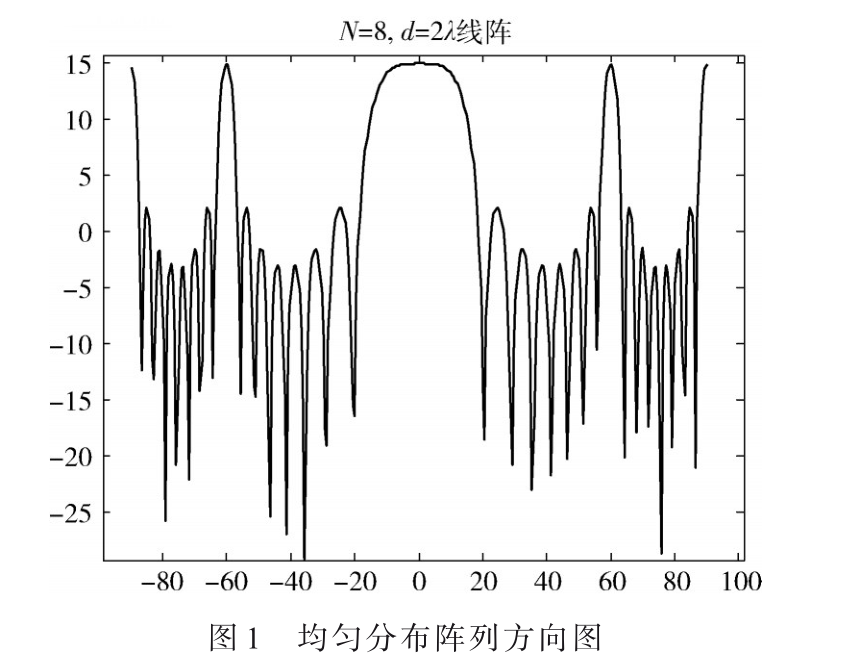
粒子群優(yōu)化算法在無人分布式陣面的應用[通信與網(wǎng)絡][航空航天]
發(fā)表于:9/14/2024 3:07:22 PM
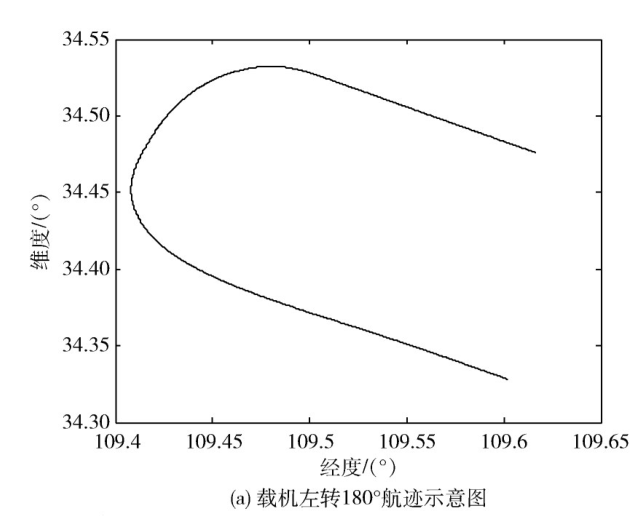
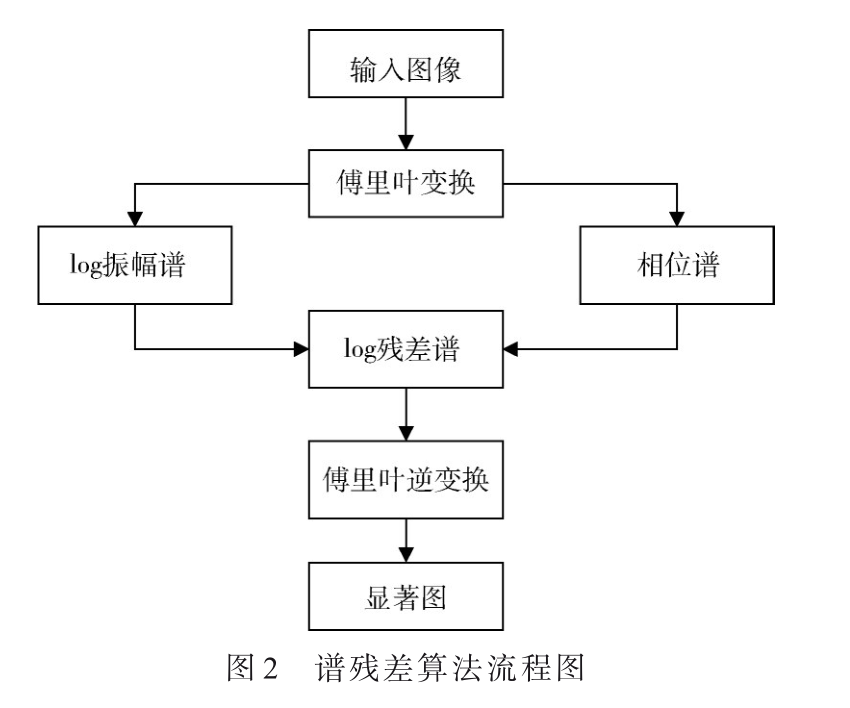
基于多尺度顯著性檢測的SAR圖像海岸線檢測[通信與網(wǎng)絡][通信網(wǎng)絡]
發(fā)表于:9/14/2024 2:35:03 PM
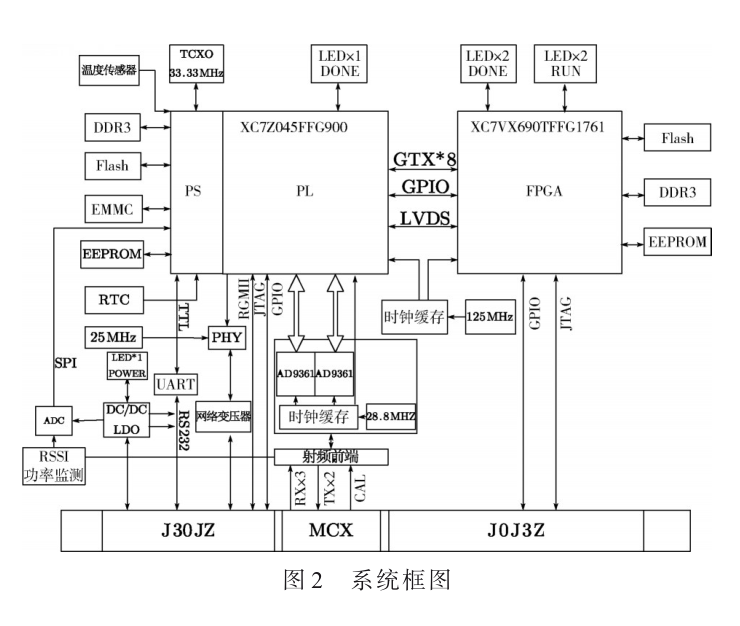
一種用于DOA估計的高精度同步多天線系統(tǒng)設計[通信與網(wǎng)絡][通信網(wǎng)絡]
發(fā)表于:9/14/2024 2:19:00 PM
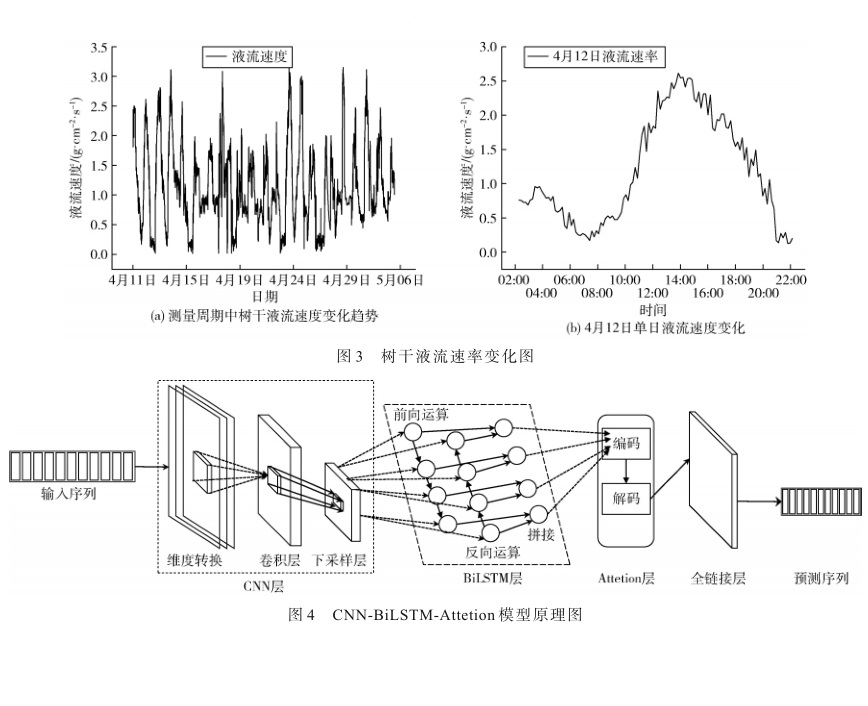
基于CNN-BiLSTM-Attetion的銀杏液流預測模型及環(huán)境因子影響研究[模擬設計][其他]
發(fā)表于:9/14/2024 2:05:21 PM
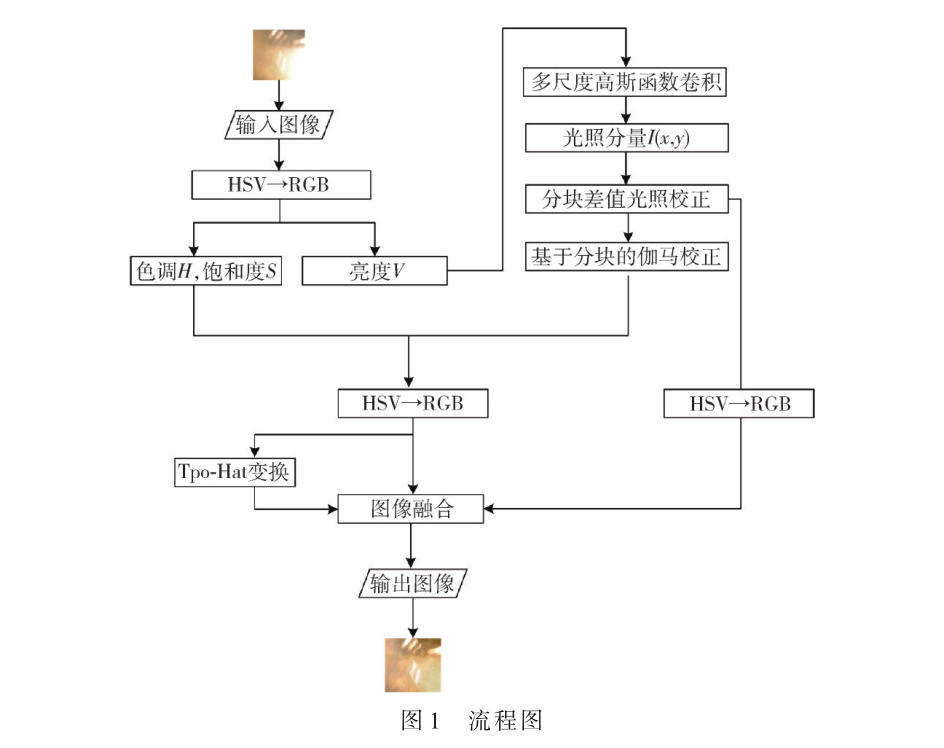
非均勻光照下銅板表面缺陷圖像增強[EDA與制造][工業(yè)自動化]
發(fā)表于:9/14/2024 1:50:20 PM
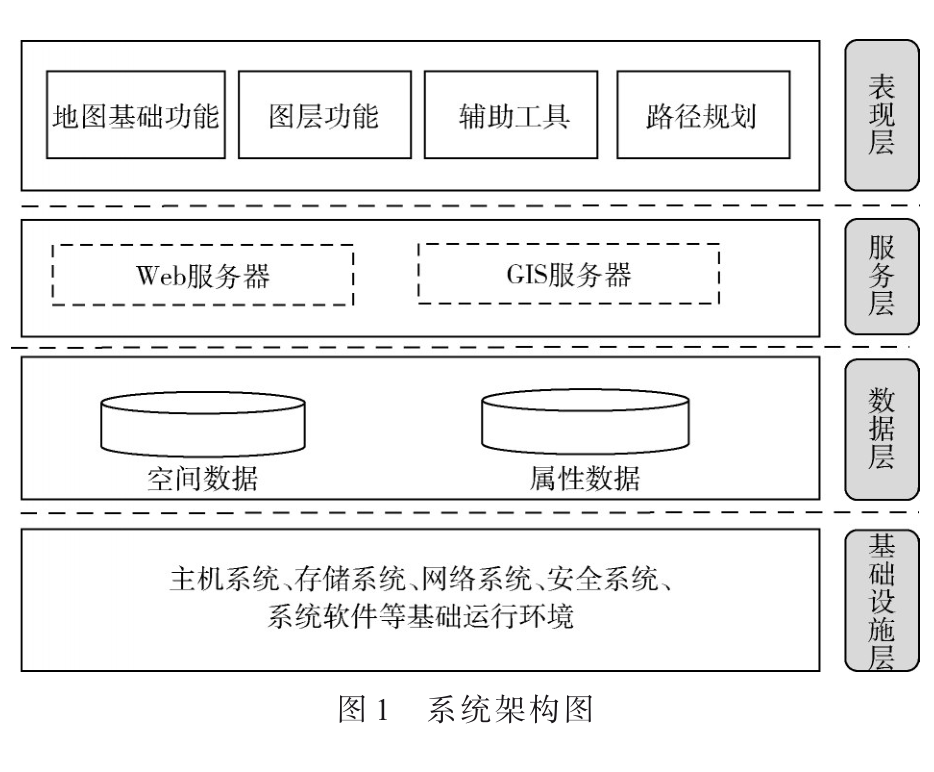
無人機城市三維航跡規(guī)劃可視化平臺設計與實現(xiàn)[模擬設計][航空航天]
發(fā)表于:9/14/2024 1:37:20 PM
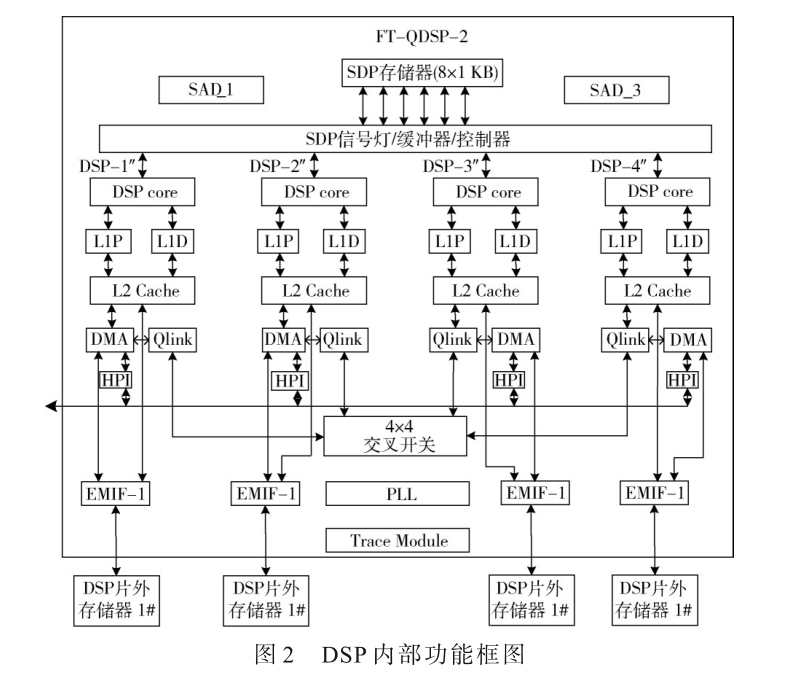
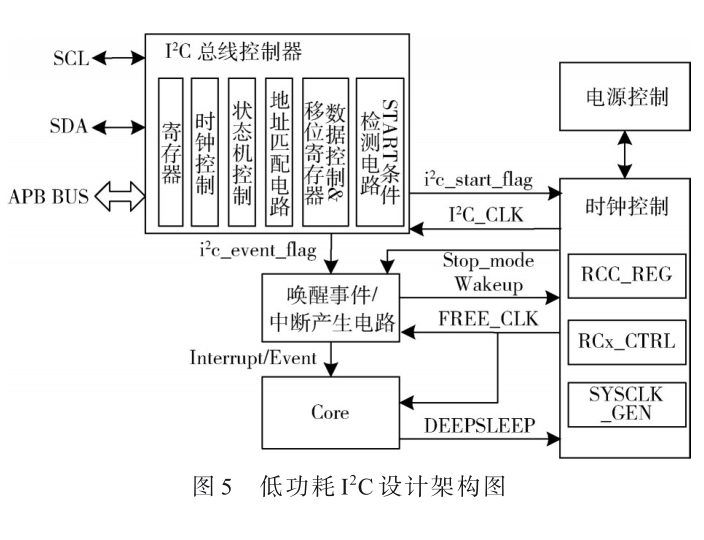
基于MCU的低功耗I2C總線控制器設計與實現(xiàn)[模擬設計][通信網(wǎng)絡]
發(fā)表于:9/14/2024 1:14:05 PM
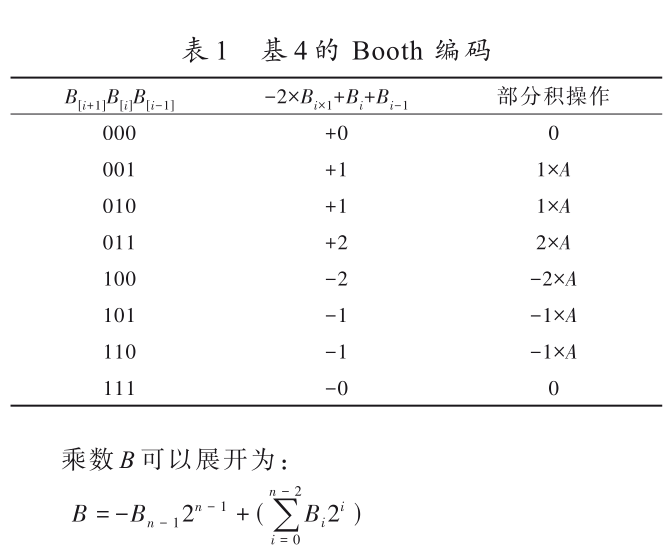
基于加法樹壓縮和乘數(shù)編碼優(yōu)化的乘法器設計[模擬設計][通信網(wǎng)絡]
發(fā)表于:9/14/2024 1:02:56 PM