
文獻標識碼: A
文章編號: 0258-7998(2013)11-0027-03
傳統(tǒng)的并行總線架構(gòu)多采用VME標準,但共享總線會造成頻繁等待和沖突,大大降低了系統(tǒng)運行效率,不適合大規(guī)模并行數(shù)據(jù)處理系統(tǒng)。隨著現(xiàn)代雷達、圖像等信號處理應用對信號帶寬和數(shù)據(jù)傳輸速率要求的不斷提升,基于VPX串行總線標準的通用信號處理器占有較大的優(yōu)勢[1-3]。本文首先介紹了基于VPX總線架構(gòu)的系統(tǒng)設(shè)計,著重介紹了信號處理卡VPX6-460的硬件組成,并采用VxWorks實時操作系統(tǒng)實現(xiàn)了多處理器間的高速數(shù)據(jù)通信。
1 系統(tǒng)整體設(shè)計
VPX定制機箱采用新型的高速串行總線標準VITA46,相對于VME總線架構(gòu)而言,具有更大的數(shù)據(jù)吞吐能力和交換能力、更好的散熱性能和更高功率的插槽,充分滿足了信號處理系統(tǒng)對帶寬和運算處理能力的要求[4-5]。圖1所示為系統(tǒng)的基本框圖。整個系統(tǒng)主要由多通道信號采集卡、多通道數(shù)據(jù)回收卡、信號處理卡以及高性能服務器等組成。系統(tǒng)以千兆以太網(wǎng)作為平臺間的網(wǎng)絡互連標準,并使用串行RapidIO和PCIe作為底板總線交換網(wǎng)絡互連協(xié)議。VPX載板和模塊化的信號采集子卡組成了系統(tǒng)的前端數(shù)據(jù)采集部分,VPX載板擁有的多個高速串行接口可以將采集到的并行數(shù)據(jù)轉(zhuǎn)換成串行數(shù)據(jù)流,傳送給后端的信號處理板進行復雜的后端處理[6]。

2 硬件設(shè)計
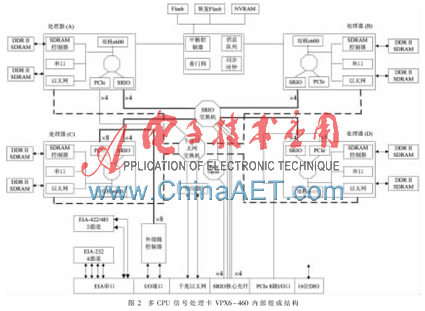
在整個VPX機箱中,嵌入式信號處理卡VPX6-460是一款多CPU并行處理器信號處理卡,其內(nèi)部組成結(jié)構(gòu)如圖2所示。板上載有4塊雙核PowerPC 8641D處理器,共有8個e600處理器核,每個處理器配有512 MB的同步動態(tài)隨機存儲器DDR2SDRAM,還配有512 MB具有寫保護的Flash和NVRAM。板上的千兆以太網(wǎng)交換機用來配置每個處理器的狀態(tài);4個處理器間通過串行RapidIO交換器實現(xiàn)串行數(shù)據(jù)互連,每個處理器的數(shù)據(jù)輸入/輸出速率都可達到雙向12 Gb/s,同時有4路串行RapidIO連接到背板,可連接4個處理板,支持16個處理器間的全速數(shù)據(jù)交換;板上的XMC/PMC插座支持8路PCIe連接,可用于擴張外部的輸入/輸出接口。
3 軟件設(shè)計
信號處理器的硬件部分構(gòu)成了系統(tǒng)框架和硬件平臺,而軟件部分則用于實現(xiàn)各種功能,是整個系統(tǒng)的“靈魂”。VPX6-460是典型的“通用處理器平臺+嵌入式操作系統(tǒng)”結(jié)構(gòu),選用的操作系統(tǒng)是美國Wind River公司最新研發(fā)的VxWorks6.8,主機上的開發(fā)環(huán)境是基于Eclipse軟件架構(gòu)設(shè)計的Workbench3.1,通過串口和網(wǎng)絡接口實現(xiàn)主機與目標機間的交叉編譯和交叉調(diào)試。VxWorks實時操作系統(tǒng)提供了專門的系統(tǒng)調(diào)用函數(shù)接口來連接中斷向量和中斷服務程序,內(nèi)核可以自動提供有關(guān)中斷處理中所需要的堆棧切換以及寄存器保護、回復等功能。VxWorks6.8 提供的內(nèi)部處理器通信IPC(Inter Pro-cessor Communication)函數(shù)庫Rel2.4.7支持多處理器間的通信,適用于底層串行RapidIO和以太網(wǎng)的鏈接,提供與連接無關(guān)的編程接口,從而簡化了多處理器通信的程序設(shè)計,提高了程序的可移植性。
VPX6-460的各個處理器之間主要采用直接內(nèi)存訪問DMA(Direct Memory Access)通信機制,可以同時傳輸批量數(shù)據(jù)。當DMA控制器接收到來自輸入/輸出口的DMA請求時,CPU就會轉(zhuǎn)讓總線控制權(quán)給DMA控制器,在完成數(shù)據(jù)傳輸后,DMA控制器會歸還總線控制權(quán)。整個傳輸過程由DMA控制器負責而不需要CPU的參與,有效地減少了CPU的占用時間,大大提高了系統(tǒng)性能[7-8]。圖3所示為VPX6-460上兩個處理器間通信的基本原理框圖。

在本地處理器上創(chuàng)建由指針A0_sender指向的緩存區(qū)buffer_ab,相應的發(fā)送端口為AB_ A0_BlkPort,由函數(shù)msgBlkWrite( )將成片數(shù)據(jù)寫入到目標處理器上,由目標處理器的新建緩存區(qū)存儲接收數(shù)據(jù),接收端口為AB_ B0_BlkPort,緩存區(qū)名也為buffer_ab,使用相同緩存名可以實現(xiàn)數(shù)據(jù)共享。由于DMA寫操作是異步實現(xiàn)的,即無論DMA請求是否已被執(zhí)行,msgBlkWrite( )都會立即返回,因此本地處理器需要調(diào)用函數(shù)callBack( )返回寫操作的完成時間和狀態(tài)等信息。同時,在完成數(shù)據(jù)傳輸時,DMA控制器要釋放總線控制權(quán),通過發(fā)送端口的寫中斷服務程序告知本地處理器已完成數(shù)據(jù)傳輸,接收端口以讀中斷服務程序告知目標處理器已完成數(shù)據(jù)接收。部分程序如下:
msgBlkPort AB_A0_BlkPort;
msgBlkStatsInfo AB_A0_BlkInfo;
AB_A0_BlkPort=msgBlkOpen(BUFAB_NAME,8,0);
if (AB_A0_BlkPort==0)
{
printf(“start_test: msgBlkOpen() failed”);
return -1;
} /*打開發(fā)送緩存區(qū),返回輸出端口地址,能允許的最大
DMA請求數(shù)為8 */
status=msgBlkIoctl(AB_A0_Port,MSGIOCTL_FLOELVLV_
PRIORITY,MSGIOCTL_FLOWLVLV_HIGH);
if (status!=0)
{
printf(“Error invalid priority flow setting\n”);
} /*設(shè)置數(shù)據(jù)傳輸?shù)膬?yōu)先級*/
while(1)
{
msgBlkIoctl(AB_A0_BlkPort,MSGIOCTL_GET_STATS,(long)
&AB_A0_blk Info);
if (AB_A0_BlkInfo.isconnected!=0)
{
printf (“start_test:\”%s” connected to proc 0 x%x, length %
ld\n”, AB_A0_BlkInfo.name, AB_A0_ BlkInfo.peerProc,
AB_A0_BlkInfo.size);
break;
}
else
taskDelay(1);
} /*設(shè)置端口信息,判斷發(fā)送端口是否已正確連接到目標
處理器*/
AB_msgBlkWriteInProgress=1;
status=msgBlkWrite(AB_A0_BlkPort,A0_sender,Buffer_size,0,
MSGBLK_OPTION_SIGNAL,0,A0_msgBlkWriteDoneISR,0);
/*寫函數(shù)包括了本地處理器需要返回調(diào)用的參數(shù)信息,
同時含有寫中斷函數(shù)信息*/
if (status)
{
printf(“start_test: msgBlkWrite() returned 0x%x \n”, status);
return -1;
} /*將本地緩存數(shù)據(jù)正確傳送到目標處理器上,實現(xiàn)了處
理器間的數(shù)據(jù)傳輸*/
while(AB_msgBlkWriteInProgress)
taskDelay(1);
printf(“Data transferred ”);
msgBlkClose(AB_A0_BlkPort);
return 1;
static void A0_msgBlkWriteDoneISR (msgBlkP ort port, void
*pParam, long status)
{
AB_msgBlkWriteInProgress=0;
} /*寫中斷服務子程序,告知本地處理器已完成數(shù)據(jù)傳輸*/
int B0_receive(void)
{
int i,j;
int status;
msgBlkPort AB_B0_BlkPort;
msgBlkPort BC_B0_BlkPort;
msgBlkInfo BC_B0_BlkInfo;
if (NULL==B0_receiver)
{
B0_receiver=cacheDmaMalloc(BUFFER_SIZE);
if (!B0_receiver)
{
printf(“B0_receive:cacheDmaMalloc(0x%x)\n failed”,
BUFFER_SIZE);
return -1;
} /*在目標處理器上建立接收緩存區(qū)*/
AB_B0_BlkPort=msgBlkCreate(BUFAB_NAME,B0_receiver,
BUFFER_SIZE,MSGBLK_OPTION_SIGNAL);
/*接收緩存區(qū)與發(fā)送緩存區(qū)有相同的緩存區(qū)名“buffer_ab”,
以實現(xiàn)數(shù)據(jù)共享*/
if (AB_B0_BlkPort==0)
{
printf (“B0_receive:msgBlkCreate() failed\n”);
return -1;
}
AB_msgBlkReadInProgress=1;
msgBlkSigConnect(AB_B0_BlkPort,B0_msgBlkReadDoneISR,
(void*)0x1234);
msgBlkSigEnable(AB_B0_BlkPort);
/*確認接收端口已連接到目標處理器,
并由讀中斷服務子程序告知已正確完成接收*/
本文在介紹了VPX6-460硬件組成的基礎(chǔ)上,結(jié)合VxWorks操作系統(tǒng)的特點以及系統(tǒng)所支持的通信機制,詳細分析了不同處理器間的數(shù)據(jù)傳輸方式,并給出了具體的軟件實現(xiàn)方法。該程序的高度可移植性使其具有很高的應用價值。
參考文獻
[1] 杜文鳳,王博文.基于嵌入式的實時通信協(xié)議棧研究與設(shè)計[J].電子技術(shù)應用,2013,(39)1:29-31.
[2] 劉昊昱.一種基于VxWorks技術(shù)的通用信號處理平臺設(shè)計[J].電子技術(shù)應用,2003,(29)6:13-15.
[3] 宋秀蘭,吳曉波.多處理器通信設(shè)計[J].浙江工業(yè)大學學報,2010,38(4):426-429.
[4] 廖明燕.基于MSP430的多處理器通用技術(shù)研究[J].微處理機,2006,2(1):86-91.
[5] 何先波,李薇.嵌入式系統(tǒng)軟件開發(fā)技術(shù)基礎(chǔ)[M].北京:清華大學出版社,2011.
[6] 史鴻聲.基于PowerPC的雷達通用處理器設(shè)計[J].雷達科學與技術(shù),2011,9(2):140-144.
[7] 李世光,孟強強.基于多串口的熱量表系數(shù)修正軟件的設(shè)計[J].微型機與應用,2012,31(18):1-4.
[8] 翁省輝,喻武龍.Liunx下SANE Driver自動化測試工具的設(shè)計與實現(xiàn)[J].微型機與應用,2012,31(1):4-6.