
Turbo碼是近年來通信系統(tǒng)糾錯編碼領(lǐng)域的重大突破,他以其接近Shannon限的優(yōu)越性能博得眾多學者的青睞。在第三代移動通信系統(tǒng)中,Turbo碼在各種標準中被普遍作為高速數(shù)據(jù)業(yè)務(wù)的信道編碼方式,如何實現(xiàn)高性能的Turbo碼譯碼器,成為第三代移動通信系統(tǒng)開發(fā)中接收機基帶處理部分的重點和難點之一。Turbo譯碼" title="Turbo譯碼">Turbo譯碼器中的分量譯碼器的實現(xiàn)算法有SOVA算法,Max-Log-Map算法和Log-Map算法,其中SOVA算法復雜度最低,性能最差;Log-Map算法性能最佳,復雜度最大,本文采用基于Max-Log-Map的優(yōu)化譯碼算法,對狀態(tài)量度歸一化計算和滑動窗算法等關(guān)鍵技術(shù)進行優(yōu)化,在滿足性能要求的情況下,大大降低算法復雜度。
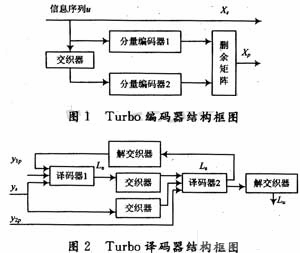
1 Turbo編碼器.譯碼器及算法
Turbo編碼器采用3G" title="3G">3GPP的編碼方案,由約束長度K為4,碼率為1/2的RSC編碼器通過1個交織器并行級聯(lián)而成,為提高性能對2個譯碼器分別附加3個尾比特使譯碼器的最終狀態(tài)為全0。
譯碼器采用反饋迭代結(jié)構(gòu),每級譯碼模塊除了交織器,解交織器外主要包括兩個級聯(lián)的分量譯碼器;一個分量譯碼器的輸出的軟判決信息經(jīng)過處理成為外信息輸入另一個分量譯碼器,形成迭代譯碼,在迭代一定級數(shù)后硬判決輸出。
編碼網(wǎng)格表貫穿整個譯碼過程,任意時刻k~k+1的RSC網(wǎng)格結(jié)構(gòu)如圖3所示,圖中編碼器輸入的0~7狀態(tài)可以由二進制表示。
下面介紹Max-Log-Map算法。
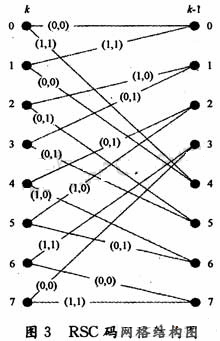
由于需要進行大量的乘法運算和指數(shù)運算,Map算法不適用于硬件實現(xiàn)。Erfanian和Pasupanthy最早提出了Map算法在對數(shù)域的簡化算*og-Map算法。通過轉(zhuǎn)換到對數(shù)域運算,避免了指數(shù)運算,同時乘法變成加法,而加法則變成Max運算,不過由此也會帶來了一定的性能損失。下面簡要描述Max-Log-Map算法。設(shè)Ak(s),Bk(s),Γk(s)分別代表對數(shù)域的前向狀態(tài)度量、后向狀態(tài)度量和分支度量,其表達式分別可表示為:
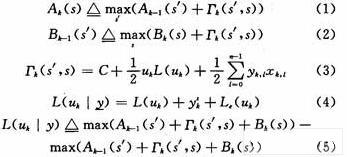
如圖3所示,每個節(jié)點狀態(tài)s都對應于一個Ak(s),1個Bk(5)和2個Γk(s)。因此編碼網(wǎng)絡(luò)貫穿整個編譯碼過程,譯碼前要先按圖3建立網(wǎng)格映射表。
2譯碼器實現(xiàn)的關(guān)鍵改進與優(yōu)化
Turbo碼譯碼是一個復雜的過程,之所以這么說,除了算法本身復雜外,還有兩個主要的原因,一個是遞推計算過程中前、反向度量不斷增大給信號處理器帶來的麻煩,即經(jīng)常說的溢出;另一個是大存儲量需求。這里,就這兩個細節(jié)問題進行討論和總結(jié),并且給出詳細解決方案。
2.1狀態(tài)量度歸一化問題
由式(1),式(2)可注意到,隨著計算的不斷深入,狀態(tài)量度值不斷增加,為防止計算溢出和減小硬件復雜度,必須對其進行歸一化處理。一種方法是減去前一時刻狀態(tài)度量的最小值,這種方法在每個時刻都需要減法器和用于計算最小值的比較器,當狀態(tài)數(shù)較多時,由此帶來的額外的時延和硬件消耗是不能忽略的。本算法采用一種十分有效的歸一化方法(以Ak(s)為例),在每個計算時刻,判斷有沒有狀態(tài)度量值(A或B)大于某一門限值T,若有則所有節(jié)點的狀態(tài)度量值(A或B)都減去T,若沒有則保持原值不變。這樣便大大減少了減法器使用的次數(shù),也無需計算最小值。由于所有的節(jié)點都減去了相同的值,因此式(5)的結(jié)果不會受到影響。T值不宜設(shè)置太大,但設(shè)置得太小,歸一化發(fā)生的很頻繁,會增加譯碼時延和硬件開銷。通過試驗仿真,若q代表狀態(tài)量度值的量化字長,則T設(shè)為2q-2為合適。
2.2 引入滑動窗減小存儲量由于Turbo碼譯碼算法的迭代特性,每一級Map譯碼器需要大量存儲器。在譯碼時引入滑動窗,能有效減少所需的存儲量。采用滑動窗的Map譯碼步驟為:每次譯碼過程被分為若干段以間隔L(假設(shè)滑動窗的長度為L,L《N)連續(xù)進行,只需在對nL長的數(shù)據(jù)進行前向處理后,每個反向子處理過程即可執(zhí)行,而未使用滑動窗時,需要對整個數(shù)據(jù)塊處理后才能進行。實驗證明,滑動窗大小選擇7~8倍的約束長度時對誤碼率的性能影響幾乎可以忽略。本算法中約束長度為4,選擇窗口大小為32。下面給出采用滑動窗譯碼前后兩種算法存儲空間分配情況的比較。假設(shè)編碼幀長為L,B表示窗口長度,L為B的整數(shù)倍。

按照表1,這個存儲空間為26L,當L=1K時,為26K。如果我們采用分塊譯碼,按照表2,那么整個譯碼的存儲需求為20B+8L,B一般取編碼約束長度的5~10倍,對于8狀態(tài)編碼,取B=32,那么這個存儲空間為640+8L,與表1的26L相比要小的多。

當L=1K時,存儲空間只占原來的33.2%。當編碼幀長L的取更大值時,存儲空間的節(jié)約更加可觀,比較得知采用滑動窗后,Turbo譯碼能夠大大節(jié)省硬件的存儲資源。
3 Turbo譯碼的DSP" title="DSP">DSP實現(xiàn)
3.1 TMS320C6416" title="TMS320C6416">TMS320C6416簡介
TM S320C6416是TI公司推出的功能強大的DSP產(chǎn)品,他采用先進的VelociTI結(jié)構(gòu),將超長指令字VLIW結(jié)構(gòu)和高并行性結(jié)合起來,通過增加指令級的并行性使其性能有了較大的飛躍。C6416的最高工作時鐘達到1 GHz,指令周期僅為1 ns,最大處理能力可以達到9 000 MIPS,比TMS320C62系列芯片性能高出15倍之多,是當前市場上最先進的定點數(shù)字信號處理器。
片內(nèi)有8個可完全并行運算的功能模塊(2個乘法器和6個算術(shù)邏輯單元),他們分為相同的兩組,屬于兩個數(shù)據(jù)通道,每個數(shù)據(jù)通道與一組32個32位寄存器相連,不同組的兩個功能模塊之間的數(shù)據(jù)交換是通過兩個寄存器組之間的交叉總線實現(xiàn)。典型片內(nèi)資源還包括1 MB的片內(nèi)RAM和一個32位的外部存儲器接口,可以支持多類型RAM,包括同步隨機訪問存儲器(SDRAM)和同步突發(fā)靜態(tài)隨機存儲器SBSRAM等。 DMA控制器包括4個可編程通道和一個輔助通道,能夠在內(nèi)存、片內(nèi)輔助資源及外部器件之間以CPU的時鐘速率實現(xiàn)高速數(shù)據(jù)傳輸,這種傳輸發(fā)生在CPU運行后臺。CPU和DMA控制器對數(shù)據(jù)存儲器的操作可以按8位字節(jié),16位半字或者32位字的長度進行。
3.2 用DSP實現(xiàn)Turbo譯碼器的優(yōu)化措施和技術(shù)
TMS320C6416的特殊結(jié)構(gòu)對編譯器和軟件設(shè)計結(jié)構(gòu)提出了很高的要求,軟件的設(shè)計與優(yōu)化將成為整個系統(tǒng)性能的決定因素,代碼的高度并行性將是獲得超強性能的關(guān)鍵。采用流水線技術(shù)和功能模塊多重化技術(shù)是開發(fā)處理器的指令級并行性的兩個主要手段。C6416對指令獲取、指令分配、指令執(zhí)行、數(shù)據(jù)存儲等階段進行了多級流水線的劃分,不同指令執(zhí)行的流水延遲也不相等,因此各種指令的安排要盡量不中斷指令流水執(zhí)行,同時,使盡可能多的功能模塊并行運行。
由于TMS320C6416芯片的結(jié)構(gòu)對于基于匯編語言的編程過于復雜,這里采用C語言編寫主程序。Turbo譯碼采用并行算法,為提高程序執(zhí)行效率,充分利用Max-Log-Map譯碼算法的結(jié)構(gòu)特點,對程序進行寄存器級優(yōu)化:把Viusal C++實現(xiàn)的浮點算法改為定點算法,將前后向累積路徑度量計算的最內(nèi)層循環(huán)展開,合理分配寄存器,使指令中參與運算的寄存器盡量屬于同一個數(shù)據(jù)通道,以減少交叉數(shù)據(jù)通道沖突,對于訪問頻繁的變量,置成寄存器型。同時利用功能強大TMS320C6416的C語言編譯器和優(yōu)化器對程序進行全程優(yōu)化,從而得到效率較高的代碼。
4測試結(jié)果及性能分析
首先在Visual C++6.0上完成信息比特的產(chǎn)生,Turbo編碼和AWGN信道加噪通過DSP的RTDX(Real-Time Data Exchange)技術(shù),把加噪后的信息比特送到TMS320C6416的EVM板上,測試其誤碼率和完成譯碼所花費的周期。譯碼器的許多參數(shù)都可以改變,如編碼長度,滑動窗大小,歸一化門限,迭代次數(shù)等。這種靈活性便于滿足不同系統(tǒng)的需要,可移植性好。本文系統(tǒng)仿真采用BPSK調(diào)制,在AWGN環(huán)境下傳輸,發(fā)送端Turbo編碼采用約束長度為4,生成矩陣為(15,13)的分量譯碼器,交織算法為3GPP標準交織算法,譯碼算法為Max-Log- Map算法。
4.1 不同迭代次數(shù)
圖4為采用1/3碼率,交織長度為1 024,迭代3,4,5次,通過AWGN信道時的誤碼率曲線。從圖中可以看到,隨著迭代次數(shù)的增加,獲得的編碼增益越高,但增加迭代次數(shù)會帶來系統(tǒng)延時和增加系統(tǒng)的譯碼復雜性。仿真充分說明了不同迭代次數(shù)對碼字糾錯性能的改善程度。

4.2 不同的交織長度
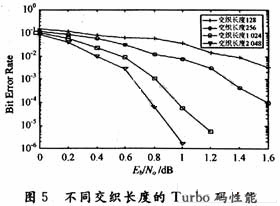
圖5采用1/3碼率,不同交織長度,5次迭代通過AWGN信道的誤碼率曲線。從圖5仿真結(jié)果看,在同樣的碼率、生成矩陣、交織算法和迭代次數(shù)條件下,所取交織長度越長,對碼字中各個比特的交織距離就越大,誤碼率性能就越好,且隨著信噪比的增加,誤碼率性能改善越明顯。但交織長度的增加也會帶來譯碼延時的增大和存儲量的增加,所以應根據(jù)業(yè)務(wù)的要求來采用不同交織長度。
4.3 不同的碼率
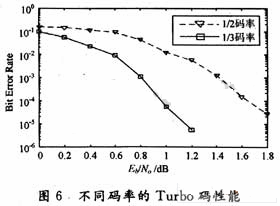
圖6為1 024交織長度,迭代譯碼5次,1/2和1/3碼率的誤碼率曲線,從圖中可以看出碼率越低誤碼率性能越好,但是隨著碼率的降低,所需傳輸?shù)娜哂啾忍匾簿€性增加,對于固定的信息傳輸率而言,會導致系統(tǒng)的吞吐率降低,需求的帶寬增加。
4.4譯碼處理時間
采用5次迭代譯碼,1 024交織長度,1/3碼率的Max-Log-Map算法在TMS6416EVM板上用CCS軟件測試得到所需要的周期數(shù)為45 867 356個時鐘周期,而TMS320C6416EVM的主頻為1 GHz,計算得到所花費的時間大約為4.5 ms,而在3G系統(tǒng)中最小延時為10 ms,所以滿足3G系統(tǒng)實時處理的要求。
5結(jié)語
本文從譯碼算法和硬件存儲方法對Max-Log-Map算法進行優(yōu)化,使他在譯碼性能損失滿足要求的情況下,能大大降低算法復雜度,減少運算量和緩存器數(shù)量。
實驗表明,本文實現(xiàn)的Turbo碼在3G系統(tǒng)中具有良好的性能和實用價值。