
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2013)10-0008-03
數(shù)字信號(hào)處理器DSP(Digital Signal Processor)在3G通信、雷達(dá)信號(hào)處理、圖像處理、視頻處理、網(wǎng)絡(luò)等領(lǐng)域被廣泛應(yīng)用,DSP性能和復(fù)雜性在不斷地增加[1]。DSP處理器的功能日益強(qiáng)大,軟件程序的復(fù)雜程度也在不斷增大,軟件的代碼量迅速增加,同時(shí)DSP處理器需要強(qiáng)大編譯器支持來實(shí)現(xiàn)各種應(yīng)用程序。采用無損數(shù)據(jù)壓縮技術(shù)對經(jīng)過編譯、匯編后生成的二進(jìn)制機(jī)器指令代碼進(jìn)行壓縮,可減少指令代碼存儲(chǔ)空間大小。這樣在DSP處理器存儲(chǔ)空間有限的條件下可以存儲(chǔ)更多指令程序代碼,同時(shí)增加Cache命中率,提高BWDSP處理器的整體性能。代碼壓縮技術(shù)可以讓BWDSP處理器的片上存儲(chǔ)空間存儲(chǔ)更多程序代碼,因片內(nèi)存儲(chǔ)速度比片外存儲(chǔ)速度要快幾個(gè)數(shù)量級(jí),從而能更好地滿足BWDSP處理器高速實(shí)時(shí)的信號(hào)處理要求。
在BWDSP處理器芯片中,指令存儲(chǔ)器大小對芯片性能和成本影響很大。因此,壓縮指令代碼空間成為BWDSP芯片設(shè)計(jì)需要考慮的因素。指令代碼壓縮技術(shù)能夠減少程序目標(biāo)代碼尺寸和芯片功耗[2-3],并可以提高指令Cache的命中率和改善指令Cache的性能,從而提高BWDSP性能,減少BWDSP芯片的面積。本文采用LZW無損數(shù)據(jù)壓縮技術(shù)對經(jīng)BWDSP處理器的編譯器、匯編器后生成的二進(jìn)制機(jī)器指令代碼進(jìn)行壓縮,減少指令代碼存儲(chǔ)空間大小。指令代碼壓縮和編譯器對代碼優(yōu)化都是在BWDSP處理器片上完成,而指令代碼壓縮是編譯器優(yōu)化代碼之后的一個(gè)獨(dú)立過程。指令代碼壓縮的輸入代碼是由源程序代碼經(jīng)處理器的軟件編譯器、匯編器生成的二進(jìn)制可執(zhí)行的機(jī)器代碼,該方法不需要改變處理器的軟件編譯器、匯編器,不需修改指令集,也不需要增加DSP處理器內(nèi)核流水線的級(jí)數(shù)。
在BWDSP處理器代碼壓縮系統(tǒng)中對指令代碼進(jìn)行壓縮和解壓,相同尺寸大小的不同原始指令代碼在壓縮后將占用不同大小的存儲(chǔ)空間,這就導(dǎo)致壓縮前后指令代碼存放的實(shí)際物理地址不同,這與無壓縮存儲(chǔ)系統(tǒng)中指令代碼存放的物理地址有很大的差異,從而使壓縮后的指令代碼無法像在無壓縮存儲(chǔ)系統(tǒng)中那樣被BWDSP處理器內(nèi)核隨機(jī)訪問。
2 指令代碼壓縮技術(shù)
2.1 指令Cache的代碼壓縮技術(shù)
代碼壓縮技術(shù)是無損數(shù)據(jù)壓縮,其無損壓縮是指解壓后的指令代碼與壓縮前的原始指令代碼完全相同。代碼壓縮是對代碼進(jìn)行重編碼,以減少輸出字符序列。目前常用的編碼算法有Huffman編碼、Arithmetic編碼、Dictionary-based編碼和基于域劃分的代碼壓縮方法[5]。
為了解決BWDSP處理器內(nèi)核速度與指令存儲(chǔ)器速度匹配的問題,BWDSP處理器有一級(jí)指令Cache,BWDSP處理器取指寬度必須達(dá)到512 bit以保證BWDSP處理器流水線不被停頓,從而提高BWDSP處理器性能。因此,要盡力提高指令代碼密度來增強(qiáng)指令Cache性能和BWDSP處理器性能。指令Cache與BWDSP處理器內(nèi)核之間是按512 bit指令包進(jìn)行取指,指令存儲(chǔ)器與指令Cache是按塊傳遞指令的,所以其指令Cache代碼壓縮算法必須以指令Cache塊的大小為壓縮單位。
本文提出的指令Cache的代碼壓縮技術(shù)是將解碼器放在指令存儲(chǔ)器與指令Cache 之間,指令存儲(chǔ)器存放的是壓縮指令代碼,解壓后指令代碼被存放在指令Cache,只有在指令Cache缺失時(shí)才對壓縮的指令代碼進(jìn)行解壓,每次解壓出一個(gè)512 bit指令包。BWDSP內(nèi)核PC(程序計(jì)數(shù)器)產(chǎn)生的目標(biāo)地址與原始指令代碼中的目標(biāo)地址相同。當(dāng)內(nèi)核PC產(chǎn)生的目標(biāo)地址不在指令Cache中時(shí),即指令Cache目標(biāo)指令要在執(zhí)行前從指令存儲(chǔ)器解壓到Cache中。如果指令利用轉(zhuǎn)移目標(biāo)地址來對指令存儲(chǔ)器壓縮塊進(jìn)行尋址,則可能出現(xiàn)所尋址到的壓縮塊并不好轉(zhuǎn)移目標(biāo)指令。因此基本指令塊的尋址是指在轉(zhuǎn)移目標(biāo)所在的原始程序指令塊地址與轉(zhuǎn)移目標(biāo)所在的壓縮塊地址之間進(jìn)行地址映射。本文利用指令行地址表來實(shí)現(xiàn)指令代碼壓縮前地址與壓縮后地址的這種地址映射。指令行地址表大小也占指令存儲(chǔ)器空間,因此行地址表大小會(huì)影響指令代碼壓縮率。 指令Cache行地址表是在不改變BWDSP內(nèi)核操作和指令集的情況下使用,壓縮代碼可以被BWDSP內(nèi)核隨機(jī)訪問,同時(shí)使現(xiàn)有的指令程序在被壓縮后能夠被正確執(zhí)行。在Cache不命中時(shí),要通過訪問行地址表來確定目標(biāo)代碼地址與壓縮代碼地址間的映射關(guān)系。BWDSP處理器每一條32 bit指令都分成寄存器操作和立即數(shù)操作,其中最高位表示取指包是否已達(dá)到8條指令,第30~27位表示內(nèi)核中那幾個(gè)宏組合,第26位表示取指包是一條指令還是多條指令,第25~18位為操作碼,低18位為操作數(shù)。單字指令基本形式如表1所示。

BWDSP處理器指令Cache行大小為512 bit,未壓縮的每條指令為32 bit,若對16條指令進(jìn)行壓縮,重新使用128 bit壓縮碼來表示,壓縮行與Cache行尺寸大小相同,則壓縮行可以存放2個(gè)取指包。考慮到若將每個(gè)指令Cache行的起始地址指針都在LAT中列出來,則LAT會(huì)變得非常大,反而會(huì)使整體指令代碼顯示不出被壓縮的效果(代碼壓縮后代碼大小包含LAT大小在內(nèi))。通過將幾個(gè)連續(xù)行地址映射表的指針打包在一起來減少行地址映射表開銷(即基地址加偏移量)的方法對指令Cache行進(jìn)行依次尋址。如圖3所示,指令Cache行有32 B,因此至少需要5 bit(L0~L7)表示壓縮后的長度(0~31 B),圖中用24 bit的L0基地址就可以表示基地址。因此L1的基地址就是L0的長度加上基地址,同理可得L2、L3、L4、L5、L6、L7。圖3所示為行地址映射表(LAT)中的每一項(xiàng)。

2.2 LZW壓縮算法
LZW壓縮算法[6]是WELCH T A在LZ78算法基礎(chǔ)上改進(jìn)的字典壓縮方法,該算法有3個(gè)重要的對象,分別是數(shù)據(jù)流、編碼流和編譯表。用LZW壓縮算法對BWDSP處理器編譯后的二進(jìn)制指令代碼進(jìn)行壓縮時(shí),其數(shù)據(jù)流就是輸入對象,編碼流就是輸出對象。LZW算法在壓縮開始,字典中僅包含0和1兩種字符及其編碼的串表,LZW編碼思想是在輸入時(shí)構(gòu)成字符串C與字典中已有字符串進(jìn)行匹配。每輸入一個(gè)字符就將其接在字符串C的后面, 編碼器不斷輸入指令代碼數(shù)據(jù)流,直到輸入某個(gè)字符D后,在字典中找不到匹配,然后把字符串CD存入字典。
LZW壓縮算法是一種貪婪分析算法,串行地檢查輸入數(shù)據(jù)流二進(jìn)制代碼的字符串,并從其中的字符串分解出已經(jīng)在詞典中出現(xiàn)的最長的字符串,輸出字符流為其對應(yīng)的代碼,用該字符串加上下一個(gè)輸入字符C形成新的擴(kuò)展字符串加到字典中。LZW編碼算法的步驟如下:
(1)字典中開始包含代碼0和1的兩種可能的單個(gè)字符值,令當(dāng)前字符串S:=Null。
(2)當(dāng)前字符C:=字符流中的下一個(gè)字符。
(3)判斷字符串S+C是否在字典中,若在,則S=S+C;否則,
①把代表當(dāng)前字符串S的代碼輸出到碼子流;
②把字符串S+C添加到字典;
③令S=C。
(4)判斷輸入數(shù)據(jù)流中的字符是否還要編碼,若是,則返回到(2);否則把當(dāng)前字符串所代表的代碼輸出到碼字流,程序結(jié)束。
3 實(shí)驗(yàn)仿真
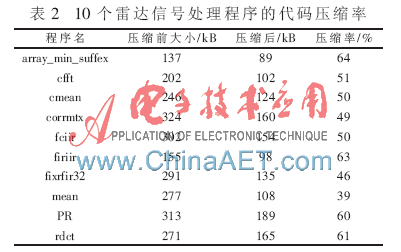
SystemC語言的重要特征是支持系統(tǒng)的建模和驗(yàn)證高性能處理器性能,本文實(shí)驗(yàn)平臺(tái)是利用SystemC語言建立的高性能BWDSP模擬器。高性能BWDSP模擬器內(nèi)核采用RSIC指令集、按照32 bit尋址方式尋址,11級(jí)流水線,內(nèi)核發(fā)射的寬度為16條指令,工作頻率為500 MHz,指令存儲(chǔ)器為1 Mbit,指令Cache大小為256 Kbit,指令Cache行的大小為512 bit。把LZW字典壓縮和解壓算法加載在BWDSP100模擬器上構(gòu)成BWDSP處理器指令代碼壓縮體系結(jié)構(gòu)。LZW代碼壓縮算法以指令Cache塊為壓縮單位,以單個(gè)字符作為最小的符號(hào)單位,通過對指令存儲(chǔ)器每一塊上添加兩位構(gòu)成行地址表來建立壓縮前指令代碼地址與壓縮后指令代碼地址的對應(yīng)關(guān)系。針對BWDSP處理器10個(gè)典型的雷達(dá)信號(hào)處理程序,通過BWDSP編譯并進(jìn)行匯編后,用LZW壓縮算法對機(jī)器代碼進(jìn)行壓縮,其得到的代碼壓縮率如表2所示。由表2可知,通過在高性能BWDSP模擬器上對10個(gè)典型雷達(dá)信號(hào)處理程序指令代碼的壓縮驗(yàn)證,該10個(gè)典型雷達(dá)信號(hào)處理程序的存儲(chǔ)空間平均可減少40%左右。
在高性能BWDSP處理器驗(yàn)證平臺(tái)上,Cache的替換算法為隨機(jī)替換算法,10個(gè)典型雷達(dá)信號(hào)處理測試程序在無代碼壓縮處理器上的平均訪存時(shí)間和Cache命中率及在有代碼壓縮處理器上的平均訪存時(shí)間和Cache命中率如表3所示。

從表3可知,10個(gè)典型雷達(dá)信號(hào)測試程序在有代碼壓縮BWDSP處理器模擬器上的平均訪存時(shí)間比在無代碼壓縮BWDSP處理器模擬器上的平均訪存時(shí)間少0.006個(gè)cycle左右。有代碼壓縮BWDSP處理器模擬器上的Cache命中率比在無代碼壓縮BWDSP處理器模擬器上的Cache命中率要提高了5%左右。在BWDSP處理器模擬器上的驗(yàn)證結(jié)果表明,通過指令代碼壓縮可使高性能BWDSP處理器的整體性能獲得提高。
以10個(gè)典型雷達(dá)信號(hào)處理程序作為測試指令代碼,在用SystemC語言建立的BWDSP處理器指令代碼壓縮模型上,對高性能BWDSP處理器指令代碼壓縮技術(shù)進(jìn)行實(shí)驗(yàn)仿真,其結(jié)果表明,指令代碼壓縮技術(shù)可以提高Cache命中率,減少指令代碼存儲(chǔ)空間,使高性能BWDSP處理器整體性能進(jìn)一步提高。目前IC制造工藝水平已達(dá)到22 nm,為更高復(fù)雜度DSP處理器芯片的研制打下牢固的基礎(chǔ)。代碼壓縮技術(shù)進(jìn)一步推動(dòng)了高性能DSP處理器的發(fā)展。高性能DSP發(fā)展的差異性和需求的多樣性以及廣泛性,是我國在現(xiàn)階段DSP產(chǎn)品的戰(zhàn)略和學(xué)術(shù)研究方向,擁有我國自主知識(shí)產(chǎn)權(quán)的第一代高性能BWDSP及其開發(fā)平臺(tái),對加強(qiáng)我國自主研制高性能BWDSP芯片及其產(chǎn)業(yè)化發(fā)展具有重要戰(zhàn)略意義。
參考文獻(xiàn)
[1] AGARWALA S.A multi-level memory system architecture for high performance DSP application[C].International Conference on Computer Design,2000:408-413.
[2] COLLIN M,BRORSSON M.Low power instruction fetch using profiled variable length instructions[C].Proceedings of the IEEE International SoC Conference,2003:183-188.
[3] BENINI L.Hardware-assisted data compression for energy minimization in systems with embedded processors[C]. Proc.of the Design, Automation and Test in Europe Conf.(DATE),2002:449-453.
[4] 洪興勇,洪一.基于BWDSP指令Cache的PLRU替換算法研究[J].電子技術(shù)應(yīng)用,2013,39(1):78-83.
[5] PENNEC E L,MALLAT S.Image compression with geometrical wave—lets[C]. In:Proc of ICIP′2000,Vancouver,Canada,2000:661-664.
[6] WELCH T A.A technique for high-performance data compression[J].IEEE Computer,1984,17(6):8-18.