
引言
近些年來,隨著集成電路制造工藝和制造技術(shù)的發(fā)展,SRAM存儲芯片在整個SoC芯片面積中所占比例越來越大,而SRAM的功耗也成為整個SoC芯片的主要部分。同時,CPU的工作頻率逐年提高,從1999年的1.2 GHz增長到2010年的3.4 GHz。而且,這一趨勢還在進(jìn)一步加強(qiáng)。CPU工作頻率的增加對SRAM的工作頻率提出很高的要求。
針對以上,提出位線循環(huán)充電(CRSRAM)SRAM結(jié)構(gòu),它主要是通過降低位線電壓的擺幅來降低功耗。采用雙模式自定時電路(DMST)則主要是根據(jù)讀寫周期的不同來產(chǎn)生不同的時序信號,從而提高讀寫速度。基于不同SRAM存儲陣列結(jié)構(gòu),雖然這種技術(shù)能有效地改善SRAM的功耗和速度,但它們卻從來沒有被有效地結(jié)合在一起。
本文的主要內(nèi)容就是設(shè)計并仿真基于位線循環(huán)充電SRAM結(jié)構(gòu)的雙模式自定時電路(DMST CRSRAM),并將其仿真結(jié)果與傳統(tǒng)結(jié)構(gòu)相比較,由此可以看出這兩種結(jié)構(gòu)在速度和功耗方面的優(yōu)勢。
1 多級位線位SRAM結(jié)構(gòu)及工作原理
如圖1所示,多級位線SRAM(HBLSA-SRAM)的主要原理是利用兩級位線和局部靈敏放大器來使主位線寫入周期中的,BL和BLB上的電壓擺幅是一個很小值,而通過局部靈敏放大器將這個電壓放大為VDD到0的大擺幅信號輸入到局部位線上。這樣,位線的電壓擺幅減少,而且VDD到O的大擺幅寫入保證了足夠的寫裕度。
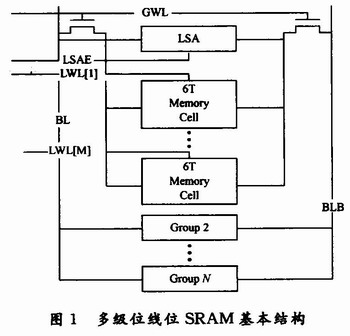
HBLSA-SRAM不僅可以降低位線的電壓擺幅,還可以有效地減小位線的電容負(fù)載。位線的負(fù)載電容很大程度上取決于位線上連接的MOS管數(shù)量。如圖1所示,在每一個Group中有M個存儲單元,而一共有N個Group,所以總共有M×N個存儲單元。對于一個傳統(tǒng)的SRAM結(jié)構(gòu)有如此的容量,那么其位線上一共會接M×N個MOS管。但對于HBLSA-SRAM來說,將連接到主位線和局部位線的MOS管加在一起也不過N+M+5個。其中,對于主位線一共連接N個MOS管,而局部位線一共連接M+5個MOS管,M為M個存儲單元的傳輸管,有1個來自與主位線連接的MOS管,另外4個來自局部的靈敏放大器。所以,不但位線擺幅顯著下降,而且位線電容負(fù)載也下降了。
HBLSA-SRAM的讀寫功耗與傳統(tǒng)的SRAM比較如下:
(1)對于寫入功耗
傳統(tǒng)的SRAM:
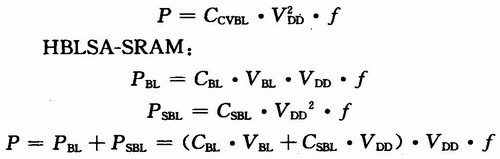
式中:PBL代表主位線上的功耗;PSBL代表局部位線上的功耗;CBL代表局部位線的電容負(fù)載;CSBL代表主位線的電容負(fù)載;CCVBL代表傳統(tǒng)結(jié)構(gòu)位線的電容負(fù)載;VBL代表局部位線的電壓擺幅。通過之前的分析,有(CBL+CSBL)
傳統(tǒng)的SRAM:
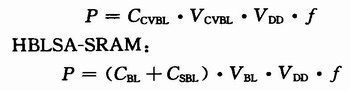
式中:VCVBL代表讀出傳統(tǒng)結(jié)構(gòu)的位線電壓擺幅。可以認(rèn)為,VCVBL和VBL近似相等,所以HBLSA-SRAM的讀出功耗也小于傳統(tǒng)的SRAM。
2 基于位線循環(huán)充電SRAM模式的自定時電路設(shè)計
將位線循環(huán)充電SRAM的結(jié)構(gòu)與雙模式自定時電路相結(jié)合,為了進(jìn)一步減小CRSRAM的功耗和優(yōu)化器讀寫延時,提出基于位線循環(huán)充電SRAM的雙模式自定時電路結(jié)構(gòu)(DMST CRSRAM)。其時序控制電路如圖2所示。
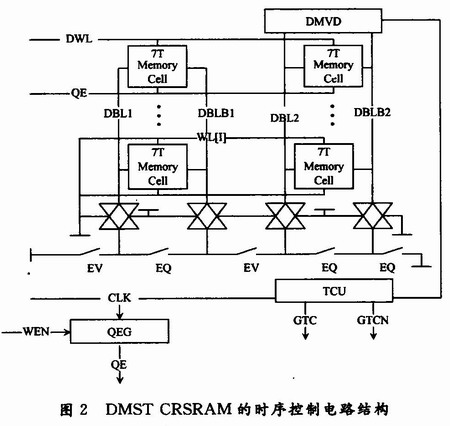
為了使CRSRAM和雙模式自定時電路更有效地結(jié)合起來,對CRSRAM的基本結(jié)構(gòu)做了三個主要的改變。
(1)傳統(tǒng)CRSRAM結(jié)構(gòu)中,位線電壓在每次讀操作之前都要被預(yù)充到VDD。這樣有兩個缺點:一是增加了額外的讀寫操作轉(zhuǎn)換的控制電路,以及將位線電壓預(yù)充到不同電壓的電路。二是預(yù)充電到VDD增加了額外的位線擺幅。如果讀寫操作交替出現(xiàn)的話,那么預(yù)充電會消耗很大的功耗。
這里設(shè)計的電路結(jié)構(gòu)中,不論讀操作還是寫操作都是以同樣的位線電壓開始的。這樣做會導(dǎo)致在讀操作中,從存儲單元到位線的充放電電流會使位線上的電壓出現(xiàn)浮動,位線上的電荷會有無法完全預(yù)計的損失或增加,由于沒有了預(yù)充電電路,位線的電荷不可完全預(yù)計的變化會對電路的讀寫能力產(chǎn)生影響。但是,由于位線的電容負(fù)載較大,而存儲管的驅(qū)動能力較小,所以讀操作對位線的電荷的影響不會使電路功能出現(xiàn)問題。
(2)為了使控制電路變得簡潔,把求值模式放在平衡模式的前面。這樣,時序控制時只要控制求值模式的時間長度,而將時鐘周期的剩余時間直接作為平衡模式的時間長度。因為,平衡模式與求值模式不同,過長的平衡模式時間不會增加額外的功耗。
(3)由于寫入時CRSRAM的位線電壓是小擺幅,所以為了確保寫入操作的正確和提高寫入的速度,用7管結(jié)構(gòu)的存儲單元代替?zhèn)鹘y(tǒng)的6管單元結(jié)構(gòu)的存儲單元。7管結(jié)構(gòu)的存儲單元的結(jié)構(gòu)如圖2所示。其工作原理:每次在讀操作中,先是QE=1,將存儲單元的存儲數(shù)據(jù)消掉,再將Q0和Q1的點位拉到同一值。這樣,小的位線電壓擺幅可以順利寫入。
如圖2所示,DMST CRSRAM的時序控制電路包括四個部分:復(fù)制陣列、雙模式電壓監(jiān)測器(DMVD)、時序控制單元(TCU)和QE信號產(chǎn)生電路(QEG)。
在復(fù)制列上,原本的Exchanger被化簡成DIN均為1時的情況,而且復(fù)制列上所有的虛擬存儲管的Q0被強(qiáng)制為0,Q1被強(qiáng)制為1。所以在求值模式中,DBL的電壓被上拉,而DBLB的電壓被下拉。那么Q0的邏輯0會提供給DBL一個下拉電流,以減緩其電壓的上升,同樣Q1的邏輯1會提供給DBLB一個上拉電流,以減緩其電壓的下降。所以,這樣就在虛擬位線上模擬了位線電壓在最慢情況下的變化過程,即可以確保真實位線上的電壓在DMVD觸發(fā)前就已經(jīng)達(dá)到了操作所需的電壓值。
DMVD由兩個參考電壓不同的比較器以及由讀寫使能信號WEN控制的兩個傳輸管組成。靈敏放大器用來監(jiān)測DBL和DBLB上的電壓差,一旦達(dá)到了預(yù)定的參考電壓值便被觸發(fā),而WEN控制的傳輸管負(fù)載分別在讀周期和寫周期,使其對應(yīng)的靈敏放大器被觸發(fā)后,其輸出作為信號P輸入到時序控制單元TCU。
TCU本質(zhì)是一個異步電平觸發(fā)電路,其工作情況如下:當(dāng)CLK上升沿到來后,GTC也隨之上升;而當(dāng)P信號上升沿到來,GTC信號則回落到低電平。GTCN為GTC的反向信號。QE信號產(chǎn)生電路(QEG),當(dāng)只有CLK上升沿時,由于延時單元的作用,QEN信號為高電平,脈寬為延時時間。而WEN控制QEN信號只有在WEN=1時(寫周期)才輸出QE信號。接下來,可以利用GTC和GTCN去控制整個電路。其中,A[i]代表行譯碼;A[j]代表列譯碼。在寫周期之中,CLK上升輸入到TCU之中,GTC變?yōu)楦唠娖剑瑫rGTCN變?yōu)榈碗娖剑浑S后EQ變?yōu)榈碗娖剑胶饽J浇Y(jié)束。對于列選中的位線,EV和WL變?yōu)楦唠娖剑M(jìn)入求值模式。寫周期EV信號也作用在虛擬位線上,使其產(chǎn)生電壓差,當(dāng)虛擬位線上的電壓差到達(dá)足以寫入數(shù)據(jù)時,DMVD被觸發(fā)產(chǎn)生P信號,P信號輸入到TCU之中,使GTC再次變?yōu)榈碗娖剑珿TCN變回高電平;隨即,EV和WL變?yōu)榈碗娖剑珽Q變回高電平,電路從求值模式轉(zhuǎn)變?yōu)槠胶饽J健T谄胶饽J街校械奈痪€包括虛擬位線的電壓都被充放電回到初始值。這次寫操作結(jié)束,電路對下一次的操作做好準(zhǔn)備。
在讀操作中,這個過程是類似的。CLK上升輸入到TCU之中,GTC變?yōu)楦唠娖剑瑫rGTCN變?yōu)榈碗娖剑浑S后EQ變?yōu)榈碗娖剑胶饽J浇Y(jié)束。不同的是,讀周期中,EV信號一直為低電平,所以只有WL上升到高電平,才進(jìn)入求值模式。此時,DWL信號也上升到高電平,使虛擬存儲單元下拉DBL上的電壓,當(dāng)DBL上的電壓足夠低時,DMVD被觸發(fā)產(chǎn)生P信號,信號輸入到TCU中,使GTC再次變?yōu)榈碗娖剑珿TCN變回高電平;隨后,D-WL和WL變?yōu)榈碗娖剑珽Q變回高電平,電路從求值模式轉(zhuǎn)變?yōu)槠胶饽J健T谄胶饽J街校械奈痪€包括虛擬位線的電壓都被充放電回到初始值。這次讀操作結(jié)束,電路對下一次的操作做好準(zhǔn)備。
3 結(jié)語
雙模式自定時技術(shù)分別針對讀寫周期產(chǎn)生不同的時序信號,并借此來改善SRAM的時鐘周期和功耗。雙模式自定時技術(shù)考慮了位線上的寄生電容和電阻,存儲單元不同的寫入響應(yīng)時間,以及依賴于存儲數(shù)據(jù)的位線的漏電流。仿真結(jié)果說明,這種雙模式自定時技術(shù)使時鐘周期降低了16%~30.7%,寫入功耗降低了15%~22.7%。