
摘 要: 在傳統(tǒng)向量空間模型的基礎(chǔ)上,提出一種新的信息檢索算法模型——N層向量模型。此模型應(yīng)用在Web信息檢索上,能較好地適應(yīng)文檔集合的動態(tài)擴充。
關(guān)鍵詞: 搜索引擎 向量空間模型 查準(zhǔn)率 查全率
Internet使人類社會步入了以網(wǎng)絡(luò)為中心的信息時代。隨著Web信息爆炸性的增長,如何從大量的信息中迅速、有效、準(zhǔn)確地提取所需信息已成為一個極富挑戰(zhàn)性的課題,并已成為學(xué)術(shù)界和企業(yè)界十分關(guān)注的問題。
半個多世紀(jì)以來,人們提出了許多種信息檢索的算法模型。Salton等人提出的一種向量空間模型的算法是使用TFIDF將文檔轉(zhuǎn)化為向量形式,其計算簡單并且有效,因此得到了較廣泛的應(yīng)用。在經(jīng)典的向量空間檢索模型的算法中,文檔和查詢都是用其所包含的特征項(通常認(rèn)為以詞為特征項比較合理)組成的向量來表示的,并且用文檔與查詢的向量之間夾角的余弦作為相似性的度量,夾角越小,相似度越大。針對特定的查詢向量,比較它與所有文檔向量的相似度,并依相似度將文檔降序排序,提交檢索結(jié)果。這種方法具有簡單直觀、處理速度快等優(yōu)點。但是文檔集合中特征項的數(shù)量遠(yuǎn)遠(yuǎn)大于每一篇文檔或查詢中特征項的個數(shù),因此文檔和查詢的向量表示形式中的大部分項都為零。這些零項將會在計算特征項的權(quán)重和相似度時帶來很大的時間和空間復(fù)雜度,導(dǎo)致數(shù)據(jù)稀疏現(xiàn)象。另外在特征項抽取以及查詢匹配過程中,同一個特征項出現(xiàn)在文檔的不同區(qū)域時,它所表達(dá)文檔內(nèi)容的能力是不同的。而且在文檔同一區(qū)域,不同的特征項所表達(dá)文檔內(nèi)容的能力也是有差別的。使用傳統(tǒng)的向量空間模型則會認(rèn)為這些特征項所表達(dá)文檔的能力完全相同,不能加以區(qū)分。
本文在傳統(tǒng)向量空間模型的基礎(chǔ)上提出一種新的檢索方法,將N層向量空間模型應(yīng)用在Web信息檢索上,使之能較好地適應(yīng)文檔集合的動態(tài)擴充。理論分析和實驗結(jié)果表明,此方法能夠進(jìn)一步提高向量空間模型的性能,節(jié)省存儲空間,加快檢索速度,具有較高的精度和召回率。
1 向量空間模型
1.1 傳統(tǒng)向量空間模型
向量空間模型的出發(fā)點是:每篇文檔和查詢都包含一些用概念詞表達(dá)的、揭示其內(nèi)容的獨立屬性,而每個屬性都可以看成是概念空間的一個維數(shù)。因此,文檔和查詢就可以表示為這些屬性的集合,從而忽略了文本結(jié)構(gòu)中段落、句子及詞語之間的復(fù)雜關(guān)系。這樣,文檔和查詢可以分別用空間的一個點表示,并且文檔矢量與查詢矢量之間就存在空間上的不同距離,而這種距離關(guān)系在信息檢索中的意義就是文檔與查詢之間的相似度。所以,文檔與查詢之間的相似度可以用矢量間的距離來衡量。相似度的計算方法有很多種,本文采用余弦系數(shù)法,即用二個矢量之間的夾角的余弦來表示文檔與查詢間的相關(guān)度。夾角越大,距離越遠(yuǎn),余弦越小,相關(guān)度越小,反之相關(guān)度越大。下面介紹向量空間模型的量化方法。
tfij為特征項tj在文檔di中出現(xiàn)的頻率;dfj為在整個文檔集中,包含特征項tj的文檔數(shù);idfj為反轉(zhuǎn)文檔頻數(shù),其值為:

可見,傳統(tǒng)的向量空間模型是以文本特征項的頻率tf和反轉(zhuǎn)文檔頻率idf作為其量化基礎(chǔ)的。其乘積作為特征項的權(quán)重,再通過計算文檔與查詢之間的相似度即可判斷文檔與查詢是否相關(guān)。權(quán)重值大的特征項是那些在文檔中出現(xiàn)頻率足夠高,但在整個文檔集的其他文檔中出現(xiàn)頻率足夠少的詞語,也是對區(qū)別文檔最有意義的詞語。
1.2 N層向量空間模型
將一篇文檔從組織結(jié)構(gòu)上劃分為N層,基于每層的文本內(nèi)容建立相應(yīng)的特征項向量和權(quán)值。其中特征項抽取和權(quán)重計算等同傳統(tǒng)向量空間模型相同。這樣,對于文檔進(jìn)行N層劃分得到的向量空間模型就成為N層向量空間模型。
本文針對Web信息檢索進(jìn)行考慮,由于Web頁面的特殊格式,要求一篇文檔最少是由指向該文檔的鏈接、文檔標(biāo)題和文檔正文三部分組成。而這三部分的內(nèi)容對于這篇文檔的表達(dá)能力是不同的。鏈接的文字是吸引別人點擊文檔進(jìn)行閱讀的通道,所以鏈接的內(nèi)容表達(dá)文檔的能力最強,其次是標(biāo)題,正文的內(nèi)容表達(dá)文檔的能力最弱。
因此,將N層向量空間模型應(yīng)用在Web信息檢索時,可將一篇Web文檔按照指向文檔的鏈接、標(biāo)題和正文劃分成3層(若Web頁面中有<meta keyword>等標(biāo)記的關(guān)鍵字部分,則可劃分為4層向量空間模型。)。
2 應(yīng)用N層向量空間模型進(jìn)行Web信息檢索
2.1 文本向量表示形式的改進(jìn)
向量空間模型在建完索引以后,要根據(jù)每一個特征項求其對于每一篇文檔和查詢的權(quán)重值。其計算量非常大,并且每一篇文檔和查詢的向量表示式為![]() ,其中大多數(shù)項都為零,所以導(dǎo)致了數(shù)據(jù)稀疏現(xiàn)象。另外由于Web頁面的超鏈性(hyperlink),頁面上顯示的信息有很多是和本頁內(nèi)容無關(guān)的,例如別的頁面的鏈接、版權(quán)信息、欄目導(dǎo)航等,在每個頁面上都有重復(fù)出現(xiàn),這干擾了相似度計算。為解決這些問題,首先引入停用詞表,例如文檔中很多不能說明文檔內(nèi)容的語法詞,還有虛詞、感嘆詞、連詞等或各個文檔共有的詞,所有這些詞作為描述文檔的向量效率是非常低的。因此可以考慮降維處理,把它們作為停用詞,不計算其權(quán)重;其次,采用壓縮矩陣的辦法來解決數(shù)據(jù)稀疏問題,定義文檔和查詢的向量表示形式為:<……,(ti,ωdi),……>,其中ti為第i個特征項,ωdi為其對應(yīng)的權(quán)重值且ωdi≠0。這樣既減少了計算量,又加快了計算速度,同時節(jié)省了存儲空間。
,其中大多數(shù)項都為零,所以導(dǎo)致了數(shù)據(jù)稀疏現(xiàn)象。另外由于Web頁面的超鏈性(hyperlink),頁面上顯示的信息有很多是和本頁內(nèi)容無關(guān)的,例如別的頁面的鏈接、版權(quán)信息、欄目導(dǎo)航等,在每個頁面上都有重復(fù)出現(xiàn),這干擾了相似度計算。為解決這些問題,首先引入停用詞表,例如文檔中很多不能說明文檔內(nèi)容的語法詞,還有虛詞、感嘆詞、連詞等或各個文檔共有的詞,所有這些詞作為描述文檔的向量效率是非常低的。因此可以考慮降維處理,把它們作為停用詞,不計算其權(quán)重;其次,采用壓縮矩陣的辦法來解決數(shù)據(jù)稀疏問題,定義文檔和查詢的向量表示形式為:<……,(ti,ωdi),……>,其中ti為第i個特征項,ωdi為其對應(yīng)的權(quán)重值且ωdi≠0。這樣既減少了計算量,又加快了計算速度,同時節(jié)省了存儲空間。
2.2 特征項頻率統(tǒng)計的改進(jìn)
在統(tǒng)計每個區(qū)域的特征項頻率得到tfij后,要乘以一個反映其重要程度的比例系數(shù)來加以修正和調(diào)整,則特征項tj在文檔di中出現(xiàn)的頻率為:
![]()
其中:tfiji為第i個區(qū)域的頻率(i為1、2、3時分別對應(yīng)鏈接區(qū)域、標(biāo)題區(qū)域、正文區(qū)域),α>β>γ≥1為比例系數(shù)。
同樣,在文檔同一區(qū)域中,不同的特征項所表達(dá)文檔內(nèi)容的能力也是有差別的。例如同在正文區(qū)域的不同的特征項所代表文檔的內(nèi)容就有可能不同。在計算特征項頻率tfij時再乘以一個比例因子log2(M/mi),其中M為該特征項在本文檔中共出現(xiàn)的次數(shù),mi為該特征項在文檔第i次出現(xiàn)的次數(shù)。這樣,特征項tj在文檔di中出現(xiàn)的頻率調(diào)整為:

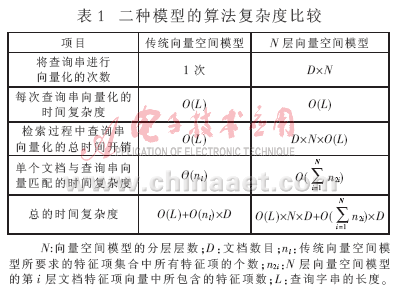
2.3 傳統(tǒng)向量空間模型與N層向量空間模型的算法復(fù)雜度比較
表1為傳統(tǒng)向量空間模型與N層向量空間模型的算法復(fù)雜度比較結(jié)果。
3 實驗設(shè)置
(1)信息檢索實驗系統(tǒng)。信息檢索實驗系統(tǒng)選用了Smart系統(tǒng)。Smart系統(tǒng)是基于向量空間檢索模型實現(xiàn)的信息檢索系統(tǒng)。在本實驗中,為便于實現(xiàn)對向量空間模型算法的修改,使用的是經(jīng)過修改的Smart信息檢索系統(tǒng)。
(2)測試集。測試集分為文檔和查詢(query)二部分:文檔部分采用新浪網(wǎng)站(www.sina.com.cn)的新聞部分Web版(32,145篇)。查詢部分使用新浪網(wǎng)站的新聞討論標(biāo)題,共50個。
(3)評價方法。本系統(tǒng)使用精度和召回率來評價。精度是檢索出來的相關(guān)文檔數(shù)和檢索出來的總文檔數(shù)的比值;召回率是檢索出來的相關(guān)文檔數(shù)和總的相關(guān)文檔數(shù)的比值。通常,召回率越高,精度越低;反之精度越高,召回率越低。所以最有說服力的是11個點的平均精度。世界上最權(quán)威的文本檢索評測會議TREC(Text Retrieval Conference)的評測依據(jù)就是這個值。本系統(tǒng)將只提供這個值。
4 實驗結(jié)果
這里對傳統(tǒng)的向量空間模型算法和改進(jìn)后的向量空間算法進(jìn)行了比較,并統(tǒng)計了對應(yīng)于每一條查詢的11個點處的平均精度值。其結(jié)果如表2所示。

因為平均精度值僅僅是11個點處的精度值的平均值,為了進(jìn)一步說明問題,圖1給出了這幾次檢索的精度-召回率曲線。
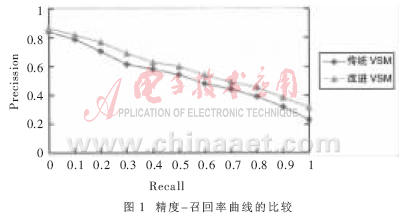
從圖1中可以看出,改進(jìn)向量空間模型在索引時間和精度上都要優(yōu)于傳統(tǒng)向量空間,性能有了很大的提高。
本文提出了一種應(yīng)用N層向量空間模型算法用于Web信息檢索的辦法。理論分析和實驗結(jié)果表明,改進(jìn)后的方法大大提高了Web信息檢索的性能,節(jié)省了存儲空間,加快了計算速度,具有較高的精度和召回率。
參考文獻(xiàn)
1 Salton G.The SMART retrieval system-experiments in automatic document processing.USA:Prentice Hall,1971
2 陶躍華.基于向量的相似度計算方案.云南師范大學(xué)學(xué)報,2001;21(10)
3 陸玉昌,魯明羽.向量空間法中單詞權(quán)重函數(shù)的分析和構(gòu)造.計算機研究與發(fā)展,2002;39(10)
4 劉芳,盧正鼎.有效地檢索HTMl文檔.小型微型計算機系統(tǒng),2000;21(9)