
多核處理器" title="多核處理器" target="_blank">多核處理器環(huán)境下的編程挑戰(zhàn)
摩爾定律問世40余年來,人們業(yè)已看到半導(dǎo)體芯片制造工藝水平以一種令人目眩的速度在提高,Intel微處理器的最高主頻甚至超過了4G。雖然主頻的提升一定程度上提高了程序運行效率,但越來越多的問題也隨之出現(xiàn),耗電、散熱都成為阻礙設(shè)計的瓶頸所在,芯片成本也相應(yīng)提高。當單獨依靠提高主頻已不能實現(xiàn)性能的高效率時,雙核乃至多核成為了提高性能的唯一出路。隨著AMD率先打破摩爾定律、終結(jié)頻率游戲后,Intel和AMD都開始逐步推出了基于雙核、四核甚至八核的處理器,工程師們逐漸投入到基于多核處理器的新型應(yīng)用開發(fā)中去時,大家開始發(fā)現(xiàn),借助這些新的多核處理器,并在應(yīng)用開發(fā)中利用并行編程技術(shù),可以實現(xiàn)最佳的性能和最大的吞吐量,大大提高應(yīng)用程序的運行效率。
然而,業(yè)界專家們也同時認識到,對于實際的編程應(yīng)用,多核處理器的并行編程卻是一個巨大的挑戰(zhàn)。比爾蓋茨是這樣論述的:
“要想充分利用并行工作的處理器的威力,…軟件必須能夠處理并發(fā)性問題。但正如任何一位編寫過多線程代碼的開發(fā)者告訴你的那樣,這是編程領(lǐng)域最艱巨的任務(wù)之一。”
比如用C++寫一個多線程的程序,程序員必須要非常熟悉 C++,了解如何將C++程序分成多個線程和并在各個線程間進行任務(wù)調(diào)度,此外還要了解 Windows 多線程的機制,熟悉 Windows API 的調(diào)用方法和MFC 的架構(gòu)等等。在 C++ 上調(diào)試多線程程序,更是被很多程序員視為噩夢。
所以,對于測試測量行業(yè)的工程師來說,在傳統(tǒng)開發(fā)環(huán)境下要想獲得多核下的效率提升意味著大量而復(fù)雜的多線程編程任務(wù),而使得工程師脫離了自動化測試及其信號處理任務(wù)本身,于是,要想在當前的多核機器上充分利用其架構(gòu)和并行運算的優(yōu)勢,反而成為工程師們“不可能”完成的任務(wù)。
LabVIEW降低并行編程的復(fù)雜性,快速開發(fā)并行構(gòu)架的信號處理應(yīng)用
幸運的是,NI LabVIEW圖形化開發(fā)平臺為我們提供了一個理想的多核處理器編程環(huán)境。作為一種并行結(jié)構(gòu)的編程語言,LabVIEW能將多個并列的程序分支自動分配成多個線程并分派到各個處理核上,讓一些計算量較大的數(shù)學(xué)運算或信號處理應(yīng)用得以提高運行效率,并獲取最佳性能。
我們以自動化測試中最常見的多通道信號處理分析為例。由于多通道中的頻率分析是一項占用處理器資源較多的操作,如果能夠讓程序并行地將每個通道的信號處理任務(wù)分配至多個處理器核,對于提高程序執(zhí)行速度來說,就顯得尤為重要。而目前,從LabVIEW編程人員的角度來看,要想獲得這一原本“不可能”的技術(shù)優(yōu)勢,唯一需要改變的只是算法結(jié)構(gòu)的細微調(diào)整,而并不需要復(fù)雜且耗時耗力的代碼重建工作。
以雙通道采樣為例,我們需要分別對高速數(shù)字化儀的兩個通道上的數(shù)據(jù)進行快速傅立葉變換(FFT)。假設(shè)我們采用的高速數(shù)字化儀的兩個通道均以100 MS/s采樣率采集信號并實時分析。首先,我們來看LabVIEW中對于這一操作的傳統(tǒng)順序編程模型。
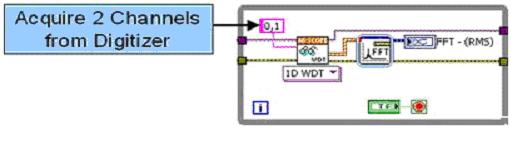
圖1. 利用順序執(zhí)行的LabVIEW代碼
和其他文本編程語言一樣,處理多通道信號的傳統(tǒng)方法是將各個通道信號按順序讀入并逐通道的進行分析,上面基于LabVIEW的順序編程模型很好的說明了這點,0、1兩通道的數(shù)據(jù)被按順序讀入后,整合為一路數(shù)組,并由一個FFT函數(shù)進行信號分析并輸出。雖然順序結(jié)構(gòu)能夠順利地在多核機器上運行,但確不能使得CPU負擔(dān)得到有效的分攤,因為即使在雙核的機器上, FFT程序也只能在一個CPU上被執(zhí)行,而此時另一個CPU卻被閑置了。
實際上,兩個通道的FFT運算相互獨立,如果程序能夠?qū)蓚€FFT自動分配到一臺雙核機器上的的兩個CPU上,那么理論上程序的運行效率將提高一倍。在LabVIEW的圖形化編程平臺上,情況正是如此,我們可以通過并行化處理這兩個通道來真正提高算法性能。圖2表示了一種采用并行結(jié)構(gòu)的LabVIEW代碼,從圖形化編程的角度來看,僅僅是增加了一路并行的FFT函數(shù)而已。
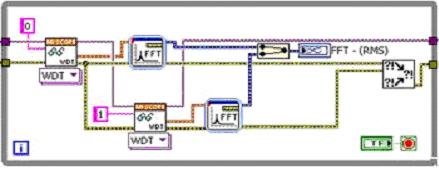
圖2. 利用并行執(zhí)行的LabVIEW代碼
由于數(shù)據(jù)量越大,信號處理運算在工程應(yīng)用中所占的處理器時間就越長,所以通過簡單的程序改動將原來的信號處理程序并行化,可以改善程序性能,減少了總的執(zhí)行時間。

圖3. 對于大于1M采樣(100 Hz精度帶寬)的數(shù)據(jù)塊,并行方式實現(xiàn)了80%或更高的性能增長。