
摘 要: 介紹了Turbo碼和交織技術(shù)以及交織技術(shù)在Turbo碼中的重要作用,提出了一種交織器" title="交織器">交織器電路的設(shè)計(jì)思路, 進(jìn)行了信道的性能仿真,并比較了其性能。根據(jù)此設(shè)計(jì)思路,用Verilog HDL語言設(shè)計(jì)了交織器電路,并給出了仿真結(jié)果,驗(yàn)證了設(shè)計(jì)的正確性。
關(guān)鍵詞: WCDMA Turbo碼 交織器 硬件描述語言
法國人C.Berrou等在1993年首先提出了Turbo碼[1], 它是在綜合過去幾十年來的級聯(lián)碼、乘積碼、最大后驗(yàn)概率譯碼與迭代譯碼等理論的基礎(chǔ)上的一種創(chuàng)新。它在低信噪比" title="信噪比">信噪比下表現(xiàn)出了接近Shannon限的性能,超過了其他編碼方法。因此,自Turbo碼推出后便引起了各國研究者的極大興趣。經(jīng)過研究發(fā)現(xiàn),Turbo碼不同于以往的其它編碼,表現(xiàn)出了極佳的性能,其中一個重要原因就是采用了隨機(jī)交織器。
Turbo碼的基本原理是,通過編碼器的巧妙構(gòu)造,即多個子碼通過交織器進(jìn)行并行或串行級聯(lián)(PCC/SCC),然后進(jìn)行迭代譯碼,從而獲得卓越的糾錯性能。在Turbo碼的編解碼中,無論是編碼還是解碼,交織單元都是其中很重要的一環(huán)。圖1所示為Turbo編譯碼的原理框圖。在子譯碼器1與子譯碼器2之間的前向通路和反饋通道分別存在交織和解交織單元, 交織器在Turbo碼的構(gòu)造中是一個極其重要的因素。Turbo碼中交織器的主要作用是減少校驗(yàn)比特間的相關(guān)性,進(jìn)而在迭代譯碼過程中降低誤比特率。C.Berrou等人在Turbo碼提出伊始就給出了設(shè)計(jì)性能較好的交織器的特點(diǎn)和基本原則[2]:(1)通過增加交織器的長度,可以使譯碼性能得到提高;(2)交織器應(yīng)該使輸入序列盡可能隨機(jī)化,從而避免編碼生成低重碼字,導(dǎo)致Turbo碼自由距離減少。本文將就Turbo碼中交織器參數(shù)的選擇、性能和實(shí)現(xiàn)進(jìn)行探討。

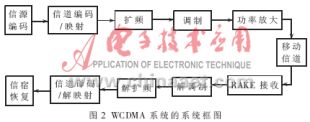
WCDMA移動通信系統(tǒng)技術(shù)標(biāo)準(zhǔn)是由國際性第三代合作組織(3GPP" title="3GPP">3GPPwww.3gpp.org)支持并維護(hù)的。3GPP主要是由歐洲和日本的標(biāo)準(zhǔn)組織和公司組成。WCDMA技術(shù)規(guī)范充分考慮了與第二代GSM移動通信系統(tǒng)的互操作性和對GSM核心網(wǎng)" title="核心網(wǎng)">核心網(wǎng)的兼容性。它將GSM MAP作為上層核心網(wǎng)協(xié)議,與GSM核心網(wǎng)完全兼容。關(guān)于 WCDMA信道編碼和映射的規(guī)范是 3G TS 25.212“Multinlexins and channel codns”(FDD)。圖2為WCDMA系統(tǒng)的系統(tǒng)框圖。
1 數(shù)據(jù)交織算法
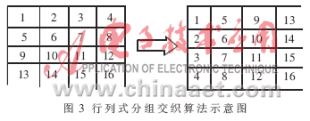
交織器是實(shí)現(xiàn)Turbo編碼的一個重要環(huán)節(jié)。它的主要作用就是將原始數(shù)據(jù)序列打亂,使交織前后數(shù)據(jù)序列的相關(guān)性減弱。這樣做的一個突出優(yōu)點(diǎn)是大大降低了數(shù)據(jù)突發(fā)錯誤的影響,以進(jìn)一步提高抗干擾性能。解交織器將交織器打亂的字節(jié)序列重新排列恢復(fù)原始碼字。按交織方式可分為分組交織器和隨機(jī)交織器兩種。其實(shí)現(xiàn)基本類型又可分為行列式分組交織、螺旋式分組交織、線性轉(zhuǎn)換式隨機(jī)交織和讀表式隨機(jī)交織等。行列式分組交織是將信息碼元序列視為 N×M矩陣,然后采取以行讀和列寫的方式實(shí)現(xiàn)碼元交織,交織后碼元的距離特性呈均勻分布;螺旋式分組交織則將碼元序列視為 N×(N+1)矩陣,然后以對角方向讀和行寫的方式交織,交織后相臨碼元距離≥N。分組交織方式簡單、對短序列交織效果較好,但交織后對碼元的去相關(guān)不徹底。線性轉(zhuǎn)換式隨機(jī)交織就是設(shè)法找到一個可逆的比特位地址映射關(guān)系T,將長度為2M" title="2M">2M數(shù)據(jù)序列的每一比特從一個緩沖區(qū)送入另一緩沖區(qū)。即m′=mT。其中m=[aM-1,aM-2,...,a1,a0]為交織前比特位地址,T為M×M可逆矩陣,T=[t,Rt,...,RM-2t, RM-1t],R為循環(huán)右移算子。這種交織器的優(yōu)點(diǎn)是不需要專門的存儲空間存放2M個映射地址[3]。但是,如此交織得到的碼元序列仍然具有較強(qiáng)的相關(guān)性。圖3、圖4分別是行列式分組交織和讀表式隨機(jī)交織算法示意圖。

2 Turbo碼交織器的優(yōu)化設(shè)計(jì)方案
2.1 設(shè)計(jì)思想
為減少可編程邏輯器件FPGA的內(nèi)部存儲器需要,交織、反交織器設(shè)計(jì)采用地址翻譯方式,也就是對交織、反交織器的讀或?qū)懙牡刂愤M(jìn)行變換。對于交織器,按行順序?qū)懭虢豢椌仃嚕豢棧瑤h除的按列輸出。對于反交織器,依據(jù)刪除陣列按列順序?qū)懭虢豢椌仃嚕唇豢棧瑤h除的按行輸出。
2.2 整體結(jié)構(gòu)的設(shè)計(jì)
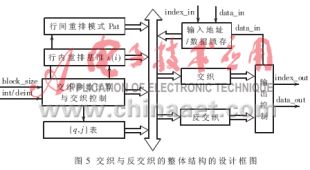
在交織深度相同時,交織器與反交織器重排控制參數(shù)相同,且在一個碼塊譯碼的多次循環(huán)迭代中均保持不變。所以同一模塊在外部信號的控制下實(shí)現(xiàn)交織和反交織功能是一種比較節(jié)省資源的方法。圖5示出了這樣的交織/反交織器結(jié)構(gòu)設(shè)計(jì)。
交織參數(shù)計(jì)算和交織控制模塊在輸入交織深度block size后,計(jì)算對應(yīng)交織圖案。包括交織矩陣行數(shù)R、列數(shù)C、行間重排模式T(j),在存儲p、v數(shù)值的ROM表中查取并計(jì)算對應(yīng)p、v數(shù)值,從而確定行內(nèi)重排基準(zhǔn)s(i)、行內(nèi)重排因子q(j)。交織參數(shù)更新發(fā)生在交織長度改變、碼塊同步信號到來的時刻。交織和反交織功能模塊從參數(shù)寄存器中獲取相同的當(dāng)前比特重排參數(shù),根據(jù)所得到的參數(shù)計(jì)算輸入比特順序號對應(yīng)的輸出比特順序號。交織或反交織功能模塊受控于交織控制工作與否。輸出控制以對應(yīng)輸出比特順序號將交織比特輸出并寫入外部DP-RAM中。
2.3 交織器的性能仿真
為了比較幾種交織方式性能的優(yōu)劣,選取生成多項(xiàng)式為g=(15,17)OCTAL的RSC[4],選取交織器的大小均為1024的情況,仿真出分組交織、對角線交織、螺旋交織、PN交織、S-隨機(jī)交織等五種不同交織方式對譯碼性能的影響。仿真結(jié)果如圖6所示,從幾條曲線的比較可以看出,S-隨機(jī)交織器的性能較之其他方式性能最好,在10-6附近,它與分組交織之間有大約0.5dB的增益。基于以上討論,筆者選擇S-隨機(jī)交織方式,在譯碼迭代次數(shù)為10的譯碼條件下,選擇迭代結(jié)構(gòu),對不同交織規(guī)模N的誤碼性能進(jìn)行了仿真,結(jié)果如圖7所示,分別給出了交織規(guī)模N為160、320、640、5120時,誤碼率隨信噪比變化而變化的曲線。顯然,在信噪比較低,SISO模塊迭代次數(shù)均為10的情況下,交織單元的規(guī)模越大,其交織的一致性越好,如圖7所示。當(dāng)N=5120時,誤碼率在信噪比略有增大時就有劇烈的衰減,表現(xiàn)出了良好的提高譯碼性能的能力。

3 基于WCDMA的144kbps交織、反交織器的具體實(shí)現(xiàn)
依據(jù)上述設(shè)計(jì)方案和性能仿真結(jié)果,采用硬件描述語言可以很方便地實(shí)現(xiàn)上述算法的交織。本設(shè)計(jì)基于ALTREA公司的Quartus環(huán)境,采用Verilog HDL語言編程,經(jīng)過FPGA驗(yàn)證。在不同性能要求下,可以選擇參數(shù)來滿足不同的要求。
由于數(shù)據(jù)速率已經(jīng)確定,根據(jù)3GPP協(xié)議:對子一個20ms的數(shù)據(jù)幀,經(jīng)過CRC-16校驗(yàn)后,幀長為2896。實(shí)現(xiàn)框圖如圖8。

圖8中,qj表、pattern表、s(i)表用片內(nèi)ROM就可以直接實(shí)現(xiàn)。計(jì)算(i*qj)mod(p-1)的模塊用乘法器和除法器搭建。它最大的好處是,在數(shù)據(jù)速率改變時,只需要相應(yīng)改變qj表、pattern表、s(i)表。
為了克服時延大的缺點(diǎn),可以將先行算出的交織圖案寫到外部的E2PROM中,但在尋址交織矩陣時,還需對地址進(jìn)行處理。這種方法的優(yōu)點(diǎn)就是速度較快,對FPGA芯片內(nèi)部的資源占用減少。交織算法關(guān)鍵環(huán)節(jié)的 HDL描述如下:
//地址計(jì)數(shù)器(用于串行輸入、輸出數(shù)據(jù)):
module addr( );
endmodule
//索引表地址發(fā)生器(用于產(chǎn)生隨機(jī)交織地址):
module addr_index( );
endmodule
//交織器狀態(tài)機(jī):
module interleaver_state( );
always @(state)
begin
case (state)
……
endcase
end
always @(posedge clk)
begin
……
end
endmodule
圖9就是一個交織深度為43的交織器的部分工作時序圖,這個交織器的設(shè)計(jì)方案即采用片內(nèi)ROM存儲交織矩陣和刪除矩陣。

參考文獻(xiàn)
1 Berrou C,Galavieux A,Thitimajshima P.Near Shannon limit error-correcting coding and decoding: Turbo-codes:Turbo-codes.IEEE International Conference on Communication,1993;1064~1070
2 K.Andrews, C.Heegard, D.Kozen.A theory of interleavers.Tech.Rep.97-1634.June 1997
3 O.Y.Takeshita,D.J.Costello Jr.New deterministric interleaver design for turbo codes.IEEE Trans. Inform.Theory.2000;46(9):1998~2006
4 Jinhong Yuan,Branka Vucetic and Wen Feng.Combined Turbo Codes and Interleaver Design[J].IEEE Trans.on Communications.1999;47(4):484~487
5 張中培, 靳蕃. 從相關(guān)分析Turbo碼交織器的設(shè)計(jì)[J]. 成都:電子科技大學(xué)學(xué)報(bào),2000;29(1):25~28