
文獻標識碼: A
文章編號: 0258-7998(2014)03-0029-03
隨著電子通信技術(shù)的發(fā)展,電子通信產(chǎn)品已成為人們生活不可或缺的產(chǎn)品,電子通信產(chǎn)品的產(chǎn)量有了巨大的提升,同時電子通信質(zhì)量也有了相應(yīng)的提升,信道編譯碼是影響通信系統(tǒng)傳輸質(zhì)量的直接因素。在信道編碼中應(yīng)用最為廣泛的是卷積碼編碼[1],而卷積碼的最佳譯碼方式是Viterbi譯碼[2]。近年來,卷積編碼和Viterbi譯碼技術(shù)已經(jīng)有了長足的發(fā)展,不論是譯碼算法還是實現(xiàn)架構(gòu)都達到了極高的水平。算法中間的各個功能單元也得到了改進,研究性的論文也層出不窮。雖然實現(xiàn)方法很多,但是僅能滿足一種或兩種通信標準,靈活性較差。如(2,1,9)格式的Viterbi譯碼器,只能滿足約束長度為9的信息序列。
為滿足不同類型通信標準及傳輸速度的要求,設(shè)計一種能夠滿足多種標準的Viterbi譯碼器十分必要。從本質(zhì)上看,Viterbi譯碼器完成的操作無非是分支度量計算、加比選、回溯,存在著很多的共性。在追求滿意解而非完美解的情況下,完全可以設(shè)計一種在相似通信標準下的“專用”體系結(jié)構(gòu)。采取這種折衷的方法,不但可以避免通用體系架構(gòu)設(shè)計出來的譯碼芯片在性能及成本上的尷尬,還可以具有一定的重用性。本文的研究重點在于實現(xiàn)可編程Viterbi譯碼器,制定系統(tǒng)架構(gòu)并完成各模塊的設(shè)計。
1 Viterbi譯碼器設(shè)計
Viterbi譯碼器主要由分支度量計算模塊(即路徑度量模塊,BMG單元)、加比選單元(ACS單元)、路徑度量存儲管理單元(MMU單元)、路徑回溯單元(TB單元)和幸存路徑存儲管理單元(SMU單元)五部分組成。Viterbi譯碼器整體結(jié)構(gòu)圖如圖1所示。
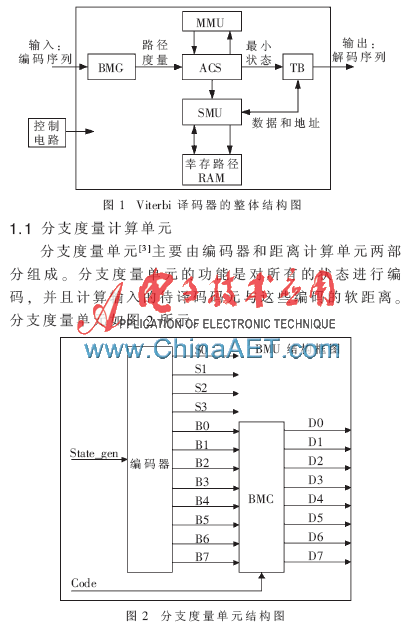
圖2中,編碼器與數(shù)據(jù)發(fā)送端使用的編碼格式相同,此處編碼器的功能是對每個狀態(tài)進行編碼,然后與輸入的信息進行比較,求出其分支度量,即求其每個狀態(tài)的期望值。距離計算單元主要用來計算輸入待譯碼單元與狀態(tài)編碼之間的差異,并將這些差異送往對應(yīng)的加比選單元。
1.2 加比選單元
加比選單元[4-5]作為Viterbi譯碼器的主要組成部分,其主要作用是將分支度量單元(BMU)送來的分支度量與路徑度量單元(PMU)中的路徑度量值進行累加,并且對每個分支的路徑度量值進行比較,挑選出較小的一個將其存入PMU,并且標識出該最小值來源于哪個分支(0分支還是1分支),即所謂的幸存比特,將其存到SMU中。在每次選擇出最小路徑度量時,將其存儲起來,到下一個狀態(tài)選出最小路徑度量時,將二者進行比較,存儲較小的一個及其狀態(tài)。當達到回溯深度時,將最小狀態(tài)送給TBU單元進行回溯。
1.3 路徑度量存儲管理單元
路徑存儲單元[6]PMU主要負責Viterbi譯碼過程中路徑度量的存儲管理,在每個處理時鐘,向加比選單元提供所需的路徑度量值,在加比選運算結(jié)束之后將新的路徑度量存儲。整個PMU的結(jié)構(gòu)框圖如3所示。

Interface_P_S主要用在鏈接PMU與ACS單元的接口部分,用來將加比選單元送過來的4路并行路徑度量值轉(zhuǎn)換成串行信息后依次存入PMU_RAM;Interface_S_P也是PMU與ACS單元的接口部分,它與前者的作用剛好相反,它是將PMU中取來的4路路徑度量信息轉(zhuǎn)換成4路并行的路徑度量值,然后送入到ACSU進行運算。
1.4 幸存路徑度量存儲管理單元
幸存路徑存儲單元[7-10](SMU)用來存儲每一輪ACS單元產(chǎn)生的幸存比特信息。當達到譯碼深度時,再將其傳遞給回溯單元進行譯碼。在硬件電路設(shè)計中,如果得到所有信息的幸存比特信息之后再進行譯碼,必將產(chǎn)生較大的延遲。即使不考慮延遲,存儲大量的比特信息對存儲的要求也是無限大的,因此需存儲回溯譯碼深度范圍內(nèi)的幸存信息,當達到譯碼深度之后,將其取出立即進行譯碼,從而可以大大地節(jié)省硬件資源。SMU的設(shè)計電路圖如4所示。
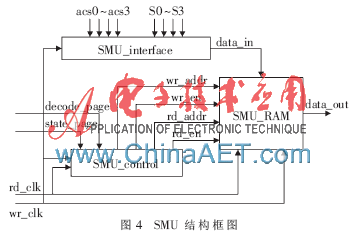
SMU_interface的主要作用是將每個處理周期的4個ACS單元的處理結(jié)果暫存起來,當所有狀態(tài)處理完成之后,將data_in值傳送給SMU_RAM 。SMU_RAM用來存儲之前處理所得到的幸存比特信息。SMU_Control 用來控制對SMU_RAM的讀寫控制,當碼元輸入的所有狀態(tài)(由state_page控制)都處理完成時,將data_in輸入到SMU_RAM,當達到譯碼深度(由decode_page控制)時,將SMU_RAM中的數(shù)據(jù)輸出到回溯單元。因為SMU_RAM中數(shù)據(jù)的存儲是按照處理decode_page的順序進行的,因此讀地址必須使用一個減法計數(shù)器來實現(xiàn),初始值設(shè)置為回溯譯碼深度。
1.5 回溯單元
回溯單元[11](TBU)也是Viterbi譯碼器的一個重要組成部分,它的主要功能是對SMU_RAM中的幸存信息進行回溯并產(chǎn)生譯碼信息。回溯單元的結(jié)構(gòu)框圖如圖5 所示。
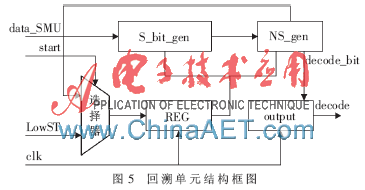
當達到回溯譯碼深度,且當前所處理的所有狀態(tài)的度量計算結(jié)束之后,TBU開始工作,將Start信號設(shè)置為1,通過選擇器MUX將加比選單元計算得出的最小狀態(tài)Low_state通過寄存器REG作為當前狀態(tài)送給幸存比特產(chǎn)生模塊S_BIT_GEN和次態(tài)產(chǎn)生模塊NS_GEN進行處理,其后Start信號一直為低,直到下次到達譯碼深度再將其置為1。因此,其余時刻選擇器輸出端一直連接NS_GEN送來的次狀態(tài)Next_State,將其暫存在REG中作為當前狀態(tài)。在模塊S_BIT_GEN中可以求出現(xiàn)態(tài)的幸存比特S_bit=DATA_SMU[Current_state]。由蝶形運算過程可以分析得出,根據(jù)當前狀態(tài)的幸存比特可以在NS_GEN模塊中反推出現(xiàn)態(tài)的上一個狀態(tài),也就是次態(tài)Next_State。有了現(xiàn)態(tài)和現(xiàn)態(tài)的幸存比特信息,就可以知道這個現(xiàn)態(tài)是由上一輪ACS運算的哪個狀態(tài)轉(zhuǎn)移而來的。因此,可以根據(jù)Viterbi譯碼算法依次找到每一個時刻的最小狀態(tài)。NS_GEN可由當前狀態(tài)產(chǎn)生正確的譯碼輸出。
2 性能比對
為了能夠科學地比較兩種Viterbi譯碼器實現(xiàn)方法的性能優(yōu)劣,兩種設(shè)計均采用了卷積編碼格式(2,1,7),并且設(shè)計和實現(xiàn)均采用Xilinx公司的ISE工具,FPGA工具均采用Virtex4,對兩種設(shè)計電路進行綜合。
經(jīng)FPGA綜合結(jié)果表明,ASIC實現(xiàn)的Viterbi譯碼器的最大頻率大于可編程Viterbi譯碼器的最大頻率,具體對比結(jié)果如表1所示。

根據(jù)Viterbi譯碼器兩種實現(xiàn)方式的性能對比可以發(fā)現(xiàn),ASIC實現(xiàn)的Viterbi譯碼器速度較優(yōu),比可編程Viterbi譯碼器的最大工作頻率高出30 MHz,而且使用的資源相對較少,在同一時鐘工作頻率下,兩種譯碼器的吞吐量基本相等,但是,采用可編程方式實現(xiàn)的Viterbi譯碼靈活性較大,可以滿足多種方式卷積編碼的譯碼。因此,可以根據(jù)實際應(yīng)用合理選擇譯碼器的實現(xiàn)。
參考文獻
[1] 陶杰,王欣,張?zhí)燧x.基于VHDL語言的卷積碼和Viterbi譯碼的實現(xiàn)[J].微型機與應(yīng)用,2012,31(16):3-5.
[2] 王新梅,肖國鎮(zhèn).糾錯碼——原理與方法[M].西安:西安電子科技大學大學出版,2001.
[3] FORNEY J G D.The Viterbi Algorithm[J].Proceedings of the IEEE,1973,61(3):268-278.
[4] 周炯槃,龐沁華.通信原理[M].北京:北京郵電大學出版社,2002.
[5] FETTWEIS G,MEYR H.Parallel Viterbi algorithm implementation:Breaking the ACS-bottleneck[J].Communications,IEEE Transactions on,1989,37(8):785-790.
[6] RADER C.Memory management in a Viterbi decoder[J].Communications,IEEE Transactions on,1981,29(9):1399-1401.
[7] 付永慶,孫曉巖,李福昌.實現(xiàn)Viterbi譯碼器幸存路徑存儲及譯碼輸出的一種新方法[J].應(yīng)用科技,2003,30(3):25-26.
[8] FEYGIN G,GULAK P.Architectural tradeoffs for survivorsequence memory management in Viterbi decoders[J].Communications,IEEE Transactions on,1993,41(3):425-429.
[9] BLACK P J,MENG T H Y.Hybrid survivor path architec tures for Viterbi decoders[C].Acoustics,Speech,and Signal Processing,ICASSP-93,1993 IEEE International Conference on,1993,1:433-436.
[10] TRABER M.A low power survivor memory unit for sequential Viterbi-decoders[C].Circuits and Systems,ISCAS 2001,2001 IEEE International Symposium on,2001,4:214-217.
[11] BAEK J G,YOON S H,CHONG J W.Memory efficient pipelined Viterbi decoder with look-ahead trace back[C].Electronics,Circuits and Systems,ICECS 2001,the 8th IEEE International Conference on,2001,2:769-772.