
文獻(xiàn)標(biāo)識碼: A
文章編號: 0258-7998(2014)01-0016-04
FPGA作為未來數(shù)字電路系統(tǒng)的三大基石之一,是目前硬件設(shè)計方法的研究熱點。與傳統(tǒng)的電路設(shè)計方法相比,F(xiàn)PGA具有功能強(qiáng)、周期短、投資小、開發(fā)工具智能化等特點。隨著電子工藝的不斷改進(jìn),新一代的FPGA甚至集成了CPU和DSP內(nèi)核,在一片F(xiàn)PGA上進(jìn)行軟硬件協(xié)同設(shè)計,為實現(xiàn)片上可編程系統(tǒng)(SoPC)提供了強(qiáng)大的硬件支持,這使得FPGA成為許多高性能應(yīng)用的最佳選擇。FPGA產(chǎn)品的應(yīng)用領(lǐng)域已經(jīng)從相對較窄的通信基礎(chǔ)設(shè)備領(lǐng)域迅速擴(kuò)張到消費電子、汽車電子、工業(yè)控制、測試測量等領(lǐng)域。
一般來講,要在FPGA設(shè)計中實現(xiàn)較高的性能,除了要求設(shè)計者精通HDL語言,還需熟知FPGA的內(nèi)部結(jié)構(gòu),具備足夠的數(shù)字電路知識。這種方法直接面向硬件,抽象層次較低,抬高了FPGA開發(fā)的準(zhǔn)入門檻,還嚴(yán)重降低了FPGA的開發(fā)效率。
OpenCL作為跨平臺的開發(fā)語言,為上述問題提供了一套可選擇的解決方案。OpenCL在傳統(tǒng)的C語言基礎(chǔ)上進(jìn)行了擴(kuò)展,具備較高的抽象層次和可移植性,開發(fā)者即使不了解硬件電路和設(shè)備的底層細(xì)節(jié),也可以開發(fā)出高性能的FPGA應(yīng)用程序。這種開發(fā)方法可以減少硬件開發(fā)時間,把更多的時間用于算法優(yōu)化,提高FPGA的開發(fā)效率。
目前,絕大部分OpenCL開發(fā)都是基于CPU和GPU。由于FPGA與GPU/CPU結(jié)構(gòu)上的差異,OpenCL在GPU/CPU上的開發(fā)方法并不完全適用于FPGA,F(xiàn)PGA的OpenCL設(shè)計方法學(xué)尚存在較大的改進(jìn)空間。針對以上問題,本文以矩陣乘法和QR分解為例,根據(jù)FPGA的特點制定并實現(xiàn)了多種優(yōu)化方案,分析了各種優(yōu)化方案的優(yōu)缺點及適用情況,為后續(xù)FPGA的OpenCL開發(fā)提供參考。
1 相關(guān)工作
自2008年蘋果開發(fā)者大會(WWDC)提出OpenCL以來,已有不少的機(jī)構(gòu)和學(xué)者進(jìn)行OpenCL的開發(fā)研究,并取得了顯著的成果,目前大部分的OpenCL研究都是基于GPU平臺。參考文獻(xiàn)[1]就矩陣乘法分別在多核CPU、AMD GPU、NVIDIA GPU上進(jìn)行了實現(xiàn)和優(yōu)化,并對比了各平臺的性能。
2013年,Altera和Xilinx兩大FPGA主流廠商相繼推出了針對FPGA的OpenCL開發(fā)套件,但目前相關(guān)研究成果較少,只能在IEEE平臺上搜索到寥寥幾篇論文。參考文獻(xiàn)[2-4]中介紹了在FPGA上進(jìn)行OpenCL開發(fā)的原理及相關(guān)工具。參考文獻(xiàn)[5]使用OpenCL在Altera的FPGA上實現(xiàn)了一個文檔篩選算法,與CPU、GPU相比分別取得了5.5、5.25的加速比,但沒有針對FPGA做深入的優(yōu)化工作,也未詳細(xì)分析如何提升FPGA運算性能。參考文獻(xiàn)[6]分別在CPU、GPU和FPGA 3個平臺上實現(xiàn)了不規(guī)則圖像和視頻的壓縮算法,F(xiàn)PGA平臺與多核CPU、GPU相比分別達(dá)到了3、114的加速比。作者只是簡單地將GPU上的應(yīng)用移植到了FPGA上,而未做進(jìn)一步的優(yōu)化。參考文獻(xiàn)[7]對多核CPU、GPU、FPGA平臺在性能、設(shè)計理論、平臺體系結(jié)構(gòu)等方面進(jìn)行了對比,分別用CUDA、OpenCL、VHDL 3種開發(fā)語言在多種平臺下實現(xiàn)了Quantum Monte Carto程序。通過對比發(fā)現(xiàn),OpenCL可以很方便地在多核CPU、GPU和FPGA之間進(jìn)行移植。
目前介紹在FPGA上進(jìn)行OpenCL開發(fā)的相關(guān)文獻(xiàn)還非常稀少,大多數(shù)文獻(xiàn)都只是針對FPGA的OpenCL開發(fā)進(jìn)行理論介紹,即使有少數(shù)幾篇進(jìn)行了實際應(yīng)用開發(fā),也僅僅停留在實現(xiàn)階段,并沒有針對FPGA的硬件結(jié)構(gòu)詳細(xì)分析其OpenCL優(yōu)化方法,這正是本文的研究重點。
2 算法研究
目前基于FPGA的OpenCL開發(fā)都是移植了GPU上的應(yīng)用,例如圖像處理、視頻壓縮/解壓縮等。然而通信、雷達(dá)、汽車電子、工業(yè)控制才是FPGA的傳統(tǒng)領(lǐng)域,尤其在通信領(lǐng)域中FPGA應(yīng)用更為廣泛。但當(dāng)前還沒有相關(guān)文獻(xiàn)把OpenCL開發(fā)方法用于通信領(lǐng)域。
矩陣運算是通信領(lǐng)域中的基礎(chǔ)運算,尤其是矩陣乘法和QR分解,是工程應(yīng)用中最常見的矩陣運算,在信號檢測與估計、數(shù)字信號處理等領(lǐng)域中應(yīng)用廣泛。因此,本文以矩陣乘法和QR分解為例,對FPGA的OpenCL實現(xiàn)及優(yōu)化進(jìn)行相關(guān)研究。



initial Q=E, R=A
barrier
for(int j=0; j<=Width-2; j++)
{
initial H
barrier
calculate the
generate H
barrier
compute Q = Q *
barrier
compute R = H * R
barrier
}
由于Householder變換法的特性,本文只將部分優(yōu)化手段應(yīng)用于QR分解。主要探索item復(fù)制和向量化兩種方法的性能。本例中的QR分解內(nèi)部具有較多的數(shù)據(jù)同步點,且item之間的數(shù)據(jù)依賴性非常強(qiáng),即邏輯控制較多,因而向量化和item復(fù)制并不是QR分解的理想優(yōu)化手段。
4 結(jié)果分析
測試數(shù)據(jù)采用隨機(jī)函數(shù)生成,并將FPGA的運算結(jié)果與C函數(shù)的運算結(jié)果相比較,判斷結(jié)果是否正確。本文采用多種優(yōu)化方法實現(xiàn)矩陣乘法,實驗結(jié)果如表1所示。

對于數(shù)據(jù)存取優(yōu)化(如表1所示),通過設(shè)置合適的workgroup大小,減少item重復(fù)存取數(shù)據(jù)的次數(shù),即可有效地提高性能。
對于循環(huán)展開優(yōu)化,運行時間與循環(huán)展開次數(shù)是呈反比的。循環(huán)展開實質(zhì)就是采用空間換取時間,展開次數(shù)越多,邏輯面積越大,執(zhí)行時間則越短。
對于向量化1、2、4、8次,可以看出其運行時間基本是與向量化次數(shù)呈反比的。向量化復(fù)制了kernel的運算單元,使得item可以同時存取并處理多個數(shù)據(jù),提高了kernel性能。然而,向量化16次的性能更差,這主要是受到了硬件資源限制。DDR帶寬和FPGA邏輯資源都已超出DE4的最高峰值,造成了性能的急劇下降。
隨著item復(fù)制次數(shù)的增加,性能有所提高,這也是使用空間換取時間的方法。但是其性能并不像向量化那樣呈線性增長,這是因為item復(fù)制是將整個kernel功能單元進(jìn)行復(fù)制,除了需要較多的邏輯資源外,全局帶寬的需求也成倍增長,導(dǎo)致全局帶寬超過DDR的最大帶寬,使得性能增長曲線是非線性的。
組合優(yōu)化同時使用向量化和item復(fù)制,可最大限度地發(fā)揮這兩種方法的優(yōu)點,實現(xiàn)性能提升,但效果還不夠顯著,這也是受到了DDR帶寬的限制。
矩陣乘法是典型的大數(shù)據(jù)運算,有著大量的數(shù)據(jù)存取操作,內(nèi)部控制邏輯較少,這類運算需要較大的全局帶寬和較強(qiáng)的浮點運算能力。從表1中可以看到性能提升的瓶頸在于全局帶寬,如何解決這一問題是優(yōu)化的重點。可以使用以下兩種方法降低kernel所需的全局帶寬:(1)進(jìn)行數(shù)據(jù)存取優(yōu)化,減少kernel的重復(fù)存取操作,減少單個item實際使用的帶寬;(2)向量化,提高全局帶寬的有效利用率。從表1中也可以看出,這兩種方法確實取得了非常好的效果。另外,還可以通過提升硬件的全局帶寬來滿足kernel對帶寬的需求。
在QR分解中,主要采用了向量化和item復(fù)制兩種方法,如表2所示。
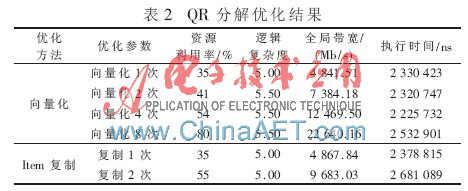
由表2可見,不管是向量化還是item復(fù)制,性能均沒有得到有效的提升,甚至有一定的惡化,其中item復(fù)制帶來的性能惡化更嚴(yán)重,這主要是因為QR分解的邏輯復(fù)雜度較大。在QR分解中,數(shù)據(jù)量并不大,所需的全局帶寬較小,除了向量化8次外,其余的優(yōu)化所需的全局帶寬均沒有超過DE4的限制。但是其中的運算過程較為復(fù)雜,可以看到其邏輯復(fù)雜度為5.5左右,限制了kernel性能的提高。
對于此類邏輯復(fù)雜度較大的應(yīng)用,上述幾種優(yōu)化手段均不能得到非常好的效果。此時應(yīng)以算法優(yōu)化為主,以降低kernel內(nèi)部的邏輯復(fù)雜度。
本文以矩陣乘法和QR分解為例,在FPGA上分別進(jìn)行了實現(xiàn)和優(yōu)化,比較分析了各種優(yōu)化方法的優(yōu)缺點及適用范圍。目前,F(xiàn)PGA的OpenCL開發(fā)剛剛興起,還有諸多不足,從實驗中也可以看出,許多優(yōu)化方法都受到了FPGA結(jié)構(gòu)、算法并行性等多方面的限制,還需要從設(shè)計方法、FPGA結(jié)構(gòu)優(yōu)化、算法優(yōu)化等多個方面進(jìn)一步探討如何更合理地運用OpenCL開發(fā)FPGA。這有賴于FPGA廠商進(jìn)一步完善工具和開發(fā)流程,也有賴于廣大科研工作者、應(yīng)用工程師的配合和努力。
參考文獻(xiàn)
[1] SEO S,JO G,LEE J.Performance tuning of matrix multiplication in OpenCL on different GPUs and CPUs[C].High Performance Computing,Networking,Storage and Analysis,2012:396-405.
[2] CZAJKOWSKI T S.Form OpenCL to high-performance hardware on FPGAs[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:531-534.
[3] Ma Sen,Huang Miaoqing,ANDREWS D.Developing application-specific multiprocessor platforms on FPGAs[C].Reconfigurable Computing and FPGAs(ReConFig),2012 International Conference,2012:1-6.
[4] ECONOMAKOS G.ESL as a Gateway from OpenCL to FPGAs:basic ideas and methodology evaluation[C]. Informatics(PCI),2012 16th Panhellenic Conference,2012:80-85.
[5] CHEN D,SINGH D.Invited paper:using OpenCL to evaluate the efficiency of CPUS, GPUS and FPGAS for information filtering[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:5-12.
[6] CHEN D,SINGH D.Fractal video compression in OpenCL:an evaluation of CPUs,GPUs,and FPGAs as acceleration platforms[C].Design Automation Conference(ASP-DAC),2013 18th Asia and South Pacific,2013:297-304.
[7] WEBER R.Comparing hardware accelerators in scientific applications:a case study[J].Parallel and Distributed Systems,IEEE Transactions,2011,22(1):58-68.
[8] 張賢達(dá).矩陣分析與應(yīng)用[M].北京:清華大學(xué)出版社,2004.
[9] 李剛強(qiáng),田斌,易克初.FPGA設(shè)計中關(guān)鍵問題的研究[J].電子技術(shù)應(yīng)用,2003,29(6):68-71.
[10] 張國禮,王建業(yè),肖宇.浮點矩陣相乘IP核并行改進(jìn)的設(shè)計與實現(xiàn)[J].電子技術(shù)應(yīng)用,2012,38(2):43-46.