
摘 要: 研究了利用盲源分離" title="盲源分離">盲源分離理論解決語音識(shí)別" title="語音識(shí)別">語音識(shí)別之前的語音凈化問題。基于MSICA算法良好的性能、低復(fù)雜度和實(shí)時(shí)性,設(shè)計(jì)了以TI公司的TMS320C6416數(shù)字信號(hào)處理器為內(nèi)核的語音凈化系統(tǒng)。該系統(tǒng)可以使語音識(shí)別系統(tǒng)" title="語音識(shí)別系統(tǒng)">語音識(shí)別系統(tǒng)獲得純凈語音,從而有效提高語音識(shí)別系統(tǒng)的識(shí)別率和魯棒性。
關(guān)鍵詞: 盲源分離 DSP 語音識(shí)別 語音凈化
目前針對(duì)語音識(shí)別提出了很多算法,但是這些研究基本上都是基于較為純凈的語音環(huán)境,一旦待識(shí)別的環(huán)境中有噪聲和干擾,語音識(shí)別就會(huì)受到嚴(yán)重影響。因?yàn)榇蠖鄶?shù)語音識(shí)別的語音模板基本上是在無噪聲和無混響的“純凈”環(huán)境中采集、轉(zhuǎn)換而成。而現(xiàn)實(shí)環(huán)境中不可避免地存在干擾和噪聲,包括其他人的聲音和回聲等,這些噪聲有時(shí)很強(qiáng),使語音識(shí)別系統(tǒng)的性能大大降低甚至癱瘓。已有的信號(hào)去噪、參數(shù)去噪和抗噪識(shí)別等方法都有一定的局限。如果能實(shí)現(xiàn)噪聲和語音的自動(dòng)分離,即在識(shí)別前就獲得較為純凈的語音,可以徹底解決噪聲環(huán)境下的識(shí)別問題。近年來取得很大進(jìn)展的盲源分離為噪聲和語音的分離提供了可能。盲源分離(Blind Source Separation)的算法眾多且運(yùn)算復(fù)雜,經(jīng)比較,其中T. Nishikawa等人提出的分階段 ICA方法(MSICA[1])適合有混響的噪聲環(huán)境中的語音分離問題。經(jīng)過計(jì)算機(jī)仿真,MSICA算法分離一段7s的語音要用時(shí)10ms以上,計(jì)算機(jī)和低速的DSPs很難滿足實(shí)時(shí)要求。針對(duì)這一算法,設(shè)計(jì)了一套以TI的TMS320C6416 DSP(簡(jiǎn)稱6416)芯片為內(nèi)核的語音凈化系統(tǒng)。6416的時(shí)鐘速度高達(dá)720MHz,經(jīng)過使用MSICA算法的測(cè)試,該系統(tǒng)可以實(shí)時(shí)地對(duì)語音識(shí)別的信號(hào)進(jìn)行凈化處理,有效地提高語音識(shí)別系統(tǒng)的抗噪性和魯棒性。
1 算法描述
1.1 語音識(shí)別信號(hào)的混合模型
1.1.1 卷積混合一般模型[3]
語音信號(hào)的混合模型已從瞬時(shí)模型發(fā)展到卷積模型,相比瞬時(shí)模型而言卷積模型更接近真實(shí)環(huán)境。麥克風(fēng)所測(cè)是卷積混迭信號(hào),即源信號(hào)及其濾波與延遲的混迭信號(hào)的線性組合再加上其它噪聲,如(1)式所示。

式(1)中, sj(t), j=1, ...,N為信號(hào)源,且各源信號(hào)相互獨(dú)立;xi(t),i=1,...,N為N個(gè)觀測(cè)數(shù)據(jù)向量,其元素是各個(gè)麥克風(fēng)得到的輸入。所以觀測(cè)信號(hào)xi(t)是每個(gè)源信號(hào)sj(t)經(jīng)過延時(shí)τij,并乘以因子aij(t)(沖擊響應(yīng))后疊加,最后加上噪聲ni(t)。
1.1.2 針對(duì)語音識(shí)別的簡(jiǎn)化混合模型
一般的語音識(shí)別系統(tǒng)只有一個(gè)麥克風(fēng),根據(jù)盲源分離理論,麥克風(fēng)數(shù)應(yīng)不少于信源數(shù),所以采用主副兩個(gè)麥克風(fēng)輸入待識(shí)別語音,為簡(jiǎn)化處理假定只有主講話者聲音s1和背景噪聲s2(此背景噪聲包括經(jīng)過延遲的回聲)兩個(gè)聲源。可得如圖1的混合模型。
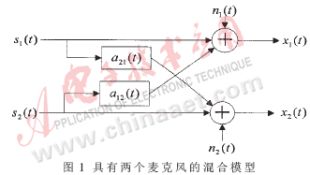
信號(hào)源s1到達(dá)兩個(gè)麥克風(fēng)的時(shí)間間隔為τ21,且幅度值不同;s2到達(dá)兩個(gè)麥克風(fēng)的時(shí)間間隔為τ12,幅度值也不同。又因?yàn)橹餍盘?hào)源s1非常靠近兩個(gè)麥克風(fēng),所以認(rèn)為τ21比τ12小很多,且趨于零。于是得到相應(yīng)的模型表達(dá)式的簡(jiǎn)化形式:
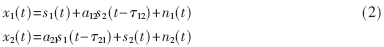
1.2 MSICA算法及其實(shí)現(xiàn)步驟
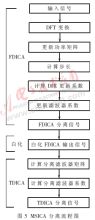
傳統(tǒng)采用頻域ICA(FDICA)或者時(shí)域ICA(TDICA)方法,單一的方法在真實(shí)環(huán)境中缺點(diǎn)很明顯,分離效果在混響環(huán)境中受到很大影響。然而一種時(shí)頻域結(jié)合多級(jí)分離的混合型ICA算法——MSICA[1] 算法可以有效解決這一問題。
該算法主要由三個(gè)步驟組成:首先,利用FDICA的高穩(wěn)態(tài)性的優(yōu)點(diǎn)在一定程度上分離源信號(hào);為了簡(jiǎn)化后續(xù)計(jì)算,白化FDICA分離出來的信號(hào);接著,把白化后的FDICA輸出信號(hào)當(dāng)作TDICA的輸入信號(hào)" title="輸入信號(hào)">輸入信號(hào),并用TDICA分離殘留的交叉干擾分量;最后,TDICA的輸出信號(hào)即為分離信號(hào)。算法框圖如圖2所示。
2 DSP硬件系統(tǒng)設(shè)計(jì)
2.1 硬件結(jié)構(gòu)
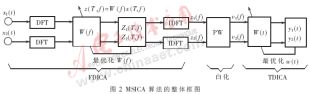
為實(shí)現(xiàn)上述算法設(shè)計(jì)了DSP語音分離系統(tǒng),該系統(tǒng)主要參數(shù)如下:
·TMS320C6416 DSP;
·16M words FLASH ROM;
·兩個(gè)EMIF: 64-Bit EMIFA 和16-Bit EMIFB;
·133MHz的16MB SDRAM;
·兩塊16-bit 立體聲CODEC:TLV320AD50。
TMS320C6416有很高的信號(hào)處理能力以及豐富的片內(nèi)存儲(chǔ)器和片內(nèi)外設(shè),且有兩級(jí)內(nèi)部存儲(chǔ)結(jié)構(gòu)。第一級(jí)L1緩存包含各為16KB的程序和數(shù)據(jù)存儲(chǔ)器,第二級(jí)L2包含1024KB的存儲(chǔ)空間。第一級(jí)只能作為緩存而第二級(jí)可以被設(shè)置為部分靜態(tài)RAM和部分緩存。在語音凈化系統(tǒng)中,設(shè)置L2為4通道256KB緩存和768KB靜態(tài)RAM。這種配置使用了最大允許的緩存,是因?yàn)镸SICA算法將處理大量的數(shù)據(jù),訪問外部存儲(chǔ)器會(huì)有瓶頸,而大緩存可以將諸如中斷服務(wù)程序、常用函數(shù)的代碼、軟件堆棧等關(guān)鍵數(shù)據(jù)段和反復(fù)使用的系數(shù)存儲(chǔ)于片內(nèi)存儲(chǔ)器中,從而大大提高內(nèi)部存儲(chǔ)空間的使用效率。6416的兩個(gè)多通道緩沖串口(McBSP)用作數(shù)據(jù)的輸入輸出端口。模擬接口芯片TLV320AD50可以提供16bit的數(shù)/模、模/數(shù)轉(zhuǎn)換,最大轉(zhuǎn)換率是22.5kHz。采樣率為8kHz,兩個(gè)TLV320AD50分別通過McBSP與TMS320C6416相連。兩路混合語音信號(hào)通過模擬接口電路轉(zhuǎn)化為數(shù)字信號(hào),兩路數(shù)字信號(hào)通過TMS320C6416的兩個(gè)McBSP輸入,根據(jù)語音特征存儲(chǔ)器中存儲(chǔ)的語音特征進(jìn)行語音分離,分離出純凈的待識(shí)別語音,進(jìn)行語音識(shí)別,最后輸出識(shí)別結(jié)果。系統(tǒng)框圖見圖3。
2.2 軟件流程
系統(tǒng)上電后,存儲(chǔ)在FLASH ROM中的程序?qū)⑤d入TMS320C6416的片內(nèi)RAM中,程序?qū)拇嫫鳌⒅袛嘞蛄勘砗途幋a進(jìn)行初始化并對(duì)片內(nèi)McBSP進(jìn)行配置,完成這些初始化的任務(wù)后系統(tǒng)采集并處理語音信號(hào)。系統(tǒng)首先對(duì)目前狀態(tài)進(jìn)行辨識(shí)。開機(jī)后的狀態(tài)分為非識(shí)別狀態(tài)和識(shí)別狀態(tài),非識(shí)別狀態(tài)下系統(tǒng)將采集純正語音信號(hào),提取出語音特征送入存儲(chǔ)器中作為模板;識(shí)別狀態(tài)下首先參考純凈語音的特征對(duì)采集的雙路混合信號(hào)進(jìn)行分離,獲得純凈的待識(shí)別語音,最后送入識(shí)別系統(tǒng)完成語音識(shí)別。整個(gè)流程見圖4。
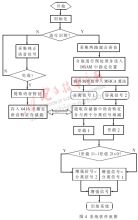
具體分離步驟在初始化之后,主函數(shù)程序進(jìn)入一個(gè)等待循環(huán),在一個(gè)新的采樣輸入被獲取之后與中斷服務(wù)程序(ISR)一起工作并調(diào)用分離程序。第一步,信號(hào)首先通過TI的DFT程序變換到頻域。系統(tǒng)使用最前面的幾個(gè)塊(例如取5塊)來估計(jì)輸入信號(hào)x1和x2每個(gè)頻率分量的功率矩陣。流程圖(見圖5)中的變量P表示正在處理的塊數(shù)。對(duì)于接下來的每一塊(P≥5),系統(tǒng)通過指數(shù)平均來更新輸入信號(hào)的功率矩陣,以計(jì)算出梯度。然后計(jì)算步長(zhǎng)u12、u21 和差分脈沖響應(yīng)濾波器ΔH12、ΔH21的更新系數(shù)。最后確定更新系數(shù)和DRIR濾波器系數(shù),在頻域?qū)斎胄盘?hào)進(jìn)行初步分離。第二步,白化程序?qū)DICA輸出信號(hào)進(jìn)行白化處理,以去除信號(hào)的相關(guān)性。第三步,首先通過最小化非負(fù)代價(jià)函數(shù)計(jì)算分離濾波器矩陣和分離濾波器系數(shù),然后帶入白化后的信號(hào)求得TDICA輸出信號(hào)。
2.3 代碼優(yōu)化
為了進(jìn)行實(shí)時(shí)的混合語音分離并識(shí)別,分離算法必須在盡可能短的時(shí)間(如1~2s)內(nèi)完成。在本系統(tǒng)中,通過CCS對(duì)C源代碼進(jìn)行編譯,并對(duì)分離算法的一些關(guān)鍵模塊從內(nèi)聯(lián)函數(shù)" title="內(nèi)聯(lián)函數(shù)">內(nèi)聯(lián)函數(shù)替換、數(shù)據(jù)讀寫、循環(huán)體優(yōu)化、函數(shù)拆并、C級(jí)優(yōu)化等方面進(jìn)行優(yōu)化設(shè)計(jì),以達(dá)到充分利用CPU、存儲(chǔ)器等資源,提高算法運(yùn)行速度,滿足實(shí)時(shí)性要求。
(1) 內(nèi)聯(lián)函數(shù)優(yōu)化
通過內(nèi)聯(lián)函數(shù)替換提高代碼性能。內(nèi)聯(lián)函數(shù)直接與匯編指令相對(duì)應(yīng),通過使用它們,C編譯器能達(dá)到更好的編譯效果,并充分利用系統(tǒng)資源。C6416提供豐富的內(nèi)聯(lián)函數(shù),涵蓋了各種數(shù)據(jù)類型的乘、加、移位等操作。實(shí)驗(yàn)結(jié)果表明,內(nèi)聯(lián)函數(shù)替換是提高代碼性能最簡(jiǎn)單、直接有效的方法。
(2) 數(shù)據(jù)讀寫優(yōu)化
充分利用C6416的雙字存取指令和packing/unpacking方式提高代碼的運(yùn)行速度。
(3) 循環(huán)體優(yōu)化
通過軟件流水工具(Software Pipeline)適當(dāng)安排循環(huán)指令,使多次迭代并行執(zhí)行,以達(dá)到優(yōu)化代碼的目的。
(4) 函數(shù)拆并優(yōu)化
將某些大函數(shù)拆開成多個(gè)小函數(shù)或相反,以提高程序的運(yùn)行速度。對(duì)FDICA和TDICA等大程序中某些常用的分支,可將其拆分以減少判斷、跳轉(zhuǎn)操作。對(duì)于某些簡(jiǎn)單的小函數(shù),將其合并成大函數(shù)有助于減少程序調(diào)用開銷。
(5) C級(jí)優(yōu)化[2]
在定點(diǎn)DSP上進(jìn)行浮點(diǎn)運(yùn)算會(huì)影響C源代碼的性能。因此,第一個(gè)優(yōu)化任務(wù)就是將源碼中運(yùn)算比較密集的部分(如分離濾波器矩陣和分離濾波器系數(shù)的計(jì)算)轉(zhuǎn)換成定點(diǎn)的算法。此外,影響系統(tǒng)性能的一個(gè)重要原因是沒有有效利用DSP的并行計(jì)算能力,TMS320C6416為最優(yōu)化這些并行操作的打包數(shù)據(jù)處理提供了特殊的指令。系統(tǒng)另一個(gè)瓶頸是對(duì)外部存儲(chǔ)器的訪問。對(duì)混合語音的分離需要處理大量的數(shù)據(jù),存儲(chǔ)和訪問可能是DSP系統(tǒng)的最大瓶頸。通過使用緩存可以緩解瓶頸,優(yōu)化在外部和內(nèi)部存儲(chǔ)器中的數(shù)據(jù)定位可以提高系統(tǒng)的性能。最后,使用C編譯器的最優(yōu)化選項(xiàng)編譯代碼。
上述的優(yōu)化并非已經(jīng)完全,在后續(xù)的研究中代碼可以進(jìn)一步優(yōu)化,如可改進(jìn)以下幾處:首先,使用DMA以提高存儲(chǔ)器訪問的性能并減少存儲(chǔ)器消耗;其次,為了避免浮點(diǎn)溢出可以將代碼全部轉(zhuǎn)換為定點(diǎn),對(duì)代碼中的關(guān)鍵循環(huán)進(jìn)行更好的組織以實(shí)現(xiàn)軟件流水線;最后,為了最大程度提高性能可以使用線性匯編語言并對(duì)部分代碼進(jìn)行匯編層的優(yōu)化。
2.4 實(shí)驗(yàn)結(jié)果
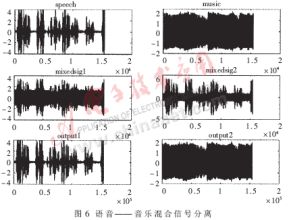
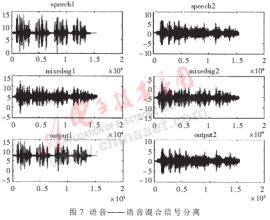
采用兩組混合語音來測(cè)試語音凈化系統(tǒng),即單獨(dú)錄制兩個(gè)純凈的信號(hào)源,圖1所示模型用MATLAB混合(忽略噪聲),通過凈化系統(tǒng)得到兩組分離信號(hào)并與原始語音進(jìn)行比對(duì)。x1(t)和x2(t)即為兩個(gè)麥克風(fēng)的輸入信號(hào)。使用以下兩組聲音信號(hào)作為測(cè)試信號(hào),第一組為語音和音樂信號(hào),第二組為兩個(gè)語音信號(hào),都是16kHz采樣16bit單聲道文件,長(zhǎng)度均為7s。圖6與圖7分別為上述兩組混合語音的分離結(jié)果,從中可以看出分離效果非常令人滿意,達(dá)到了帶噪語音的凈化效果。
在實(shí)驗(yàn)室環(huán)境引入語音凈化系統(tǒng)后,語音識(shí)別的速度雖然略有下降,但是識(shí)別語音的信噪比有顯著提高,在有不同信噪比的音樂和混響噪聲的背景中,識(shí)別率平均提高30%以上。
參考文獻(xiàn)
1 T. Nishikawa, H. Saruwatari, K.Shikano. Multistage ICA for of real acoustic convolutive mixture Proc.ICA2003,2003;(4):253~256
2 A.U.Batur,B.E.Flinchbaugh, M .H. Hayes. A dsp-based approach for the implementation of face recognition algorithms.ICASSP 2003, IEEE, 2003:253~256
3 Peiyu He, Piet.C.W.Sommen, Bin Yin. A real-time dsp blind signal separation experimental system based on new simplified mixing model. Proc of EUROCON’2001.Bratislava,Slovak Republic. 2001;(7):467~470
4 Chin.Heungsuk, J.Kim,ect. Realization of Speech Recognition using DSP(Digital Signal Processor). ISIE 2001, Pusan, KOREA,2001:508~512