
摘 要: 以網(wǎng)絡(luò)評(píng)論為研究對(duì)象,試圖把隱馬爾科夫模型從已經(jīng)成功應(yīng)用的模式識(shí)別領(lǐng)域推廣到語(yǔ)義傾向性分析系統(tǒng)。與傳統(tǒng)傾向性識(shí)別系統(tǒng)不同的是,此理論通過(guò)建立隱馬爾科夫分類模型,將未知文本進(jìn)行狀態(tài)序列化,得到文本中所有的詞語(yǔ)所對(duì)應(yīng)的傾向性,然后選定多數(shù)詞的傾向性來(lái)作為文本的總體語(yǔ)義傾向。實(shí)驗(yàn)表明,當(dāng)訓(xùn)練數(shù)據(jù)越全面、規(guī)模越大時(shí),識(shí)別率越高。
關(guān)鍵詞: 語(yǔ)義傾向性;隱馬爾科夫模型;序列化
網(wǎng)絡(luò)媒體被公認(rèn)為是繼報(bào)紙、廣播、電視之后的“第四媒體”,成為反映社會(huì)輿情的主要載體之一。人們希望能快速高效地在浩如煙海的網(wǎng)絡(luò)信息中提取對(duì)于諸如人物、事件、傳媒、產(chǎn)品等有價(jià)值的評(píng)價(jià)信息。如何有效地提取文本信息,推斷其語(yǔ)義傾向,已經(jīng)成為當(dāng)前自然語(yǔ)言與信息安全研究領(lǐng)域的熱點(diǎn)問(wèn)題[1]。
當(dāng)前流行的語(yǔ)義傾向性分析系統(tǒng)可以分為兩個(gè)步驟:首先是識(shí)別詞匯的語(yǔ)義(短語(yǔ))傾向性[2],然后利用不同的策略根據(jù)詞匯(短語(yǔ))的傾向性給出整個(gè)文本的語(yǔ)義傾向評(píng)價(jià)。目前主要有三種研究思路:(1)對(duì)所有詞匯的傾向性評(píng)分進(jìn)行統(tǒng)計(jì)求和,根據(jù)最終的得分正負(fù)來(lái)評(píng)價(jià)文本的傾向性[3]。(2)采用機(jī)器學(xué)習(xí)的方式根據(jù)詞匯的傾向性訓(xùn)練出語(yǔ)義傾向分類器[4],這是目前比較流行的思路,總體效果比統(tǒng)計(jì)求和要好。這兩種思路是基于概率統(tǒng)計(jì)的,領(lǐng)域性限制小。(3)基于“格語(yǔ)法”分析的思路。該思路很難全面反應(yīng)樣本空間規(guī)律,具有一定的領(lǐng)域限制性。
本文利用隱馬爾科夫模型HMM(Hidden Markov Models)在文本處理方面的優(yōu)勢(shì),首先對(duì)其理論進(jìn)行介紹,然后根據(jù)現(xiàn)有學(xué)者對(duì)HMM在文本分類中的應(yīng)用和文本分類技術(shù)在傾向性分析中應(yīng)用的研究結(jié)果,提出將HMM應(yīng)用于文本傾向性研究的理論,并用實(shí)驗(yàn)證明此理論的可行性。
1 理論基礎(chǔ)
1.1 隱馬爾科夫模型
隱馬爾可夫模型[5]作為一種統(tǒng)計(jì)模型,非常適合處理時(shí)變信號(hào),用于動(dòng)態(tài)過(guò)程時(shí)間序列建模并具有強(qiáng)大的時(shí)序模式分類能力,理論上可處理任意長(zhǎng)度的時(shí)序。HMM是一個(gè)雙重隨機(jī)過(guò)程,其中之一是Markov鏈,其基本隨機(jī)過(guò)程為描述狀態(tài)的轉(zhuǎn)移;另一個(gè)隨機(jī)過(guò)程描述狀態(tài)與觀察值之間的統(tǒng)計(jì)對(duì)應(yīng)關(guān)系,只能看到觀察值,而不能看到狀態(tài),即通過(guò)一個(gè)隨機(jī)過(guò)程去感知狀態(tài)的存在及其特性。
1.2 HMM在文本分類中的應(yīng)用
羅雙虎[6]把待分類文本描述成一系列狀態(tài)演化的隱Markov過(guò)程,其中狀態(tài)以特定的概率產(chǎn)生代表文本的特征項(xiàng)。用序列模式來(lái)描述文本類,文本序列通過(guò)與隱Markov模型的匹配,求出其對(duì)應(yīng)狀態(tài)序列和最大輸出概率,以比較各個(gè)文本類的結(jié)果,達(dá)到文本分類的目的。
龍麗君[7]對(duì)關(guān)鍵字所在的句子構(gòu)成的詞序列建立HMM,以判斷句子所屬的類別。為了建立HMM,將詞語(yǔ)所屬的類別理解為狀態(tài),將所選擇的關(guān)鍵字理解為輸出值。這樣就把要判定一個(gè)觀測(cè)序列(一個(gè)句子)的整體所屬的類別轉(zhuǎn)換為己知模型和觀測(cè)序列,求出全局最優(yōu)的整體序列。觀測(cè)序列的整體所屬類別即為關(guān)鍵字所屬類別,或者說(shuō)觀測(cè)序列的整體類別即為狀態(tài)序列中居多數(shù)的狀態(tài)對(duì)應(yīng)的類別。
1.3 文本分類技術(shù)在傾向性分析中的應(yīng)用
1997年,Hatzivassiloglou和McKeown嘗試使用監(jiān)督學(xué)習(xí)的方法對(duì)詞語(yǔ)進(jìn)行語(yǔ)義傾向判別,通過(guò)對(duì)訓(xùn)練語(yǔ)料的學(xué)習(xí)進(jìn)行語(yǔ)義傾向判別,準(zhǔn)確率約82%,在加入篇章中形容詞之間的接續(xù)信息后,準(zhǔn)確率提升到約90%[2]。2003年,Turney在其論文[8]中提出了利用統(tǒng)計(jì)信息對(duì)單詞進(jìn)行語(yǔ)義傾向判斷的新方法。文本的語(yǔ)義傾向判別也可被看作一個(gè)褒貶的分類問(wèn)題,因此,文本分類中的方法同樣被應(yīng)用到了語(yǔ)義傾向判別研究中。
2 HMM在語(yǔ)義傾向性研究的應(yīng)用
本文是針對(duì)網(wǎng)絡(luò)評(píng)論,判斷其表達(dá)的是支持(褒義)、反對(duì)(貶義)還是中立(中性)的語(yǔ)義傾向性。

(4)A為狀態(tài)轉(zhuǎn)移概率矩陣,即從一種詞語(yǔ)類別轉(zhuǎn)移
2.2 實(shí)驗(yàn)系統(tǒng)框架
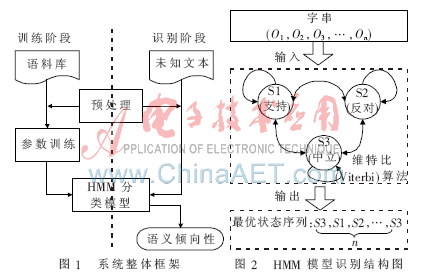
系統(tǒng)整體框架如圖1所示,整個(gè)系統(tǒng)分為訓(xùn)練階段和識(shí)別階段。
2.2.1 語(yǔ)料庫(kù)準(zhǔn)備
訓(xùn)練語(yǔ)料庫(kù)是國(guó)內(nèi)還沒(méi)有公開(kāi)的文本傾向語(yǔ)料庫(kù)。本實(shí)驗(yàn)全部由人工收集,然后對(duì)所提取的所有的句子進(jìn)行分詞、標(biāo)注之后,去掉連詞、助詞和代詞等不具傾向性的無(wú)用詞,得到最終的語(yǔ)料庫(kù)。
否定詞表:帶否定意義的詞,如:不、不是、非等。
2.2.2 訓(xùn)練階段
首先根據(jù)初始參數(shù)建立初始模型,然后使用Baum-Welch算法[5]對(duì)參數(shù)進(jìn)行訓(xùn)練,得出最終分類模型。
2.2.3 識(shí)別階段
將未知評(píng)論文本經(jīng)預(yù)處理得到字串(W1,W2,W3,…,Wn)作為上文中訓(xùn)練得到的HMM分類模型的觀察序列,通過(guò)維特比(Viterbi)算法[5]得到最優(yōu)狀態(tài)序列S,然后使用以下算法得出整個(gè)語(yǔ)句的語(yǔ)義傾向性,如圖2所示。
Array<Word> W;//字串
Array<State> S;//最優(yōu)狀態(tài)序列
Dictionary Deny;//否定詞表
Integer Length;//字串長(zhǎng)度,即字串中詞語(yǔ)的數(shù)目
Procedure getOrientation ()
//句子傾向性為狀態(tài)序列中具有傾向(非中立)的狀態(tài)占多數(shù)的狀態(tài)所對(duì)應(yīng)的傾向
//由于網(wǎng)絡(luò)評(píng)論中作者的傾向多數(shù)是在句首,取首個(gè)具有語(yǔ)義傾向的狀態(tài)對(duì)應(yīng)的傾向?yàn)檎麄€(gè)句子的語(yǔ)義傾向性
Orientation orientation=“中性”;
Integer numP=0;//S1(支持)的數(shù)量
Integer numN=0;//S2(反對(duì))的數(shù)量
Orientation firstOrientation;//記錄句子中首個(gè)非中性的狀態(tài)
For i ← 0 to Length-1 do
If S[i]!=S3 then
If i>0 and W[i-1] ∈Deny then
//此狀態(tài)不是句首且此狀態(tài)對(duì)應(yīng)的觀察值是否定詞時(shí)
//狀態(tài)類別以相反類別計(jì)數(shù)
S[i]==S1?numN++;numP++;
Else
S[i]==S1?numP++;numN++;
End If
If firstOrientation==NULL then
firstOrientation =(S[i]== S1?“支持”:“反對(duì)”);
End If
End If
Repeat
If numP>numN then
orientation=“支持”;
Else If numP<numN then
orientation=“反對(duì)”;
Else
orientation=firstOrientation;
End If
end getOrientation
2.3 應(yīng)用舉例
例句:“我同意你的觀點(diǎn)”。
經(jīng)分詞結(jié)果為:“我/r 同意/v 你/r 的/u 觀點(diǎn)/n”。去除無(wú)用詞得到觀察值序列為:“同意/v 觀點(diǎn)/n,最后經(jīng)過(guò)識(shí)別得出最優(yōu)狀態(tài)序列為:S1,S3。由于S1出現(xiàn)1次,而沒(méi)有出現(xiàn)S2,故這個(gè)句子的傾向性為S1的傾向類別:支持。
3 實(shí)驗(yàn)結(jié)果及分析
實(shí)驗(yàn)文本是來(lái)自不同網(wǎng)站上下載的各種評(píng)論共2 000條,所有的評(píng)論都經(jīng)過(guò)分詞、標(biāo)注和去無(wú)用詞處理,然后手工分為:支持(褒義)、反對(duì)(貶義)和中立(中性)3個(gè)類別。然后在每個(gè)類別中分別取200、300、400、500條,共600、900、1 200、1 500條作為本實(shí)驗(yàn)的訓(xùn)練數(shù)據(jù),進(jìn)行封閉測(cè)試并對(duì)剩余的評(píng)論進(jìn)行開(kāi)放測(cè)試。實(shí)驗(yàn)結(jié)果如表1、表2所示。


從表中結(jié)果可以看出,封閉測(cè)試可以達(dá)到很高的識(shí)別率,可見(jiàn)訓(xùn)練語(yǔ)料庫(kù)的規(guī)模將直接影響分析結(jié)果。當(dāng)語(yǔ)料更全面、覆蓋面更廣泛時(shí),識(shí)別率將大大提高,因此建立一個(gè)良好的訓(xùn)練語(yǔ)料庫(kù)的識(shí)別方法將有很好的應(yīng)用前景。
本文從單個(gè)句子出發(fā),研究其傾向性分析方法,從實(shí)驗(yàn)結(jié)果數(shù)據(jù)可以看出,此方法有很好的識(shí)別率,但需面對(duì)兩個(gè)問(wèn)題:(1)網(wǎng)絡(luò)文本的復(fù)雜性:如語(yǔ)句的語(yǔ)氣、具有傾向性的詞語(yǔ)所針對(duì)不同的評(píng)價(jià)對(duì)象和網(wǎng)絡(luò)新詞的頻繁出現(xiàn)等情況;(2)語(yǔ)料庫(kù)的整理:語(yǔ)料庫(kù)的完整性和準(zhǔn)確性將直接影響分析方法的準(zhǔn)確率,而國(guó)內(nèi)還沒(méi)有公開(kāi)的文本傾向語(yǔ)料庫(kù)。這些問(wèn)題將做進(jìn)一步地研究和改進(jìn)。
參考文獻(xiàn)
[1] 來(lái)火堯,劉功申.基于主題相關(guān)性分析的文本傾向性研究[J].信息安全與通信保密,2009(3):77-78.
[2] HATZIVASSILOGLOU V, MEKEOWN K R. Predicting the semantic orientation of adjectives[A]. In: Proceedings of the 35th Annual Meeting of the Association for Computational Liguistics and the 8th Conference of the European Chapter of the ACL, 1997:174-181.
[3] PETER T. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews[A]. In: Proceedings of the 40th Annual Meeting of the Association for Computational Liguistics, 2002.
[4] 徐琳宏,林鴻飛,楊志豪.基于語(yǔ)義理解的文本傾向性識(shí)別機(jī)制[J].中文信息學(xué)報(bào),2007,21(01):98-102.
[5] 宗成慶.統(tǒng)計(jì)自然語(yǔ)言處理[M].北京:清華大學(xué)出版社,2008.
[6] 羅雙虎,歐陽(yáng)為民.基于隱Markov模型的文本分類[J].計(jì)算機(jī)工程與應(yīng)用,2007,43(30):179-181.
[7] 龍麗君.網(wǎng)絡(luò)內(nèi)容監(jiān)管系統(tǒng)中基于局部信息的語(yǔ)義傾向性識(shí)別算法[D].南京.南京理工大學(xué),2004.
[8] PETER T,MICHAEL L. Measuring praise and criticism: Inference of semantic orientation from association[J]. ACM Transactions on Information Systems, 2003,21(4):315-346.