
摘 要: 特征權(quán)重算法TF-IDF是文本分類的重要算法之一,該算法IDF值容易受特征噪聲影響出現(xiàn)波動(dòng)。提出一種基于特征噪聲加權(quán)的特征權(quán)重改進(jìn)算法,該算法通過分析噪聲特征的分布特點(diǎn),對(duì)不能準(zhǔn)確表達(dá)文檔真實(shí)意思的特征噪聲進(jìn)行加權(quán),降低特征噪聲對(duì)IDF的影響,最終有效地提高算法的精度和健壯性。
關(guān)鍵詞: 向量空間模型;文本分類;特征噪聲;特征權(quán)重;健壯性
隨著信息技術(shù)的發(fā)展,信息極度膨脹,人們迫切希望找到一種信息自動(dòng)處理技術(shù)。文本分類作為信息處理的技術(shù)之一,由于其能對(duì)信息進(jìn)行分類,使得獲取信息更加容易,因而得到廣泛應(yīng)用。在文本分類的算法中,空間向量法中的TF-IDF算法由于其以詞頻TF和逆文檔頻數(shù)IDF的乘積作為向量坐標(biāo)系的值,具有簡(jiǎn)單、直觀、處理速度快的優(yōu)點(diǎn),得到廣泛應(yīng)用。但在理論和實(shí)際應(yīng)用中有很大局限性,以至于其精度在各種文本分類中一直是較低的[1]。
本文針對(duì)噪聲特征對(duì)TF-IDF算法逆文檔頻率(IDF)影響進(jìn)行分析,提出了一種IDF加權(quán)方法,調(diào)整對(duì)IDF產(chǎn)生影響的特征噪聲權(quán)重,有效減少了算法對(duì)噪聲的影響,提高了TF-IDF算法的精度和健壯性。雖然已有很多研究者對(duì)TF-IDF算法做了改進(jìn),從特征選擇上減少噪聲特征的選擇,但特征噪聲在分類中出現(xiàn)是不可避免的。
1 向量空間算法的分析
向量空間算法的基本思想是用詞袋法表示文本,將文本看做特征空間的一個(gè)向量,用兩個(gè)向量之間的夾角來衡量?jī)蓚€(gè)文本之間的相似度。用TF-IDF值表示向量空間的一個(gè)特征值權(quán)重。
詞語(yǔ)權(quán)重計(jì)算唯一的準(zhǔn)則就是要最大限度地區(qū)分不同的文檔。所以針對(duì)詞語(yǔ)權(quán)重的計(jì)算,主要考慮3個(gè)因素[2]:
(1)詞語(yǔ)頻率tf(term frequency):該詞語(yǔ)在此文檔中出現(xiàn)的頻率。常用的計(jì)算方法是tf(Tk)=■;其中TF(Tk)表示特征Tk出現(xiàn)的頻率。
(2)詞語(yǔ)的倒排文檔頻率idf(inverse document frequency):該詞語(yǔ)在文檔中分布情況的量化,常用計(jì)算方法[3]為idf(Tk)=log2(N/nk+L)。其中N為文檔集合中的文檔數(shù)目;nk為出現(xiàn)過特征Tk的文檔數(shù)目;L根據(jù)實(shí)驗(yàn)來確定。
(3)歸一化因子(normalization factor):對(duì)各分量進(jìn)行標(biāo)準(zhǔn)化。
根據(jù)上述3個(gè)因素,可以得出:TF與IDF的聯(lián)合公式如下(其中i表示類別號(hào)):
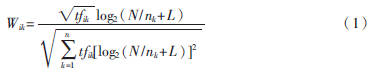
式(1)的提出基于這樣一種假設(shè)[2]:對(duì)區(qū)別文檔最有意義的詞語(yǔ)應(yīng)該是在文檔中出現(xiàn)頻率足夠高,但在整個(gè)文檔中出現(xiàn)頻率足夠少的詞語(yǔ)。所以向量空間模型的基礎(chǔ)是詞語(yǔ)的出現(xiàn)頻率和出現(xiàn)的文檔頻率[2],但同時(shí)一個(gè)文檔中的特征在不管出現(xiàn)的頻率多少與文檔頻率的計(jì)算無關(guān),文檔頻率的計(jì)算只與該特征在文檔中出現(xiàn)與否有關(guān)。而特征噪聲在文檔中出現(xiàn)一般是以較小的頻率出現(xiàn)。當(dāng)一個(gè)特征以特征噪聲的形式在大量文檔中出現(xiàn)時(shí)(該特征本不應(yīng)該在這些文檔中出現(xiàn)),文檔頻率計(jì)算出的值伴隨特征噪聲出現(xiàn)文檔數(shù)目的不同變化很大。由于沒有考慮特征受噪聲影響的程度,只是單純的以特征是否在文檔中出現(xiàn)為依據(jù)計(jì)算文檔頻率,文檔頻率就不能夠很好地在分類時(shí)起作用。
TF-IDF算法的IDF函數(shù)本質(zhì)是一種抑制噪聲的加權(quán)[3]。IDF函數(shù)認(rèn)為文檔頻數(shù)少的單詞就重要,而文檔頻數(shù)多的單詞就無用,這樣也使IDF值容易受噪聲的影響。文檔中的用詞本身帶有很大的隨意性,用與不用某個(gè)詞都行。大量的文檔本身就不規(guī)范,并含有很多不規(guī)范的用詞,導(dǎo)致降低了IDF值對(duì)單詞權(quán)重的區(qū)分。
2 特征權(quán)重算法的改進(jìn)
針對(duì)傳統(tǒng)算法沒有考慮噪聲影響,對(duì)特征特點(diǎn)進(jìn)行分析提出了改進(jìn)算法。
2.1 文檔特征分析
該文選擇了搜狗實(shí)驗(yàn)室—搜狐新聞數(shù)據(jù)900篇文檔進(jìn)行特征分析,選出一篇文檔Di,首先對(duì)Di進(jìn)行分詞預(yù)處理,進(jìn)行特征提取,特征降維。統(tǒng)計(jì)Di出現(xiàn)詞頻為t(t=1,2,3,…,10)的特征個(gè)數(shù)占該Di所有特征數(shù)Din的比例ri,且對(duì)所有文檔取平均值;然后進(jìn)行特征降維前后文檔的對(duì)比。
經(jīng)統(tǒng)計(jì)得出,在降維前出現(xiàn)詞頻為1的特征所占比例約80%;詞頻為1和2的特征共占約90%。通過降維后詞頻為1的特征所占比例有所降低,但仍然超過50%,詞頻為1和2的特征共超過60%。由此可見特征詞頻為1、2占特征總數(shù)的絕大部分,雖然可以通過各種算法降低特征數(shù),但降維后特征詞頻為1、2的仍然占特征總數(shù)的絕大部分。如果特征詞頻為1、2的特征屬于噪聲特征,這些特征在文檔中出現(xiàn)與否也許不會(huì)影響所在文檔的分類,但由于訓(xùn)練庫(kù)的文檔數(shù)非常多,這樣可能會(huì)造成文檔頻率DF出現(xiàn)較大波動(dòng),使得IDF值出現(xiàn)大的波動(dòng),擾亂TF-IDF算法的準(zhǔn)確性。
2.2 改進(jìn)方法
可以這樣認(rèn)為:當(dāng)特征詞頻TF較小時(shí)(例如TF=1),并不能有效地代表此特征在文檔中的重要性,有很大幾率是作者偶然性使用該特征;當(dāng)特征詞TF較大時(shí),很多次偶然使用同一特征詞的幾率不大,很可能是該文檔不得不使用該特征。由于文檔作者用詞具有很大的隨意性,可以很隨意用其他特征詞代替,從而很容易使TF較小的特征詞頻的TF=0,這一變化對(duì)IDF產(chǎn)生影響,如果詞頻TF在很多文檔中出現(xiàn)頻數(shù)很低,IDF值就更容易受文檔作者用詞的影響從而擾亂TF-ID特征值的計(jì)算,使TF-IDF特征值偏離代表分類權(quán)重的意義。
從上述分析可以得到文檔中大部分特征的詞頻為1或2,因此,如何降低噪聲特征影響對(duì)TF-IDF算法精度計(jì)算至關(guān)重要。
本文降低特征噪聲對(duì)IDF值計(jì)算影響的方法主要是通過對(duì)統(tǒng)計(jì)文檔頻數(shù)進(jìn)行加權(quán)。原算法文檔頻數(shù)計(jì)算值是統(tǒng)計(jì)特征在文檔集中出現(xiàn)的文檔數(shù),而改進(jìn)的算法是統(tǒng)計(jì)特征在文檔集中出現(xiàn)的加權(quán)文檔數(shù)。使噪聲特征降低對(duì)IDF值的影響,從而降低IDF的波動(dòng),提高TF-IDF算法的精度和穩(wěn)定性。
使用WIDF(加權(quán)反文檔頻率)代替IDF,WIDF的計(jì)算公式如下

實(shí)驗(yàn)在確定式(2)中的wi值時(shí),對(duì)Tk出現(xiàn)1和2的詞頻進(jìn)行處理,因?yàn)?和2的詞頻低,且在圖1中可以看出占用比例很大的更容易受噪聲影響。當(dāng)Tk在文檔中出現(xiàn)頻率為1時(shí),wi通過實(shí)驗(yàn)最終確定為0.5;頻率為2時(shí),通過實(shí)驗(yàn)最終確定為0.9;頻率大于2的詞頻通過實(shí)驗(yàn)確定的wi非常接近1,所以出現(xiàn)頻率大于2時(shí)wi取為1。
3 實(shí)驗(yàn)與分析
3.1 實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)所有語(yǔ)料來源于搜狗實(shí)驗(yàn)室—搜狐新聞數(shù)據(jù)(SogouC.reduced.20061127)選取財(cái)經(jīng)、IT、健康、體育、旅游、教育、招聘、文化、軍事9個(gè)大類,總共4 500篇文檔、其中1 800篇作為訓(xùn)練集(每個(gè)類200篇),余下的2 700篇(每個(gè)類300篇)文檔作為測(cè)試集。
3.2 評(píng)價(jià)指標(biāo)
實(shí)驗(yàn)采用分類精度來評(píng)估權(quán)重算法在不同類上的分類性能。分類精度的定義如下:

從表(1)可以看出在對(duì)2 700篇文檔進(jìn)行分類時(shí),當(dāng)K從50~75變化時(shí):TF-IDF算法錯(cuò)誤識(shí)別文檔數(shù)在366~380范圍變化,波動(dòng)范圍為14;TF-WIDF算法錯(cuò)誤識(shí)別文檔數(shù)在351~357范圍變化,波動(dòng)范圍為6;由此得出當(dāng)選不同k值時(shí)TF-WIDF算法比TF-IDF算法更加穩(wěn)定。
從表(2)中可以看出TF-WIDF權(quán)重算法結(jié)合k-NN分類器在各類別上的精確度P除了在健康、財(cái)經(jīng)有少許下降外大部分都有不同程度的提高,在所有類總體正確率提高0.004~0.008。可以得出TF-WIDF算法比TF-IDF算法更加精確,與本文使用已經(jīng)適當(dāng)優(yōu)化了傳統(tǒng)TF-IDF算法有關(guān),使其總體分類正確率高達(dá)0.864 4,在如此高的正確率下再提高任何一點(diǎn)都是非常困難的,而本文正是在如此高的正確率基礎(chǔ)上仍然使其提高0.004~0.008,足可以證明本文的改進(jìn)是有效的。從而說明TF-WIDF能有效地減少由于文檔作者用詞不規(guī)范、用詞隨意性造成文檔特征噪聲對(duì)TF-IDF算法的影響。盡管改進(jìn)后的權(quán)重算法取得了一定效果,但文本分類問題設(shè)計(jì)文本表示、相似的計(jì)算、算法決策等多個(gè)方面改進(jìn)權(quán)重算法并未使分類效果得到明顯提高[4]。
通過加權(quán)減少了噪聲特征對(duì)文本分類系統(tǒng)精度的影響。本文研究了傳統(tǒng)的TF-IDF加權(quán)算法,在已適當(dāng)優(yōu)化算法基礎(chǔ)之上提出噪聲加權(quán)算法。實(shí)驗(yàn)證明,在傳統(tǒng)算法基礎(chǔ)上改進(jìn)的加權(quán)算法及其他一些算法基礎(chǔ)上的改進(jìn),都可有更好的表現(xiàn)。

參考文獻(xiàn)
[1] 陸玉昌,魯明羽.向量空間法中單詞權(quán)重函數(shù)的分析和構(gòu)造[J].計(jì)算機(jī)研究與發(fā)展,2002,39(10):1205-1210.
[2] 魯松,李曉黎.文檔中詞語(yǔ)權(quán)重計(jì)算方法的改進(jìn)[J].中文信息學(xué)報(bào),2000,14(6):8-20.
[3] 李凱齊,刁興春.基于信息增益的文本特征權(quán)重改進(jìn)算法[J].計(jì)算機(jī)工程,2011,37(1):16-21.
[4] 臺(tái)德藝,王俊.文本分類特征權(quán)重改進(jìn)算法[J].計(jì)算機(jī)工程,2010,36(9):187-202.