中的著色算法與處理算法。
在單一分枝的查詢中,由于XPath表達式中僅有//與/關(guān)系,組標簽對于XPath路徑中的元素只存在3種關(guān)系,即無、中間元素或終結(jié)元素,而本文關(guān)心的正是那些終結(jié)元素且此處暫不需考慮緩存,為了便于描述,用Color.Empty、Color.Mid以及Color.End來表示2種著色狀態(tài)。
??? (1)單一分枝下的組著色算法:
??? GroupRendering(G, XPaths)
??? 輸入:組G是當前元素所在組,表達式串XPaths是XPath表達式集合
??? {
??? Foreach(xpath in XPaths)
??? {
??? ? If(G.tagPath not satisfy part xpath)?? //未發(fā)現(xiàn)匹配,e.tagPath為標簽路徑
??? ? G.XPathColorList.add(Color.Empty);
??? If(G.tagPath satisfy part xpath)?? //有匹配
??????? If(G.tagPath is 終結(jié)元素)?? //是終結(jié)元素
???????????? G.XPathColorList.add(Color.End);
????????? else???? //不是終結(jié)匹配但匹配中間元素
????????????? G.XPathColorList.add(Color.Mid);
??? }
??? }
??? (2)endElement時根據(jù)組著色情況對元素進行處理的算法:
??? ProcessXPathColor (G)
??? 輸入:組G是當前元素所在組
??? {
???? Foreach(color in G.XPathColorList)
???? {? //單枝查詢情況下只需要對Color.End元素進行處理
??????? Costomeri ++;? // XPath逐個對應
??????? If(color is Color.End)
??????? {
?????????? ToCustomer(Customeri,G.currentElement.Value); // 輸出結(jié)果
??????? }
??? }
??? }
4 實驗
本文實現(xiàn)了GBRender查詢模型并應用在單枝查詢上,軟件環(huán)境是Windows xp+eclipse3.3+jdk1.5。硬件環(huán)境是:聯(lián)想旭日410M筆記本電腦,配置為:CPU雙核T2080,內(nèi)存1 GB,硬盤120 GB。
??? 在實驗中,綜合了文檔大小與查詢數(shù)目的多少并與YFilter和Index-Filter作比較,結(jié)果發(fā)現(xiàn),當文檔相對較大時查詢數(shù)量無論多少,GBRender都顯得非常有效;當文檔相對較小而查詢數(shù)量較大時,GBRender與YFilter較為有效。實驗結(jié)果如圖7所示。
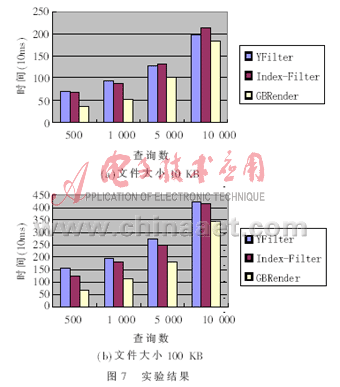
??? 本文提出了一種新的XML數(shù)據(jù)流XPath查詢模型GBRender,給出了該模型的結(jié)構(gòu)特征、處理機制以及單枝查詢下的多XPath查詢算法和組著色的概念。通過大量的實驗,證明了GBRender模型對XML任意數(shù)據(jù)流查詢的有效性及其適用性強的優(yōu)點。
??? GBRender模型具有較強的適應性與靈活性,對某些結(jié)構(gòu)簡單的XPath查詢極其有效。但在根據(jù)著色信息進行處理機制上有待進一步的研究。今后主要的工作是如何有效地在組著色機制中利用已有的好的查詢機制或新的有效的處理機制進行復雜XPath查詢處理,進一步完善系統(tǒng)。
參考文獻
[1] BERGLUND A, BOAG S, CHAMBERLIN D, et al. XML path language(XPath)2.0 W3C working draft 16. Technical Report,WD-xpath20-20020816,World Wide Web Consortium,2002.http://www.w3.org/TR/2002/WD-xpath2002-08-06.
[2] BRUNO N, GRAVANO L, KOUDAS N, et al. Navigation-vs. index-based XML? multi-query processing.In: Dayal U, Ramaritham K, Vijayaraman TM, eds.Proc of the 19th Int’l Conf. on Data Engineering(ICDE 2003). Bangalore: IEEE Computer Society, 2003:139-150.
[3] ZWON J, RAO P, MOON B, et al. FiST:scalable XML document filtering by sequencing twig patterns.Proc. of the 31st Int'l Conf on Very Large Data Bases (VLDB 2005).Trondheim:VLDB Endowment, 2005. 217-228.
[4] 楊衛(wèi)東,王清明,施伯樂.針對XML流數(shù)據(jù)的復雜Twig Pattern查詢處理.軟件學報,2007,18(4):893-904.http://www.jos.org.cn/1000-9825/18/893.htm
[5] DIAO Y, FISCHER P. YFilter: efficient and scalable filtering of XML documents. In: Proc of the 18th Int'l Conf. on Data Engineering, 2002:341-345.