
3G手機(jī)語音識(shí)別應(yīng)用中DSP的選擇策略
摘要: 由于系統(tǒng)要實(shí)時(shí)對(duì)語音進(jìn)行處理和取樣,因此語音識(shí)別系統(tǒng)需要具有巨大的計(jì)算能力。下面的數(shù)字和計(jì)算假設(shè)采用的是圍繞終端的設(shè)計(jì)方法。如果將DSP計(jì)算資源的20%分配給一個(gè)10MMAC的語音識(shí)別系統(tǒng)使用,那么就需要一個(gè)具有50MMAC的DSP才能滿足這一功能需要,并可提供足夠的空間執(zhí)行3G手機(jī)所需的其它DSP任務(wù),如處理軟貓。如果采用較慢的DSP,如25MMAC的DSP,那么詞匯表中的命令數(shù)量就要減半,或減少HMM參數(shù),這樣會(huì)降低整個(gè)系統(tǒng)性能。
Abstract:
Key words :
隨著DSP技術(shù)的進(jìn)步,計(jì)算能力更強(qiáng)、功耗更低和體積更小的DSP已經(jīng)出現(xiàn),使3G手機(jī)上植入更精確更復(fù)雜的自動(dòng)語音識(shí)別(ASR)功能成為可能。目前,基本ASR應(yīng)用可以分成三大類:1. 語音-文本轉(zhuǎn)換(語音輸入);2. 講者識(shí)別;3. 語音命令控制(語音控制)。
這三類功能包含了3G所需的眾多ASR性能。語音-文本轉(zhuǎn)換的典型實(shí)例是語音撥號(hào)和電子郵件聽寫。講者識(shí)別功能可以通過語音識(shí)別安全地讀出存儲(chǔ)器中的個(gè)人數(shù)據(jù),從而滿足*定購和銀行服務(wù)等保密性高的應(yīng)用需要。語音命令控制功能包括連接語音擴(kuò)展標(biāo)記語言(VXML)網(wǎng)站內(nèi)容的語音接口,它支持財(cái)經(jīng)服務(wù)與目錄助理等業(yè)務(wù)。目前VXML被用于規(guī)范網(wǎng)站內(nèi)容的語音標(biāo)簽。
語音識(shí)別的兩種方法
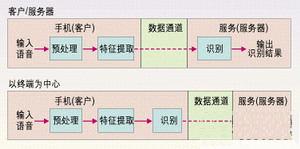
3G手機(jī)的ASR應(yīng)用設(shè)計(jì)可分為兩類,即以終端為中心和以客戶/服務(wù)器為中心的應(yīng)用。如圖1所示為以終端為中心的設(shè)計(jì)方法,3G手機(jī)(終端)執(zhí)行整個(gè)語音識(shí)別過程并送出識(shí)別結(jié)果。在圖2所示的客戶/服務(wù)器方法中,終端只是執(zhí)行預(yù)處理特征提取,然后通過一個(gè)誤碼受保護(hù)的數(shù)據(jù)信道將這些參數(shù)發(fā)送給中心服務(wù)器,中心服務(wù)器最終完成語音識(shí)別。如果采用以客戶/服務(wù)器為中心的設(shè)計(jì)方法,3G手機(jī)應(yīng)使用數(shù)據(jù)信道而非移動(dòng)信道來將語音發(fā)送給服務(wù)器進(jìn)行識(shí)別,因?yàn)橐苿?dòng)信道所用的低速率語音編碼會(huì)嚴(yán)重影響語音識(shí)別的性能。
各種ASR系統(tǒng)的差異主要體現(xiàn)在詞匯量上。一個(gè)簡(jiǎn)單的網(wǎng)絡(luò)設(shè)備可能只需要16字的詞庫就能實(shí)現(xiàn)所要求的語音識(shí)別功能,而3G移動(dòng)手機(jī)則需要更大的專業(yè)詞庫。這些詞匯可以跟講者相關(guān)(訓(xùn)練語音識(shí)別設(shè)備使之熟悉用戶的聲音特征)或跟講者無關(guān)(語音識(shí)別設(shè)備可以識(shí)別任何人的聲音),DSP的計(jì)算負(fù)荷就隨著詞匯量和訓(xùn)練數(shù)據(jù)的增加而增大。
例如,根據(jù)隱性馬爾可夫模型(HMM)可以分析一個(gè)典型的跟講者無關(guān)的100條命令識(shí)別的應(yīng)用實(shí)例。假設(shè)HMM模型從左到右沒有跳躍地順序擺放,共有6個(gè)狀態(tài)、5個(gè)具有對(duì)角協(xié)方差的混合高斯分布,包含39個(gè)特征(13嘜-頻率對(duì)數(shù)系數(shù)或MFCC,及其一階和二階差分),具有16位精度,那么,HMM聲學(xué)模型的大小就是100×5×5×(39+2)×2=240kB。
為了實(shí)現(xiàn)輸入語音樣本差分、窗口截獲、MFCC抽取、概率計(jì)算和維特比搜索等運(yùn)算的實(shí)時(shí)性,典型情況下需要消耗DSP的1千萬個(gè)乘法-累加周期(MMAC)。對(duì)于連續(xù)語音識(shí)別來說,上千個(gè)三音素模型和多種語法模型需要更多的存儲(chǔ)空間,也需要更快的DSP處理速度。
因此,移動(dòng)電話中ASR系統(tǒng)的成敗很大程度上取決于DSP的功能和設(shè)計(jì)。第三代系統(tǒng)本身就需要比第二代系統(tǒng)更強(qiáng)性能的DSP,而增加ASR功能就對(duì)DSP提出了更高的要求。從結(jié)構(gòu)角度看,對(duì)DSP性能的要求是處理速度快、功耗低和代碼密度高。
采用高速DSP是關(guān)鍵
由于系統(tǒng)要實(shí)時(shí)對(duì)語音進(jìn)行處理和取樣,因此語音識(shí)別系統(tǒng)需要具有巨大的計(jì)算能力。下面的數(shù)字和計(jì)算假設(shè)采用的是圍繞終端的設(shè)計(jì)方法。如果將DSP計(jì)算資源的20%分配給一個(gè)10MMAC的語音識(shí)別系統(tǒng)使用,那么就需要一個(gè)具有50MMAC的DSP才能滿足這一功能需要,并可提供足夠的空間執(zhí)行3G手機(jī)所需的其它DSP任務(wù),如處理軟貓。如果采用較慢的DSP,如25MMAC的DSP,那么詞匯表中的命令數(shù)量就要減半,或減少HMM參數(shù),這樣會(huì)降低整個(gè)系統(tǒng)性能。
DSP的速度決定了語音識(shí)別系統(tǒng)的復(fù)雜性和性能。舉例來說,如果一個(gè)基本的跟講者無關(guān)的連續(xù)語音識(shí)別系統(tǒng)需要100MMAC,DSP計(jì)算資源的50%用于滿足3G手機(jī)的其它DSP任務(wù)的需求,那么DSP的處理速度就需要達(dá)到200MMAC。
成本、性能和效率的折衷
DSP的速度越快,就越便于利用現(xiàn)代的HMM技術(shù),如信道匹配和聲域匹配技術(shù),因此,理論上講,DSP速度越快,ASR系統(tǒng)的性能就越好。然而,并行處理方法在提高ASR系統(tǒng)吞吐量中也扮演著重要角色。例如,一個(gè)具有4 ALU(算術(shù)邏輯單元)的200MHz DSP比只有1 ALU但運(yùn)行于400MHz的DSP具有更高的吞吐量。根據(jù)具體應(yīng)用的不同,2到3個(gè)單ALU DSP提供的性能與一個(gè)具有4 ALU的DSP相仿。相對(duì)一個(gè)具有4 ALU的DSP處理器方案來說,多個(gè)單ALU的DSP會(huì)提高手機(jī)的成本,因此對(duì)于適銷對(duì)路產(chǎn)品要充分權(quán)衡成本與性能之間的折衷。
總之,當(dāng)比較一個(gè)600MHz的單ALU DSP和一個(gè)300MHz但有4 ALU的DSP時(shí),設(shè)計(jì)工程師始終應(yīng)把握的最終目標(biāo)是高效的運(yùn)算吞吐量,具有多個(gè)ALU的DSP也許是最好的解決方案。
性能與功耗
頂級(jí)性能的DSP采用并行結(jié)構(gòu)來獲得最佳的性能空間。有個(gè)著名的平衡型并行結(jié)構(gòu)StarCore SC140就采用了指令級(jí)并行結(jié)構(gòu),它具有4個(gè)并行ALU以及一個(gè)稱為變長(zhǎng)執(zhí)行集(VLES)的改進(jìn)型甚長(zhǎng)指令字模型。VLES的優(yōu)點(diǎn)在于它支持在內(nèi)存中完成高效的指令調(diào)度、執(zhí)行和打包。它能通過一個(gè)指令隊(duì)列對(duì)前端提供反饋,并通過調(diào)度器控制后端,因此除非需要執(zhí)行計(jì)算,VLES處理一般不消耗功率。
在并行VLES結(jié)構(gòu)中,一些特殊指令需要成組以避免空操作(Nop),由于減少了時(shí)鐘周期,處理時(shí)間也相應(yīng)減少了。比較而言,在甚長(zhǎng)指令字計(jì)算中,所有執(zhí)行步驟都必須按順序排列,因此在一個(gè)8字節(jié)的執(zhí)行集甚至是1字節(jié)數(shù)據(jù)時(shí),系統(tǒng)就需要7個(gè)占位符(placeholder)或Nop。
由于VLES結(jié)構(gòu)不需要Nop,VLES設(shè)計(jì)中的復(fù)雜性從硬件或編程器轉(zhuǎn)移到了編譯器。由于每個(gè)周期都充滿了數(shù)據(jù),因此每個(gè)周期就具有更高的效率,從而也提高了電源與內(nèi)存的使用效率。
電源管理
由于ASR系統(tǒng)需要連續(xù)處理語音數(shù)據(jù),會(huì)使DSP成為消耗電能的主要部件,因此高效利用電源對(duì)設(shè)備成功走向市場(chǎng)至關(guān)重要。
在高性能DSP中,選擇16位指令集而非32位指令集能提高代碼密度,進(jìn)一步減少對(duì)內(nèi)存、功耗和體積的需求,一部分原因是由于更短的16位指令集可以減少寄存器和數(shù)據(jù)線數(shù)量。例如在ASR應(yīng)用中,存儲(chǔ)的詞匯量可能達(dá)到2.5MB(對(duì)于1024簇的三音素狀態(tài),5個(gè)合成和39個(gè)參數(shù)來說,聲學(xué)HMM狀態(tài)模型是400KB;一本有1萬個(gè)三態(tài)三音素代碼本是60KB;三音素狀態(tài)轉(zhuǎn)移概率矩陣是500KB;一個(gè)具有40個(gè)雜亂態(tài)2萬字的雙字母組是1.6MB)。如果DSP具有高的代碼密度,能為ASR系統(tǒng)提供固定數(shù)量的存儲(chǔ)器,那么就可以獲得更好更大的聲學(xué)和語言模型。
片上和片外存儲(chǔ)器
對(duì)于ASR系統(tǒng)中使用的DSP來說,有效地利用片上和片外存儲(chǔ)器是另外一個(gè)重要的課題。由于ASR系統(tǒng)需要大量的存儲(chǔ)空間用于詞匯與模式識(shí)別數(shù)據(jù)的存儲(chǔ),一個(gè)靈活的存儲(chǔ)結(jié)構(gòu)在這里將顯得特別重要。例如,一個(gè)具備統(tǒng)一尋址存儲(chǔ)器的DSP能使設(shè)計(jì)工程師很好地平衡程序和數(shù)據(jù),還能平衡系統(tǒng)算法的復(fù)雜性與聲學(xué)和語言模型的大小以獲得最優(yōu)化的性能。
例如,如果具有100條命令的識(shí)別系統(tǒng)模型只有100kB的片上系統(tǒng)內(nèi)存,總共內(nèi)存空間需求是240kB,那么采用二次識(shí)別方法能更有效地利用片上快速存儲(chǔ)器。
第一次(原始識(shí)別階段)只使用39個(gè)參數(shù)中的13個(gè)MFCC,因此模型大小為80kB,可以載入片上內(nèi)存。原始識(shí)別階段的候選命令數(shù)量要比原來的100個(gè)少,比方說是33個(gè)命令,但可信度高達(dá)99.9%。
第二次(精確識(shí)別階段)把33個(gè)候選命令的39個(gè)參數(shù)作為模型使用,大小是80kB,因此又可以把該模型裝載入片上內(nèi)存。這種二次識(shí)別方法會(huì)引入一些延時(shí),但延時(shí)非常小,大約只有10ms,說話人一般不會(huì)覺察到。
統(tǒng)一尋址存儲(chǔ)器能夠支持較大的詞匯庫或命令集,還能支持較大的HMM模型或神經(jīng)網(wǎng)絡(luò)系數(shù),因此能簡(jiǎn)單化實(shí)時(shí)任務(wù)。例如為ASR系統(tǒng)的程序和數(shù)據(jù)準(zhǔn)備100kB的存儲(chǔ)器,設(shè)計(jì)工程師就能平衡好算法復(fù)雜性與詞匯量或命令集大小之間的關(guān)系。如果程序要占50kB,那么數(shù)據(jù)只能是50kB。如果允許降低識(shí)別精度而將程序代碼壓縮到20kB,那么命令集就能用到80kB,也就是增加了詞匯庫容量。
在ASR系統(tǒng)中,高度并行化、高代碼密度和有效利用存儲(chǔ)器等優(yōu)點(diǎn)還能使DSP完成語音識(shí)別以外的任務(wù)。在大多數(shù)情況下,設(shè)計(jì)工程師可以將部分計(jì)算資源分配給語音識(shí)別之用,而將剩余資源用來執(zhí)行信道處理系統(tǒng)中所需的其它任務(wù)。
在選中最優(yōu)化的DSP后,要想獲得高性能的ASR用系統(tǒng)級(jí)芯片還需要增加一些功能,例如快速緩存或快速指令/數(shù)據(jù)存取以及實(shí)時(shí)操作系統(tǒng)(RTOS)才能使ASR系統(tǒng)真正完成實(shí)時(shí)性能。多任務(wù)RTOS能使系統(tǒng)同時(shí)運(yùn)行多個(gè)應(yīng)用如雙通道語音識(shí)別,因此能極大地提高系統(tǒng)性能。
復(fù)雜SoC應(yīng)用(如信道處理系統(tǒng))設(shè)計(jì)工程師能從使用高效的高級(jí)語言編譯器的DSP和SoC中獲益,因?yàn)檫@些編譯器允許設(shè)計(jì)工程師使用C或C++語言進(jìn)行編程。采用增強(qiáng)的片上仿真和調(diào)試功能還可以進(jìn)一步縮短設(shè)計(jì)時(shí)間。對(duì)于3G移動(dòng)手機(jī)應(yīng)用中各層次的元器件與系統(tǒng)設(shè)計(jì)來說,除了實(shí)時(shí)性能和簡(jiǎn)化設(shè)計(jì)流程外,功率管理控制同樣非常重要。在設(shè)計(jì)SoC時(shí),選擇具有可調(diào)功率功能的內(nèi)核將獲益非淺。例如當(dāng)移動(dòng)用戶在說話時(shí),DSP需要全速運(yùn)行(如300MHz)。當(dāng)未使用ASR功能時(shí),SoC電源管理電路可以逐步降低到較低的時(shí)鐘速度(如100MHz),從而有效地降低漏電和功耗。
由于ASR系統(tǒng)對(duì)計(jì)算速度的需求會(huì)根據(jù)識(shí)別特征的差異產(chǎn)生很大變化,例如孤字識(shí)別或連續(xù)語音識(shí)別、詞匯量和跟講者無關(guān)的語音識(shí)別等,因此,能支持ASR功能的信道處理系統(tǒng)的復(fù)雜性變化也很大。
SoC非常適合于構(gòu)造芯片的基礎(chǔ)架構(gòu),因此在以客戶/服務(wù)器系統(tǒng)為中心的設(shè)計(jì)中是非常理想的選擇,但SoC器件由于功能太強(qiáng)大,因此并不非常適合于用戶端以終端為中心的設(shè)計(jì)。然而,隨著ASR系統(tǒng)的逐漸成熟以及3G手機(jī)支持越來越復(fù)雜的應(yīng)用和復(fù)雜ASR,這類功能強(qiáng)大的SoC也能成功地運(yùn)用到用戶端。
在SoC上使用多個(gè)DSP能使系統(tǒng)在完成語音識(shí)別的同時(shí)更容易地執(zhí)行其它任務(wù)。例如三個(gè)內(nèi)核中的一個(gè)可以專門指定用來完成多信道的服務(wù)器端ASR,而其它二個(gè)內(nèi)核用于執(zhí)行像語音信道和互聯(lián)網(wǎng)數(shù)據(jù)處理這樣的任務(wù)。將來如果手機(jī)鍵盤不復(fù)存在的話,ASR將成為用戶與手機(jī)之間的唯一接口,到時(shí)這一功能將占用大部分的工作時(shí)間。
采用多個(gè)DSP內(nèi)核還能提供強(qiáng)大的計(jì)算能力,從而使執(zhí)行非常復(fù)雜的ASR任務(wù)成為可能,如電子郵件聽寫中的連續(xù)語音識(shí)別、安全交易和VXML中的“口令+講者驗(yàn)證”等。多個(gè)DSP再加上統(tǒng)一的大型片上存儲(chǔ)器可以極大地縮短跟講者無關(guān)的訓(xùn)練過程,因?yàn)樵诮y(tǒng)計(jì)型ASR中訓(xùn)練過程的計(jì)算負(fù)載比識(shí)別處理過程的負(fù)載重得多。
本文小結(jié)
盡管3G手機(jī)要想贏得市場(chǎng),人們對(duì)其功能和設(shè)計(jì)仍將拭目以待,但這些系統(tǒng)需要高性能的信號(hào)處理平臺(tái)以滿足多媒體任務(wù)需求是不容置疑的,而隨著ASR系統(tǒng)的不斷普及,3G手機(jī)肯定需要具備運(yùn)行多任務(wù)能力的多DSP SoC作為解決方案。
此內(nèi)容為AET網(wǎng)站原創(chuàng),未經(jīng)授權(quán)禁止轉(zhuǎn)載。