
摘 要: 在足球賽事視頻的應(yīng)用背景下,,分析了面向視頻場景內(nèi)容檢索的文本解析關(guān)鍵技術(shù),,設(shè)計(jì)并實(shí)現(xiàn)了面向視頻場景內(nèi)容檢索的文本解析工具。該工具利用中文分詞技術(shù)分割自然語言文本,,通過漢語語法規(guī)則提取關(guān)鍵詞,,采用加權(quán)算法對(duì)關(guān)鍵詞排序,并將關(guān)鍵詞映射到知識(shí)表達(dá)集,,從而獲得關(guān)鍵詞的語義信息,,完成文本解析。實(shí)驗(yàn)結(jié)果表明,,該工具能夠滿足自然語言文本的視頻檢索需求,。
關(guān)鍵詞: 視頻場景內(nèi)容檢索;文本解析,;關(guān)鍵詞提取,;知識(shí)表達(dá);關(guān)鍵詞映射
本文依托“基于視頻素材的虛擬場景生成系統(tǒng)及其關(guān)鍵技術(shù)研究”課題,,圖1是該課題的部分框架,。

通過視頻場景內(nèi)容標(biāo)注工具對(duì)視頻幀進(jìn)行標(biāo)注,根據(jù)知識(shí)表達(dá)集生成視頻的描述標(biāo)注信息,,并且通過視頻數(shù)據(jù)庫保存起來,。輸入的檢索文本通過視頻場景內(nèi)容檢索工具,檢索返回用戶所需要的視頻,。
文本解析模塊需面向視頻場景內(nèi)容,,基于語義對(duì)文本進(jìn)行解析,以匹配視頻語義標(biāo)注集,,從而獲得更好的檢索效果,。本文主要描述了面向視頻場景內(nèi)容檢索的文本解析工具的設(shè)計(jì)思想和實(shí)現(xiàn)原理。
1 相關(guān)工作
1.1 中文分詞
中文分詞是將中文字序列按照一定的規(guī)則重新組合成詞序列的過程[1],。在對(duì)文本進(jìn)行解析時(shí),,詞是最小的能夠獨(dú)立活動(dòng)的有意義的語言成分。沒有中文分詞,其他一切深入的中文信息處理都無從談起[2],。
在中文分詞方面已經(jīng)有精確度很高的分詞算法和工具,,特別是中國科學(xué)院計(jì)算所推出的ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System),,是由中科院計(jì)算所的張華平,、劉群所開發(fā)的一套分詞系統(tǒng),其漢語分詞,、未定義詞識(shí)別,、詞性標(biāo)注和人名識(shí)別的效果廣受好評(píng)[3-4]。
1.2 關(guān)鍵詞提取
關(guān)鍵詞能夠以最簡潔的形式概括表達(dá)文章主體大意,,可用來檢索海量信息,。
目前大部分的關(guān)鍵詞提取算法都是基于機(jī)器學(xué)習(xí)的方法。在這些算法中,,同一篇文檔中的同一個(gè)詞在不同的地方或許有不同的意思,,例如“蘋果”能夠表示水果的一種或者蘋果產(chǎn)品的意思。同樣地,,不同的詞能夠表示相同的意思,。這些現(xiàn)象產(chǎn)生的原因在于詞匯層面(代表意思的詞)和概念層面(意思本身)的差別,這樣將會(huì)導(dǎo)致關(guān)鍵詞提取的不準(zhǔn)確[5],。
國內(nèi)外對(duì)于文本關(guān)鍵詞的提取研究主要是針對(duì)文檔,、Web頁面等大文本,而本系統(tǒng)針對(duì)的是小文本,。本文采取基于漢語語法規(guī)則和中文分詞系統(tǒng)分詞的詞性,,進(jìn)行關(guān)鍵詞的提取。如對(duì)于主體而言,,在經(jīng)過分詞后,,詞性被確定為“nr”或“r”(如“貝克漢姆”詞性為“nr”,“他”詞性為“r”),,則該詞語為主體,;如對(duì)于行為而言,詞性被確定為“v”(如“射”詞性為“v”),,則該詞語為行為的一部分,。
1.3 加權(quán)算法
一般的文本具有有限的結(jié)構(gòu)或根本沒有結(jié)構(gòu),文本解析的目的是抽取出該文本的結(jié)構(gòu)特征并用結(jié)構(gòu)化的形式保存,。本文選用經(jīng)典的TF-IDF算法表示特征的權(quán)重,。
在一份給定的文件里,詞頻(TF)指某一個(gè)給定的詞語在該文件中出現(xiàn)的次數(shù),,對(duì)于在某一特定文件里的詞語ti來說,,它的重要性為:

1.4 關(guān)鍵詞映射技術(shù)
視頻檢索文本經(jīng)過中文分詞后,,提取了關(guān)鍵詞及其權(quán)重,并且生成了視頻檢索結(jié)構(gòu),,但是,,其與知識(shí)表達(dá)集中的信息不一定完全符合,需要將關(guān)鍵詞映射到知識(shí)表達(dá)集,,然后進(jìn)行檢索,。例如輸入的視頻檢索文本“范尼斯特魯伊小禁區(qū)內(nèi)右腳射門”經(jīng)過關(guān)鍵詞提取與權(quán)重排序模塊之后,生成了關(guān)鍵詞“范尼斯特魯伊”,,但是知識(shí)表達(dá)集里沒有定義“范尼斯特魯伊”,而只是定義了“人”或者是“運(yùn)動(dòng)員”,,所以,,要依據(jù)一定的技術(shù)(如數(shù)據(jù)字典、人名識(shí)別等)將“范尼斯特魯伊”映射為知識(shí)表達(dá)集中的“人”或者“運(yùn)動(dòng)員”,,再生成到知識(shí)表達(dá)集的檢索結(jié)構(gòu),,供檢索算法調(diào)用。在這部分工作中,,涉及到三方面的問題:
(1)實(shí)例到概念的映射,。如“羅納爾多”是“運(yùn)動(dòng)員”這個(gè)概念的一個(gè)實(shí)例,則在檢索過程中,,應(yīng)該將“羅納爾多”映射成為“運(yùn)動(dòng)員”,。
(2)同義詞匹配。如果檢索語句中有“門將”關(guān)鍵詞,,而知識(shí)表達(dá)集中只有相對(duì)應(yīng)的“守門員”這個(gè)本體,,則應(yīng)該將二者匹配起來。
(3)未登錄詞映射,。當(dāng)檢索語句中有知識(shí)表達(dá)集中沒有涉及到的概念或本體時(shí),,則需要做關(guān)鍵詞映射,例如將“球員”映射為“運(yùn)動(dòng)員”,。
2 面向視頻場景內(nèi)容檢索的文本解析工具
2.1 總體設(shè)計(jì)
面向視頻場景內(nèi)容檢索的文本解析工具主要包括4個(gè)模塊:中文分詞模塊,、關(guān)鍵詞提取模塊、關(guān)鍵詞權(quán)重排序模塊和關(guān)鍵詞映射模塊,,如圖2所示,。輸入的視頻檢索文本經(jīng)中文分詞模塊生成詞語及詞性序列,關(guān)鍵詞提取模塊生成主體,、行為,、場景、身體部位等關(guān)鍵詞,,經(jīng)過關(guān)鍵詞權(quán)重排序模塊生成帶有權(quán)值的關(guān)鍵詞結(jié)構(gòu),,最后做關(guān)鍵詞到知識(shí)表達(dá)集的映射,優(yōu)化檢索。

2.2 中文分詞模塊
對(duì)于輸入的檢索文本,,漢語分詞系統(tǒng)ICTCLAS能分解出各個(gè)成分,,并且確定各個(gè)成分的詞性。如檢索文本“范尼斯特魯伊小禁區(qū)內(nèi)右腳射門”,,分詞的最終結(jié)果為“范尼斯特魯伊/nr 小/h 禁區(qū)/n 內(nèi)/f 右/f 腳/n 射門/v”,。其中,“nr”表示“人名”,,“h”代表“前綴”,,“n”表示“名詞”,“f”表示“方位詞”,,“v”表示“動(dòng)詞”,。
2.3 關(guān)鍵詞提取模塊
本文應(yīng)用背景主要是對(duì)足球運(yùn)動(dòng)視頻的檢索。關(guān)鍵詞提取模塊基于中文分詞模塊的切分句子和分出各個(gè)成分詞性的分詞結(jié)果,,通過漢語語法規(guī)則,,提取能表現(xiàn)足球運(yùn)動(dòng)視頻幀的主體、行為,、場景和身體部位等關(guān)鍵詞,。
設(shè)檢索文本中第i個(gè)詞稱為詞i,其詞性用partOfSpeech[i]表示,。
2.3.1 主體關(guān)鍵詞提取
(1)當(dāng)partOfSpeech[i]為“nr”(人名,,如“貝克漢姆”)或“r”(代詞,如“我”)時(shí),,詞i是主體,;
(2)當(dāng)partOfSpeech[i]為“pbei”(被動(dòng)詞),且partOfSpeech[i+1]為“n”時(shí),,詞i+1是主體,;
(3)當(dāng)partOfSpeech[i]為“pbei”,且partOfSpeech[i+1]為“v”時(shí),,被動(dòng)詞后應(yīng)有一個(gè)主體,,主體類型(運(yùn)動(dòng)員、守門員,,裁判)由“v”的類型發(fā)出者決定,,此時(shí)的主體為補(bǔ)充主體。
2.3.2 行為關(guān)鍵詞提取
行為關(guān)鍵詞主要涉及到動(dòng)詞及其賓語,,本文中,,行為主要是動(dòng)詞+賓語。
當(dāng)partOfSpeech[i]為“v”或“vg”或“vn”或“vd”或“vJudge_word”(自定義詞性),,且詞i+1詞性為“v”或“n”或“ng”,,且詞i+2詞性為“v”或“n”時(shí),,行為=詞i+詞(i+1)+詞(i+2)。如果詞i+2詞性不為“v”且不為“n”時(shí),,行為=詞i+詞(i+1),。如果詞i+2詞性不為“v”且不為“n”,且詞i+1詞性不為“v”且不為“n”且不為“ng”時(shí),,行為=詞i,。
2.3.3 場景關(guān)鍵詞提取
(1)當(dāng)partOfSpeech[i]為“p”,且partOfSpeech[i+1]為“n”或“s”時(shí),,詞i+1是場景,;
(2)當(dāng)partOfSpeech[i]為“n”,且partOfSpeech[i+1]為“f”,,且詞i-1的詞性為“a”時(shí),,場景=詞(i-1)+詞i+詞(i+1)。如果partOfSpeech[i-1]不為“a”,,則場景=詞i+詞(i+1);
(3)當(dāng)partOfSpeech[i]為“f”,,且partOfSpeech[i+1]為“q”,,則場景=詞i+詞(i+1);
(4)當(dāng)partOfSpeech[i]為“scene_word”(自定義詞性),,則詞i是場景,。
2.3.4 身體部位關(guān)鍵詞提取
(1)當(dāng)partOfSpeech[i]為“pyong”,則詞i是身體部位,;
(2)當(dāng)partOfSpeech[i]為“f”,,且partOfSpeech[i+1]為“n”,則身體部位=詞i+詞(i+1),;
(3)當(dāng)partOfSpeech[i]為“f”,,且partOfSpeech[i+1]為“q”,則身體部位=詞i+詞(i+1),;
(4)當(dāng)partOfSpeech[i]為“bodyPart_word”(自定義詞性),,則詞i是身體部位。
2.3.5 關(guān)鍵詞提取模塊的實(shí)現(xiàn)
關(guān)鍵詞提取模塊為了存取4類關(guān)鍵詞,,涉及了兩種數(shù)據(jù)結(jié)構(gòu),。第一種是存儲(chǔ)分詞后各詞的名稱及詞性的一個(gè)二維數(shù)組,具體為String deletedSymbolResult[][]=new String[TEXTNO][2],,其中,,TEXTNO表示一次分詞過程中可能涉及到的最多的詞語數(shù)目,deletedSymbolResult[i][0]存取詞語的名稱,,deletedSymbolResult[i][1]存取詞語的詞性,。第二種數(shù)據(jù)結(jié)構(gòu)是類KeywordStruct,、subject、action,、scene和bodyPart,,分別存取主體、行為,、場景和身體部位關(guān)鍵詞,。由于每個(gè)主體的行為可能有多個(gè),因此,,行為action以數(shù)組形式存?。簆ublic String action[]=new String[127]。因?yàn)殛P(guān)鍵詞提取模塊是在中文分詞基礎(chǔ)上進(jìn)行,,所以,,要對(duì)中文分詞進(jìn)行優(yōu)化以將分詞結(jié)果存于合適的數(shù)據(jù)結(jié)構(gòu)中,加載自定義詞典以彌補(bǔ)原有詞典的不足,,然后進(jìn)行4類關(guān)鍵詞的提取,。關(guān)鍵詞提取模塊對(duì)關(guān)鍵詞的提取分為以下幾個(gè)部分:
(1)中文分詞處理結(jié)果的優(yōu)化,包括刪除分詞結(jié)果中標(biāo)點(diǎn)符號(hào)和以空格和“/”分隔符分割的分詞結(jié)果,,抽取詳細(xì)分詞信息這兩部分,。中文分詞的結(jié)果以字符串wordSegResult(如“范尼斯特魯伊/nr 小/h 禁區(qū)/n 內(nèi)/f 右/f 腳/n 射門/v”)表示,調(diào)用split("\\s")和split("/")方法,,可以以空格和“/”分割分詞結(jié)果,,并且將分割的結(jié)果存入deletedSymbolResult中,分詞結(jié)果中標(biāo)點(diǎn)符號(hào)的刪除以循環(huán)deletedSymbolResult數(shù)組,、剔除標(biāo)點(diǎn)的方法實(shí)現(xiàn),。
(2)加載自定義字典,重新定義部分詞語的詞性,。在中文分詞處理結(jié)果優(yōu)化的基礎(chǔ)上,,調(diào)用類KeywordStruct中plusDictionary()方法,包括將“守門員”這類普通名詞“n”重新定義為能識(shí)別出其主體特征的“nr”詞性,,將“黃牌警告”重新定義為“vJudge_word”這類能識(shí)別出主體發(fā)出者為“裁判”的詞性等,。
(3)進(jìn)行主體、行為,、場景和身體部位關(guān)鍵詞的識(shí)別和提取,,包括存儲(chǔ)關(guān)鍵詞信息的類KeywordStruct實(shí)例化和各個(gè)關(guān)鍵詞的存取。本文考慮到輸入的視頻檢索文本中可能對(duì)應(yīng)多個(gè)主體,,將類KeywordStruct實(shí)例化為一個(gè)字符串?dāng)?shù)組變量,。數(shù)組的每個(gè)元素對(duì)應(yīng)一條信息(主體、行為,、場景和身體部位等信息),。KeywordStruct keyword[]=new KeywordStruct[3],,下面以代碼結(jié)合實(shí)例“何塞·保羅·格雷羅經(jīng)過連續(xù)傳球精密配合丹尼·墨菲助攻西蒙·戴維斯破門得分”說明。調(diào)用GetKeywords類的insertSubject()方法,,調(diào)用Getter和Setter方法存取主體,,Keyword[0].setSubject(“何塞·保羅·格雷羅”);Keyword[1].setSubject(“丹尼·墨菲”); Keyword[2].setSubject(“西蒙·戴維斯”)。調(diào)用key.insertAction()方法,,調(diào)用Getter和Setter方法提取行為,。如對(duì)于主體“何塞·保羅·格雷羅”,存入行為Keyword[0].setAction(0,,“傳球”); Keyword[0].setAction(1,“配合”); 對(duì)于主體“丹尼·墨菲”,,存入行為Keyword[1].setAction(0,“助攻”)。調(diào)用key.insertScene()方法和key.insertBodyPart()方法相應(yīng)地獲得對(duì)應(yīng)主體行為發(fā)生的場景和該行為發(fā)生時(shí)所用的身體部位,。
2.4 關(guān)鍵詞權(quán)重排序模塊
關(guān)鍵詞權(quán)重排序主要是為了確定4類關(guān)鍵詞對(duì)于輸入的視頻檢索語句的重要程度,,即檢索時(shí)與視頻的相關(guān)度。
設(shè)計(jì)存取主體,、行為,、場景和身體部位這4類關(guān)鍵詞個(gè)數(shù)的類Item,其中subjectNo,、actionNo,、sceneNo和bodyPartNo分別表示4類關(guān)鍵詞的個(gè)數(shù),sub_act_sce_bod_No表示一個(gè)句子中主體,、行為、場景和身體部位關(guān)鍵詞總個(gè)數(shù),,allSentencesNo表示總的句子數(shù),。
為了計(jì)算逆向文件頻率IDF,首先調(diào)用countWordFrequency()讀取Text4TF-IDF.txt中的測試語句(文本中每一行為一個(gè)測試語句),,統(tǒng)計(jì)allSentencesNo,,同時(shí)調(diào)用tfidf.Item類中的Getter和Setter方法,存取每個(gè)句子中subjectNo,、actionNo,、sceneNo和bodyPartNo。這樣,,可以得出allSentencesNo和包含某個(gè)關(guān)鍵詞的句子個(gè)數(shù)sentenceWithWord[i](i=0表示包含主體的句子總數(shù),;i=1表示包含行為的句子總數(shù);i=2表示包含場景的句子總數(shù),;i=3表示包含身體部位的句子總數(shù)),。由idf[i]=log(allSentencesNo/sentenceWithWord[i])計(jì)算出某個(gè)關(guān)鍵詞的逆向文件頻率IDF。詞頻TF針對(duì)某個(gè)特定語句,。對(duì)于輸入的測試文本,,獲取該語句中subjectNo,、actionNo、sceneNo和bodyPartNo,,通過計(jì)算獲得各關(guān)鍵詞的詞頻,,結(jié)合IDF,計(jì)算各個(gè)關(guān)鍵詞的重要性排序,。
2.5 關(guān)鍵詞映射模塊
2.5.1 同義詞匹配映射
關(guān)鍵詞檢索時(shí),,若關(guān)鍵詞與視頻庫中標(biāo)注的視頻幀信息不同,則首先與視頻庫中的知識(shí)表達(dá)集進(jìn)行同義詞(本體注釋)的匹配,。在知識(shí)表達(dá)集中,,對(duì)于每一個(gè)本體,其對(duì)應(yīng)著本體到本體注釋(同義詞)的一個(gè)結(jié)構(gòu),,當(dāng)關(guān)鍵詞與本體名稱不匹配時(shí),,就利用這個(gè)結(jié)構(gòu)去匹配本體注釋。
2.5.2 實(shí)例到概念的映射
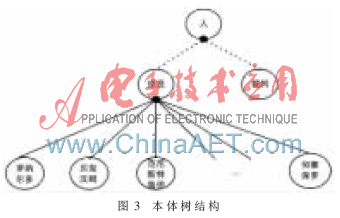
關(guān)鍵詞檢索時(shí),,若關(guān)鍵詞與視頻庫中標(biāo)注的視頻幀信息不同,,并且關(guān)鍵詞與匹配本體注釋也不匹配,則需要查詢本體樹結(jié)構(gòu)(本體樹定義在一個(gè)XML文檔中),。如圖3所示,。
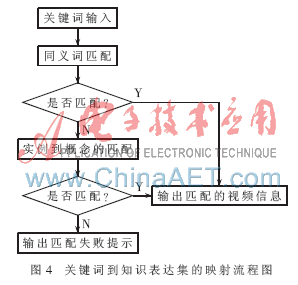
以上的關(guān)鍵詞到知識(shí)表達(dá)集的映射過程可以概括為如圖4所示的活動(dòng)圖。首先進(jìn)行同義詞匹配,,若匹配成功,,則從視頻庫獲取視頻的名稱、URL等信息,,輸出視頻信息,;若匹配不成功,則進(jìn)行實(shí)例到概念的匹配,,如果匹配成功,,則從視頻庫里獲取并輸出視頻信息;如果匹配不成功,,輸出“無對(duì)應(yīng)視頻信息”的提示,。
2.6 文本解析工具
總體上,面向視頻場景內(nèi)容檢索的文本解析工具采用B/S架構(gòu)[7-8],,后臺(tái)是中文分詞模塊,、關(guān)鍵詞提取模塊、關(guān)鍵詞權(quán)重排序模塊和關(guān)鍵詞到知識(shí)表達(dá)集的映射模塊等組成的Web服務(wù)器,。在Web瀏覽器上提交對(duì)視頻檢索文本的中文分詞,、關(guān)鍵詞提取、關(guān)鍵詞權(quán)重排序,、關(guān)鍵詞到知識(shí)表達(dá)集的映射請(qǐng)求,,服務(wù)器接收到Servlet傳來的請(qǐng)求后依次通過中文分詞,、關(guān)鍵詞提取、關(guān)鍵詞權(quán)重排序,、關(guān)鍵詞到知識(shí)表達(dá)集的映射處理,,對(duì)于中文分詞結(jié)果、關(guān)鍵詞提取結(jié)果和關(guān)鍵詞權(quán)重排序結(jié)果,,直接以文本形式顯示在網(wǎng)頁上,,對(duì)于關(guān)鍵詞到知識(shí)表達(dá)集的映射結(jié)果,以檢索到的視頻輸出到網(wǎng)頁上的形式間接反映,。
當(dāng)輸入的檢索文本請(qǐng)求檢索頁面執(zhí)行時(shí),,如果檢索文本為空,則跳轉(zhuǎn)到錯(cuò)誤處理頁面,,返回檢索頁面繼續(xù)請(qǐng)求,;當(dāng)檢索文本不為空時(shí),跳轉(zhuǎn)到分詞結(jié)果,、關(guān)鍵詞提取結(jié)果,、關(guān)鍵詞權(quán)重結(jié)果顯示頁面,然后延遲一段時(shí)間(如3 s),,跳轉(zhuǎn)到視頻輸出頁面,,點(diǎn)擊視頻輸出頁面上的某個(gè)視頻(圖片或文字鏈接),則跳轉(zhuǎn)到視頻播放頁面進(jìn)行視頻播放,。
3 實(shí)驗(yàn)與分析
下面的實(shí)驗(yàn)驗(yàn)證面向視頻場景內(nèi)容檢索的文本解析工具的功能,,分別包括關(guān)鍵詞提取模塊、關(guān)鍵詞權(quán)重排序模塊和整體工具的正確性和魯棒性的檢測,。
3.1 實(shí)驗(yàn)1
輸入檢索文本經(jīng)中文分詞后,,提取面向足球視頻背景的主體、行為,、場景和身體部位4類關(guān)鍵詞,見測試表1,。

經(jīng)過統(tǒng)計(jì)可知關(guān)鍵詞提取模塊在提取關(guān)鍵詞時(shí)的正確率為93.5%,,也可以看到,由于分詞模塊對(duì)某些人名(如“何塞·保羅”)的識(shí)別錯(cuò)誤,,導(dǎo)致提取關(guān)鍵詞時(shí),,將主體分為兩部分,而不是一個(gè)主體,??傮w上,關(guān)鍵詞提取模塊的關(guān)鍵詞提取功能具有可行性,。
3.2 實(shí)驗(yàn)2
輸入檢索文本經(jīng)關(guān)鍵詞提取后,,通過關(guān)鍵詞權(quán)重排序模塊確定各個(gè)關(guān)鍵詞在不同大小的測試集中的權(quán)重,。
在文件test4TFIDF.txt中放入不同數(shù)量的測試語句,調(diào)用countWordFrequency()方法,,統(tǒng)計(jì)主體,、行為、場景和身體部位4類關(guān)鍵詞的IDF值,。為了公平起見,,計(jì)算TF時(shí),設(shè)一個(gè)句子中4類關(guān)鍵詞都有且僅有一個(gè),,因此,,可以用IDF代替TF-IDF。圖5中橫坐標(biāo)是測試文件中包含的測試語句的個(gè)數(shù),,縱坐標(biāo)是TF-IDF值,。
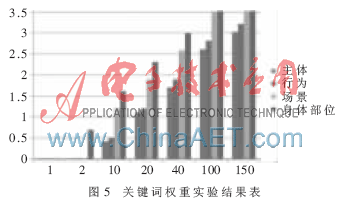
由圖5可知,每個(gè)關(guān)鍵詞的TF-IDF值都隨著文本測試數(shù)據(jù)數(shù)量的增加而增加,,對(duì)于不同數(shù)量的測試數(shù)據(jù),,涉及身體部位視頻的TF-IDF最高,其次是場景,,主體和行為的TF-IDF值最低,。說明對(duì)于一條視頻檢索語句,關(guān)鍵詞權(quán)重由大到小依次是身體部位,、場景,、行為和主體。
3.3 實(shí)驗(yàn)3
對(duì)面向視頻場景內(nèi)容文本解析工具的整體功能進(jìn)行實(shí)驗(yàn),。在主頁上輸入視頻檢索文本“范尼斯特魯伊小禁區(qū)內(nèi)右腳射門”并點(diǎn)擊“視頻搜索”按鈕時(shí),,顯示了輸入的視頻檢索文本、經(jīng)過中文分詞的結(jié)果,、關(guān)鍵詞提取結(jié)果和關(guān)鍵詞權(quán)重排序的結(jié)果,。3 s后,頁面自動(dòng)跳轉(zhuǎn)到視頻檢索結(jié)果頁面,,顯示檢索出的視頻,。
通過實(shí)驗(yàn)驗(yàn)證了面向視頻場景內(nèi)容檢索的文本解析工具對(duì)視頻檢索文本的驗(yàn)證性處理及錯(cuò)誤處理功能,對(duì)中文分詞處理,、關(guān)鍵詞提取處理,、關(guān)鍵詞重要性排序處理的功能,對(duì)視頻顯示和播放的支持,。因此,,驗(yàn)證了面向視頻場景內(nèi)容檢索的文本解析工具的整體功能。
本文設(shè)計(jì)并實(shí)現(xiàn)了面向視頻場景內(nèi)容檢索的文本解析工具,該工具包括中文分詞,、關(guān)鍵詞提取,、關(guān)鍵詞權(quán)值排序和關(guān)鍵詞到知識(shí)表達(dá)集的映射模塊。特別是關(guān)鍵詞提取部分創(chuàng)新性地利用了分詞詞性與漢語語法規(guī)則相結(jié)合的處理方式,,效果顯著,。
在中文分詞模塊,對(duì)于非著名球員的名字的識(shí)別率存在一定的問題,,主要是人名庫沒有收錄,;在關(guān)鍵詞到知識(shí)表達(dá)集的映射中,沒有考慮第三方面的問題——未登錄詞映射,。下一步的工作將從這兩個(gè)方面對(duì)算法進(jìn)行改進(jìn),,以提高分詞和檢索的準(zhǔn)確度。
參考文獻(xiàn)
[1] 張素智,,劉放美.基于矩陣約束法的中文分詞研究[J].計(jì)算機(jī)工程,,2007,33(15):98-100.
[2] 曹衛(wèi)峰.中文分詞關(guān)鍵技術(shù)研究[D].南京:南京理工大學(xué),,2009.
[3] 劉群,,張華平.ICTCLAS_簡介[EB/OL].(2008-12-20).[2012-03-10].http://ictclas.org/ictclas_introduction.html.
[4] Zhang Huaping,Liu Qun.Model of Chinese words rough segmentation based on N-shortest-paths method[J].Journal of Chinese Information Processing(in Chinese),,2002,,16(5):3-9.
[5] 方俊,郭雷,,王曉東.基于語義的關(guān)鍵詞提取算法[J].計(jì)算機(jī)科學(xué),,2008,35(6):148-151.
[6] 維基百科. TF-IDF[EB/OL].(2010-03-20).[2012-03-10]. http://zh.wikipedia.org/wiki/TF-IDF.
[7] ECKEL B.Thinking in Java[M].北京:機(jī)械工業(yè)出版社,,2007:1-600.
[8] HUNT A,,THOMAS D.The pragmatic programmer[M]. Boston,Massachusetts: Addison-Wesley Professional,,2004:3-250.