
?
The Challenge:
??? 對NI LabVIEW軟件自動生成的外部代碼進(jìn)行最優(yōu)化,在x86構(gòu)架下獲得最大性能,進(jìn)而測量目標(biāo)系統(tǒng)中DLL性能。
?
The Solution:
??? 在不修改源代碼的條件下,通過Intel C++ 編譯器在單核PC上實(shí)現(xiàn)2.5 倍提速,通過編譯器中的各類最優(yōu)化選項(xiàng)在雙核PC 上實(shí)現(xiàn)超過4.5 倍提速。
?
??? "VTune能夠監(jiān)測許多不同種類的構(gòu)架事件。VTune調(diào)諧助手能夠給出如何更好使用這些事件的建議。"
本應(yīng)用包括了兩個組件——用于計(jì)算Pi 值的DLL、調(diào)用DLL 庫函數(shù)的LabVIEW 應(yīng)用,可將結(jié)果顯示在圖形用戶界面中。
?
??? 為計(jì)算Pi 值,我們采用了近似綜合技術(shù),需要在單個循環(huán)中完成數(shù)百萬次浮點(diǎn)計(jì)算。選擇該范例是因?yàn)樗荂PU 密集型的,并且是可優(yōu)化的應(yīng)用。如下所示為外部代碼的主循環(huán)結(jié)構(gòu),CPU的主要計(jì)算量是處理CalcSum 函數(shù)。
?
for(i=0; i
sum = CalcSum(i, sum, step);
}
?
??? 我們的目標(biāo)是通過編譯器中的優(yōu)化選項(xiàng)以最快速度完成上述計(jì)算。
?
??? 應(yīng)用中有4 個函數(shù),均包含于獨(dú)立源文件中。我們采用不同優(yōu)化開關(guān)來編譯每個源文件。如圖1 所示。
?
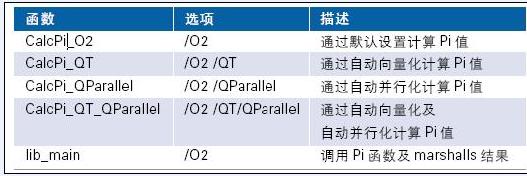
表1.應(yīng)用中的函數(shù)
?
“即插即用”的Intel C++ 編譯器
?
??? 我們采用即插即用的Intel C++ 來代替Microsoft 編譯器,它可以輕松地集成到現(xiàn)有Microsoft Visual Studio DLL 工程中。更多關(guān)于Intel 編譯器,請?jiān)L問intel.com/software。
?
默認(rèn)設(shè)置
?
??? 測量首先以/O2選項(xiàng)創(chuàng)建應(yīng)用,許多優(yōu)化都是在這個層面上進(jìn)行的。本文在此不討論其細(xì)節(jié)問題。表2顯示了/O2選項(xiàng)集成的各個優(yōu)化設(shè)置。
?
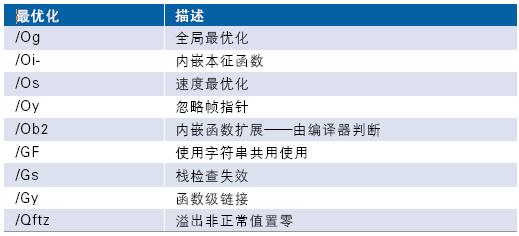
表2./O2 選項(xiàng)中集成的最優(yōu)化列表
?
自動向量化
?
??? 自動向量化得益于新一代CPU 中集成的復(fù)雜指令集。多數(shù)現(xiàn)代CPU構(gòu)架可擴(kuò)展支持?jǐn)?shù)據(jù)操作及多數(shù)據(jù)計(jì)算。擴(kuò)展包括支持以單一指令實(shí)現(xiàn)多重計(jì)算(單指令多數(shù)據(jù)流,或稱SIMD)。Intel 編譯器能夠分析代碼,并通過SIMD 指令顯著提高代碼的效率。
?
??? 本范例中,編譯器通過\QT 選項(xiàng)生成適合Core 2 構(gòu)架的代碼,編譯器報告以下創(chuàng)建時間信息:
?
??? 注釋:循環(huán)未作向量化處理
?
??? 反匯編生成代碼后可看到編譯器插入了SIMD擴(kuò)展指令集(SSE)。該指令集的使用直接提升了應(yīng)用的運(yùn)行性能,代碼運(yùn)行速度提高了2倍。
?
??? 這類優(yōu)化可應(yīng)用于目前大多數(shù)CPU 上,這里我們在Core 2 處理器上運(yùn)行,當(dāng)然您也可以在單核或早期CPU 上應(yīng)用。
?
自動并行化
?
??? 因?yàn)椴捎?a class="innerlink" href="http://forexkbc.com/tags/多核" title="多核" target="_blank">多核PC,我們會更感興趣如何通過\QParallel 選項(xiàng),讓代碼在兩核上同時運(yùn)行,以獲得進(jìn)一步提速。該選項(xiàng)在編譯目標(biāo)中插入了庫調(diào)用。庫調(diào)用提供了運(yùn)行時所需的控制,使應(yīng)用中的組件得以并行。
在首次運(yùn)行中,編譯器并未顯著提高運(yùn)行性能。通過開啟編譯器的報告功能,可以看到它并未進(jìn)行優(yōu)化。
?
??? 注釋:循環(huán)未作并行化處理,循環(huán)無需并行化
?
??? Intel編譯器要對一段代碼進(jìn)行自動并行化時,首先決定是否有值得進(jìn)行并行化的代碼部分。在我們的代碼中由一個主循環(huán)完成所有工作。編譯器不能確定循環(huán)的重復(fù)次數(shù),循環(huán)計(jì)數(shù)值只有在運(yùn)行時得到。于是編譯器采取謹(jǐn)慎選擇,不對循環(huán)進(jìn)行并行化處理。
?
??? 我們可以通過在命令行輸入/Qpar-threshold:n 來進(jìn)行試探優(yōu)化,這里n 是介于0(總是并行處理)到100(不進(jìn)行并行處理)的數(shù),這個值決定了試探優(yōu)化的程度。
?
??? 輸入/Qpar-threshold:0 后,編譯器對代碼并行化,并輸出報告:
?
??? 注釋:循環(huán)已作自動并行化處理
?
??? 使用該優(yōu)化后,程序的運(yùn)行速度比默認(rèn)設(shè)置下提高了近2 倍。
?
其它優(yōu)化選項(xiàng)
?
??? 本范例中,我們關(guān)注自動向量化及自動并行化。Intel C++ 編譯器利用一系列其它優(yōu)化技術(shù),包括高層優(yōu)化、交叉過程優(yōu)化、配置向?qū)?yōu)化、速度優(yōu)化、代碼大小優(yōu)化、快速浮點(diǎn)處理等。
?
??? Intel 編譯器同時支持OpenMP 這個基于pragma 的標(biāo)準(zhǔn),用于實(shí)現(xiàn)應(yīng)用代碼的并行化。
?
測量性能
?
??? 本范例中我們采用Win32 API 的定時函數(shù),并將定時計(jì)算嵌入外部代碼。計(jì)算時間在LabVIEW 應(yīng)用GUI 中顯示。
?
??? 作為備選,我們還可采用LabVIEW的定時工具,或采用外部工具,如Intel VTune 性能分析器。
?
??? VTune能夠監(jiān)測許多不同種類的構(gòu)架事件。VTune調(diào)諧助手能夠給出如何更好使用這些事件的建議。
?
結(jié)論
?
??? 不同開關(guān)的優(yōu)化結(jié)果在表3 中列出。我們在雙核PC 上運(yùn)行,并通過默認(rèn)優(yōu)化(/O2)作為基準(zhǔn)來計(jì)算提速。
?
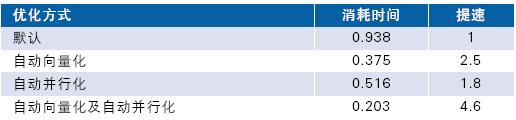
表3.不同優(yōu)化方式下的速度提高
?
??? 在應(yīng)用自動向量化時可達(dá)到2.5倍速,該優(yōu)化專用于非多核處理器,可用于目前多數(shù)CPU。
?
??? 在應(yīng)用自動并行化后可實(shí)現(xiàn)接近2 倍的提速。結(jié)合兩種優(yōu)化更可達(dá)到4.6 倍。
?
??? 以上結(jié)果是在不修改源代碼的前提下實(shí)現(xiàn)的。盡管我們選擇了模擬應(yīng)用(計(jì)算Pi值),但這類優(yōu)化技術(shù)能夠用于各類實(shí)際應(yīng)用。從Intel編譯器用戶反饋中了解到,使用這些優(yōu)化方式可顯著提高代碼執(zhí)行速度。
?
?