
0 引言
隨著大規(guī)模集成電路的發(fā)展,在電子設(shè)備監(jiān)控系統(tǒng)中,需要采集與處理的數(shù)據(jù)量也在急劇增加,從而數(shù)據(jù)壓縮技術(shù)得到廣泛應(yīng)用。然而很多壓縮、解壓方案都是基于軟件實(shí)現(xiàn),其致命的弱點(diǎn)就是過(guò)多地消耗寶貴的CPU資源,速度慢。基于FPGA實(shí)現(xiàn)的壓縮器因其速度快、處理能力強(qiáng)而獲得人們的重視。現(xiàn)代FPGA的發(fā)展使得只用專用硬件的方式來(lái)實(shí)現(xiàn)壓縮、解壓成為可能,可以解決上述軟件實(shí)現(xiàn)方式所存在的缺點(diǎn)。但在通用數(shù)據(jù)的壓縮領(lǐng)域,基于FPGA的硬件壓縮、解壓方案還不多見,所以研究基于FPGA硬件實(shí)現(xiàn)的數(shù)據(jù)壓縮技術(shù)具有很高的應(yīng)用價(jià)值。
當(dāng)前數(shù)據(jù)壓縮技術(shù)分為有損壓縮和無(wú)損壓縮,算術(shù)編碼、游程編碼、霍夫曼和LZW壓縮是傳統(tǒng)的數(shù)據(jù)壓縮方法,屬于無(wú)損數(shù)據(jù)壓縮;而基于小波變換的數(shù)據(jù)壓縮和基于神經(jīng)網(wǎng)絡(luò)的編碼方式是近年來(lái)新發(fā)展起來(lái)的現(xiàn)代數(shù)據(jù)壓縮方法,屬于有損數(shù)據(jù)壓縮。本研究主要探討一種基于LZW算法的數(shù)據(jù)無(wú)損壓縮硬件實(shí)現(xiàn)。
1 LZW算法及其改進(jìn)算法
LZW壓縮算法在壓縮的過(guò)程中自適應(yīng)建立一個(gè)字典,以后的數(shù)據(jù)同字典中的數(shù)據(jù)相匹配,匹配上則輸出字典的索引。由于表示字典的索引所用的比特?cái)?shù)遠(yuǎn)小于字符的比特?cái)?shù),從而達(dá)到壓縮的效果。這個(gè)生成的字典不需要隨著壓縮的數(shù)據(jù)一同傳輸,而是能夠根據(jù)壓縮的數(shù)據(jù)在解壓時(shí)重新動(dòng)態(tài)生成一模一樣的字典。
LZW編碼原理如圖1所示,在進(jìn)行壓縮時(shí)首先把字典中的前256(0~255)項(xiàng)初始為全部的256個(gè)8位字符,分別為十進(jìn)制數(shù)0~255。當(dāng)輸入第一個(gè)字符時(shí),總是在字典中可以找到,直到新的字符X不在字典詞條中時(shí),便將字符串IX加入到字典的第256項(xiàng),以此類推。以字符串流5,6,7,8,9,5,5,6,6,7,8,9,5,…為例,表1給出了字典存儲(chǔ)的物理結(jié)構(gòu)和壓縮過(guò)程中字典項(xiàng)的讀寫示意。壓縮后編碼輸出為5,6,7,8,9,5,256,257,259,…。

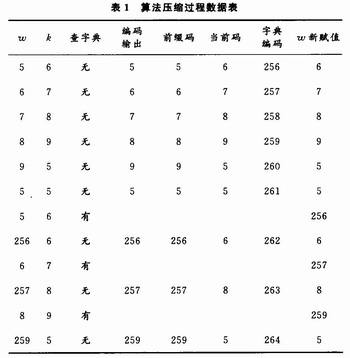
傳統(tǒng)的LZW壓縮算法采用8位數(shù)據(jù)輸入,固定長(zhǎng)度編碼輸出,隨著字典內(nèi)容的不斷增多,輸出編碼的位數(shù)不斷增加勢(shì)必造成資源的浪費(fèi),也會(huì)損失壓縮率。另外,由于字典的容量有限,隨著壓縮過(guò)程的進(jìn)行,字典會(huì)被填滿,若是簡(jiǎn)單的不再向字典中增加內(nèi)容,那么后面的壓縮率就會(huì)降低,而如果將字典全部清除重新建立字典,在字典建立初期壓縮率也是很低的。針對(duì)以上不足,文獻(xiàn)對(duì)LZW算法做以下改進(jìn):采用12位數(shù)據(jù)作為壓縮輸入,變長(zhǎng)度的碼字輸出。
壓縮字典最多可容納16 384個(gè)碼,共分為三部分,其中0~4 095為12位輸出,4 096~8 191為13位,8 192~16 383為14位。每當(dāng)輸出長(zhǎng)度變化時(shí),同時(shí)輸出一個(gè)變長(zhǎng)標(biāo)識(shí),便于解碼器解碼。
2 LZW算法FPGA實(shí)現(xiàn)
2.1 算法實(shí)現(xiàn)硬件結(jié)構(gòu)
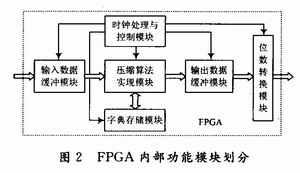
LZW數(shù)據(jù)壓縮算法的FPGA硬件實(shí)現(xiàn),其內(nèi)部功能模塊劃分如圖2所示。
2.2 各功能模塊說(shuō)明
輸入/輸出數(shù)據(jù)緩存模塊完成FPGA所有數(shù)據(jù)傳輸工作,為了保證異步時(shí)鐘域數(shù)據(jù)同步,使用FPGA片內(nèi)的Block RAM構(gòu)成一個(gè)FIFO對(duì)輸入數(shù)據(jù)進(jìn)行緩存。
字典存儲(chǔ)器模塊需要存放字典項(xiàng)的三部分內(nèi)容:字典項(xiàng)編碼、前綴碼、當(dāng)前碼。將存儲(chǔ)器的容量設(shè)計(jì)為1K。采用FPGA內(nèi)部宏單元lpm-ram-dp(單口RAM)設(shè)計(jì)字典存儲(chǔ)器。
算法實(shí)現(xiàn)模塊要實(shí)現(xiàn)匹配串的查找、判斷字典相應(yīng)地址內(nèi)容是否為空、比較字典地址相應(yīng)內(nèi)容是否匹配或沖突、沖突時(shí)重新生成地址、壓縮編碼輸出控制、壓縮結(jié)束控制等功能。
外接閃存數(shù)據(jù)寬度為8位,所以壓縮后輸出數(shù)據(jù)位數(shù)需要轉(zhuǎn)換。數(shù)據(jù)轉(zhuǎn)換模塊就是實(shí)現(xiàn)壓縮后數(shù)據(jù)由13位向8位的轉(zhuǎn)換。
時(shí)鐘處理與控制模塊主要完成時(shí)鐘的匹配與控制,對(duì)各個(gè)功能模塊分配時(shí)鐘,并初始化各使能端信號(hào)。
2.3 仿真結(jié)果
清空字典存儲(chǔ)器模塊,初始化信號(hào),將可能出現(xiàn)的單字符存入字典,壓縮時(shí)新傳續(xù)存地址為4096,新字符串輸入時(shí)產(chǎn)生相應(yīng)的哈希表地址與偏移量;然后讀字典存儲(chǔ)器相應(yīng)地址的內(nèi)容,如內(nèi)容為空則輸出輸入的數(shù)據(jù),并把相應(yīng)內(nèi)容存入字典,如內(nèi)容匹配,則繼續(xù)輸入下一數(shù)據(jù),否則(即發(fā)生沖突)產(chǎn)生新的哈希表地址,重新讀取字典,進(jìn)行判斷、比較。仿真時(shí)序如圖3所示。
仿真結(jié)果:輸入數(shù)據(jù)為5,6,7,8,9,5,6,7,8,9,5,6,7,…;輸出數(shù)據(jù)為5,6,7,8,9,4 098,4 100,4 102,…。仿真結(jié)果與理論計(jì)算值一致。
3 結(jié) 論
LZW算法邏輯簡(jiǎn)單,實(shí)現(xiàn)速度快,擅長(zhǎng)于壓縮重復(fù)出現(xiàn)的字符串;無(wú)需事先統(tǒng)計(jì)各字符的出現(xiàn)概率,一次掃描即可;相對(duì)于其他算法,更有利于硬件實(shí)現(xiàn)。本文利用FPGA實(shí)現(xiàn)了改進(jìn)的LZW壓縮算法,仿真證明其算法具有很高壓縮率,適合工程的實(shí)際應(yīng)用。