
摘 要: 針對傳統(tǒng)模型參數(shù)辨識方法和遺傳算法用于模型參數(shù)辨識時的缺點(diǎn),提出了一種基于微粒群優(yōu)化(PSO)算法的模型參數(shù)辨識方法,利用PSO算法強(qiáng)大的優(yōu)化能力,通過對算法的改進(jìn),將過程模型的每個參數(shù)作為微粒群體中的一個微粒,利用微粒群體在參數(shù)空間進(jìn)行高效并行的搜索來獲得過程模型的最佳參數(shù)值,可有效提高參數(shù)辨識的精度和效率。
關(guān)鍵詞: 微粒群算法;非線性系統(tǒng);參數(shù)辨識
非線性模型參數(shù)估計(jì)是控制領(lǐng)域研究的重要問題。目前已有許多成熟的系統(tǒng)辨識和參數(shù)估計(jì)方法,如最小二乘法[1]、極大似然估計(jì)法[2]、神經(jīng)網(wǎng)絡(luò)用于參數(shù)辨識法[3]、遺傳算法[4-5]等。但是最小二乘法和極大似然估計(jì)法都是基于過程梯度信息的辨識方法,其前提是可微的代價函數(shù)、性能指標(biāo)和平滑的搜索空間。但在實(shí)際應(yīng)用中,由于獲得的數(shù)據(jù)含有噪聲或所辨識的系統(tǒng)非連續(xù),使得這一條件難以滿足;利用神經(jīng)網(wǎng)絡(luò)進(jìn)行系統(tǒng)參數(shù)辨識雖然具有以任意精度逼近非線性函數(shù)的能力,但是在實(shí)際應(yīng)用中,只有選擇了合適的網(wǎng)絡(luò)結(jié)構(gòu),才能獲得好的結(jié)果,但選擇合適的網(wǎng)絡(luò)結(jié)構(gòu)往往是非常困難的;利用遺傳算法特有的復(fù)制、交叉和變異功能以及群體尋優(yōu)的方式來克服陷入局部最優(yōu)解,可獲得較好的模型參數(shù)估計(jì),但是遺傳算法需涉及到繁瑣的編碼、解碼過程以及較大的計(jì)算量,而且整個種群是比較均勻地向最優(yōu)解區(qū)域移動,因此其搜索效率不高。
由Kennedy等人提出的微粒群(PSO)算法[6-13]是一種有效的隨機(jī)全局優(yōu)化技術(shù),已經(jīng)被證明是一種很好的優(yōu)化方法。PSO算法對優(yōu)化目標(biāo)函數(shù)形式?jīng)]有特殊要求,而且沒有遺傳算法中的交叉、變異算子,各個算子根據(jù)自己的速度來搜索,整個搜索過程跟隨當(dāng)前最優(yōu)解進(jìn)行。目前已在許多函數(shù)優(yōu)化、網(wǎng)絡(luò)訓(xùn)練、參數(shù)整定等領(lǐng)域中得到了廣泛應(yīng)用。本文借助PSO算法的群體尋優(yōu)能力,通過對算法的改進(jìn),將其應(yīng)用到對非線性系統(tǒng)模型參數(shù)辨識中。

參數(shù)辨識就是在模型結(jié)構(gòu)已確定的情況下, 根據(jù)已知的觀測數(shù)據(jù)對(xi,yi),i=1,2,…,n求解偏差平方

此外,微粒的速度vi被一個最大速度所限制。如果當(dāng)前對微粒的加速導(dǎo)致它在某維的速度vij超過該維的最大速度vmax,j,則該維的速度被限制為最大速度vmax,j,使得粒子不至于因?yàn)轱w行速度過高而跳過可能的優(yōu)化解。
2.2 PSO算法的改進(jìn)
通過對式(3)、式(4)分析發(fā)現(xiàn),如果粒子群的歷史最優(yōu)粒子位置Pgest在較長時間內(nèi)沒有發(fā)生變化,在粒子群體快接近Pgest時,其速度更新將由歷史速度決定,于是速度將越來越小,粒子群呈現(xiàn)出強(qiáng)烈的“趨同性”,表現(xiàn)在式(3)中的第2項(xiàng)和第3項(xiàng)接近于0。這種“趨同性”加快了算法的搜索速度,但是卻減弱了群體開拓新的搜索空間的能力。如果該最優(yōu)位置為一局部最優(yōu)點(diǎn),則算法很容易陷入局部最優(yōu),發(fā)生早熟現(xiàn)象。通過粒子群優(yōu)化算法的搜索機(jī)理分析發(fā)現(xiàn),無論是早熟收斂還是全局收斂,微粒群中的粒子都會出現(xiàn)“聚集”現(xiàn)象。針對這個問題,本文對PSO算法作了以下改進(jìn):在微粒群從第t代向第t+1代“飛翔”時,粒子除追隨個體極值Pbest和全局極值Pgest外,還追隨從微粒群中隨機(jī)選取的某個粒子個體極值Pn,則式(3)改寫為:

2.3 算法設(shè)計(jì)
采用改進(jìn)PSO算法進(jìn)行非線性系統(tǒng)模型參數(shù)辨識研究,設(shè)計(jì)出的實(shí)現(xiàn)算法為:
(1)根據(jù)優(yōu)化命題的復(fù)雜性,確定群體規(guī)模m和搜索空間維數(shù)D,并初始化群體的速度和位置;
(2)根據(jù)式(5),計(jì)算每一個微粒新的速度和位置;
(3)根據(jù)優(yōu)化目標(biāo)確定算法的適應(yīng)度函數(shù),適應(yīng)度函數(shù)可以根據(jù)具體的情況來確定;
(4)對每個微粒,將其適應(yīng)值與其經(jīng)歷過的最好位置Pg作比較。如果較好,則將其作為當(dāng)前的最好位置Pg,否則繼續(xù)執(zhí)行下一步;
(5)對每個微粒,將其適應(yīng)值與全局所經(jīng)歷的最好位置Pg作比較。如果較好,則將其作為當(dāng)前全局的最好位置Pg,否則繼續(xù)執(zhí)行下一步;
(6)判斷算法是否滿足終止條件。若達(dá)到終止條件,則算法停止,返回當(dāng)前最優(yōu)個體為結(jié)果,否則,返回第二步繼續(xù)。
3 仿真研究
為了驗(yàn)證利用改進(jìn)PSO算法進(jìn)行非線性模型參數(shù)估計(jì)的有效性,本文以谷氨酸菌體生長模型[5]參數(shù)優(yōu)化估計(jì)為例進(jìn)行了仿真研究。
菌體種子接入發(fā)酵罐以后,就在罐內(nèi)按自然規(guī)律生長繁殖,在整個發(fā)酵期間,若無雜菌和噬菌體的侵襲, 罐內(nèi)外沒有大規(guī)模菌體遷移。菌體在發(fā)酵罐內(nèi)的自然生長繁殖過程可以用Verhulst方程來描述[5]:

對上述的微分方程進(jìn)行求解可得:
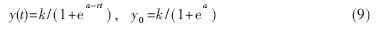
式(8)即可作為菌體在發(fā)酵罐內(nèi)的生長模型。其中y(t)為菌體濃度,t為菌體生長時間,r、a、k為待定模型參數(shù)。
利用改進(jìn)的PSO算法進(jìn)行模型參數(shù)估計(jì)的目的是要確定菌體生長模型中的模型參數(shù)r、a、k使得實(shí)際觀測值與模型估計(jì)值有較高的擬合度。本文利用參考文獻(xiàn)[5]中提供的實(shí)際觀測數(shù)據(jù),通過改進(jìn)的PSO算法對模型參數(shù)進(jìn)行估計(jì),見表1。
改進(jìn)的PSO算法適應(yīng)值函數(shù)采用如下偏差平方和形式:

根據(jù)表1中的觀測數(shù)據(jù),利用PSO算法進(jìn)行參數(shù)估計(jì),并與人工神經(jīng)網(wǎng)絡(luò)(ANN)、標(biāo)準(zhǔn)遺傳算法(SGA)、改進(jìn)遺傳算法(IGA)、標(biāo)準(zhǔn)PSO算法4種方法進(jìn)行了比較。表2給出了模型參數(shù)估計(jì)結(jié)果。
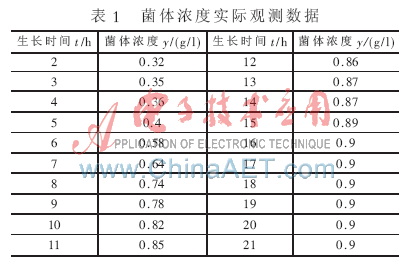

為了驗(yàn)證本文方法的有效性,將表2中的5種算法得到的估計(jì)值分別作為模型參數(shù),并以表1中的實(shí)際觀測數(shù)據(jù)作為檢驗(yàn)樣本,進(jìn)行模型擬合度的比較。表3是谷氨酸菌體濃度實(shí)際觀測值與模型擬合值,采用剩余標(biāo)準(zhǔn)差式(11)作為評價指標(biāo),表4是5種算法分別對應(yīng)的剩余標(biāo)準(zhǔn)差值。
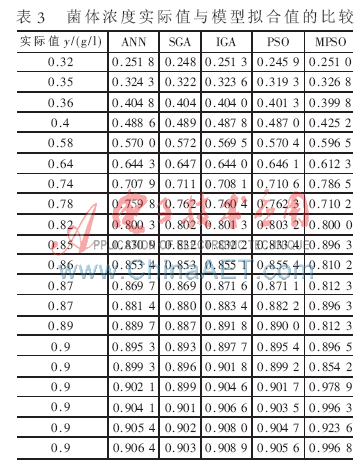
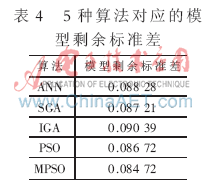

從模型擬合值和模型剩余標(biāo)準(zhǔn)差的比較結(jié)果可以看出,基于MPSO算法的模型參數(shù)估計(jì)精度略高于ANN、SGA、IGA、PSO算法,而采用ANN、SGA、IGA 3種算法也可得到較好的擬合效果。但從5種算法的實(shí)施過程來看,MPSO算法簡單,需要調(diào)整的參數(shù)較少,易于編程實(shí)現(xiàn)、計(jì)算量小,適于在線辨識。可見將MPSO算法用于非線性模型參數(shù)估計(jì)是有效、可行的。
本文研究了用改進(jìn)的PSO算法解決非線性模型參數(shù)估辨識問題,并以實(shí)例進(jìn)行了驗(yàn)證。實(shí)驗(yàn)結(jié)果證明了基于改進(jìn)的PSO算法的非線性模型參數(shù)估計(jì)是有效、可行的。從而為非線性模型參數(shù)估計(jì)問題提供了一種新途徑。
參考文獻(xiàn)
[1] 仇振安,何漢輝.基于廣義最小二乘法的系統(tǒng)模型辨識及應(yīng)用[J].計(jì)算機(jī)仿真,2007,24(10):89-91.
[2] 馬世橈,盧建偉.極大似然估計(jì)法在高壓斷路器可靠性分析中的應(yīng)用[J].沈陽工業(yè)大學(xué)學(xué)報,2007,29(1):41-43.
[3] 董澤,黃宇,韓璞.量子遺傳算法優(yōu)化RBF神經(jīng)網(wǎng)絡(luò)及其在熱工辯識中的應(yīng)用[J].中國電機(jī)工程學(xué)報,2008,28(17):99-104.
[4] 夏秀渝,周激流.一種混合遺傳算法及其在線性系統(tǒng)辯識中的應(yīng)用[J].四川大學(xué)學(xué)報,2005,37(1):104-107.
[5] 蔡煜東,陳常慶.用遺傳算法辨識發(fā)酵動力學(xué)模型參數(shù)[J].化工學(xué)報,1995,46(3):338-342.
[6] ZHONG Wei min, LI Shao Jun, QIAN Feng. ?茲-PSO: a new strategy of particle swarm optimizition[J]. Journal of Zhejiang University SCIENCE A, 2008,9(16):786-790.
[7] 李煒,石連生,梁成龍.基于PSO-LSSVM的研究法辛烷值預(yù)測建模[J].化工自動化及儀表,2008,35(2):25-27.
[8] CUI Guang-Zhao, QIN Li-Min, LIU Sha. Modified PSO algorithm for solving planar graph coloring problem[J]. Progress in Natural Science, 2008,18(3):353-357.
[9] 成偉明,唐振民,趙春霞,等.基于神經(jīng)網(wǎng)絡(luò)和PSO的機(jī)器人路經(jīng)研究[J].系統(tǒng)防真學(xué)報,2008,20(3):608-611.
[10] 劉曉峰,陳通.PSO算法的收斂性及參數(shù)選擇研究[J].計(jì)算機(jī)工程與應(yīng)用,2007:43(9):14-17.
[11] YUHUI S, EBERHART R. Proceedings of the 7th annual conference on evolutionary programming[C]. Washington: IEEE Press, 1998.
[12] YUHUI S, EBERHART R. Proceedings of the congress on evolutionary computation[C], Washington: IEEE Press, 1998.
[13] XIE Xiao Feng, ZHANG Wen Jun, YANG Zhi Lian. Overview of particle swarm optimization[J]. Control and Decision, Shenyang, 2003,18(2):129-134.
[14] MILLONAS M M. Swarms phase transition and collective intelligence[M]. MA: Addison Wesley, 2004.