
摘 要: 介紹一種在語音識別系統(tǒng)中運(yùn)用FPGA技術(shù)對語音信號進(jìn)行前期實(shí)時(shí)處理的方法。利用DSP Builder設(shè)計(jì)信號處理算法的圖形化電路模塊,運(yùn)用硬件環(huán)(HIL Hardware in the Loop)技術(shù)對模塊進(jìn)行軟硬件協(xié)同仿真。滿足設(shè)計(jì)要求后,再用Signal Compiler 將模塊轉(zhuǎn)換成VHDL語言和Quartus II工程文件下載至目標(biāo)芯片。結(jié)果表明此方法可以快速靈活地設(shè)計(jì)出語音處理模塊,語音數(shù)據(jù)能在要求的時(shí)間范圍內(nèi)處理完畢,達(dá)到了實(shí)時(shí)處理的目的。
關(guān)鍵詞: 語音識別; FPGA; 實(shí)時(shí); 信號處理
隨著語音識別技術(shù)的應(yīng)用越來越廣,對其實(shí)時(shí)性的要求也越來越高。專用的DSP語音芯片雖然有硬件加速功能,但其指令依然是串行計(jì)算,在實(shí)時(shí)性方面有所欠缺。如今,具有并行運(yùn)算能力的FPGA主頻不斷提高,加上其設(shè)計(jì)靈活、功耗低、體積小等優(yōu)點(diǎn)[1],可以滿足語音信號實(shí)時(shí)處理的要求。目前很多語音處理算法都是基于軟件平臺的,真正的語音處理硬件實(shí)現(xiàn)很少。本文針對非特定人的語音信號,研究當(dāng)前主流的語音處理算法,并將這些基于軟件平臺的算法“硬件化”。在保證一定精度的前提下將浮點(diǎn)運(yùn)算轉(zhuǎn)換成便于FPGA實(shí)現(xiàn)的定點(diǎn)運(yùn)算[2]。
本文以通過對語音信號濾波、分幀、加窗、能量計(jì)算等模塊的設(shè)計(jì)為例,介紹語音信號實(shí)時(shí)處理的方法,需要運(yùn)用到MATLAB.、DSP Builder、QUARTUS II、ModelSim等EDA工具聯(lián)合設(shè)計(jì)[3]。語音信號經(jīng)過模數(shù)轉(zhuǎn)換進(jìn)入FPGA以后,對其濾波,因?yàn)橐獙π盘栠M(jìn)行實(shí)時(shí)處理,需要采用動態(tài)分幀,最后計(jì)算出每幀的能量為語音信號的下一步處理如端點(diǎn)檢測、特征提取[4]等做好前期準(zhǔn)備。
1 實(shí)時(shí)處理算法分析
語音數(shù)據(jù)經(jīng)過A/D轉(zhuǎn)換之后進(jìn)入芯片,首先對其進(jìn)行濾波。為了使信號的頻譜趨向平坦,需要對其進(jìn)行預(yù)加重濾波,這里采用一階FIR濾波器[5]:

語音信號雖然是一種非平穩(wěn)信號,但在短時(shí)內(nèi)(10 ms~30 ms)可以看作是平穩(wěn)的[2],這樣就可以對其進(jìn)行分幀處理。在實(shí)時(shí)系統(tǒng)中無法確定語音的長度和大小,只能對其進(jìn)行動態(tài)分幀。考慮到幀的連續(xù)性,采用交疊分幀,幀移取0.5,硬件中可以用兩個(gè)FIFO實(shí)現(xiàn),其中FIFO1的讀時(shí)鐘頻率是寫時(shí)鐘的兩倍,且FIFO2的讀寫時(shí)鐘頻率與FIFO1讀時(shí)鐘頻率相同。
分幀后的數(shù)據(jù)需要窗函數(shù)對其加權(quán),加窗后的語音信號為sω(n)=s(n)×ω(n)。由于漢明窗在語音頻段的平滑特性,因此本文采取漢明窗[4]:

2 硬件模塊的實(shí)現(xiàn)
仿真時(shí)通過讀取hex文件來模擬實(shí)時(shí)的數(shù)據(jù)流。通過MATLAB將采樣頻率16 kHz,寬度8 bit的wav格式音頻文件轉(zhuǎn)化成hex文件的數(shù)據(jù)。部分代碼如下[6]:
……
[y,fs,n]=wavread(‘speech.wav’);
y1=int8(y×(2^n-1)+128);
[a,b]=size(y1);
fid=fopen(‘speech.txt’,’wt’);
for i=1:a;
line=[num2str(i-1),’:’,num2str(y1(i)),’;’];
fprintf(fid,’%s\n’,line);
end
fclose(fid);
……
在模塊中通過地址計(jì)數(shù)器將ROM中的數(shù)據(jù)不斷讀出,然后對數(shù)據(jù)流進(jìn)行濾波。其DSP Builder模塊實(shí)現(xiàn)如圖1所示。
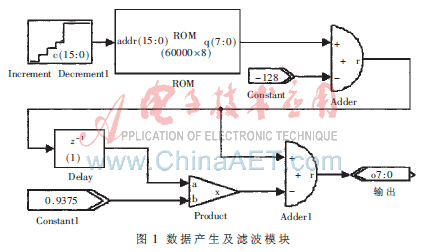
考慮到語音信號的短時(shí)平穩(wěn)性,將256點(diǎn)數(shù)據(jù)分為一幀寫入Dual-Clock FIFO,寫入128點(diǎn)后以兩倍的寫入速度讀出,同時(shí)以兩倍速度寫入深度為128的FIFO2。如此循環(huán)便可以實(shí)現(xiàn)幀的交疊。具體實(shí)現(xiàn)如圖2所示,左半部分為時(shí)鐘控制模塊。
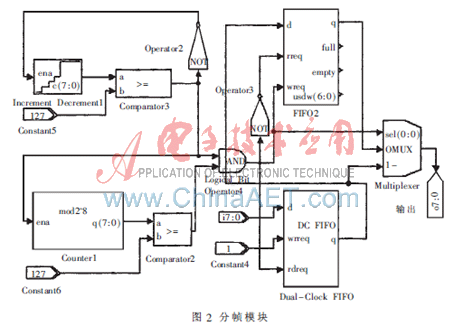
為了使每幀的數(shù)據(jù)點(diǎn)與窗函數(shù)的數(shù)據(jù)點(diǎn)一一對應(yīng),在加窗之前搭建了一個(gè)時(shí)序控制模塊。Constant1控制模塊延時(shí)384個(gè)時(shí)鐘周期,counter是模為256的計(jì)數(shù)器。將LUT設(shè)為17 964-15 073×cos([0:2×pi/255:2×pi])[6]。分幀后的信號取模然后與窗函數(shù)相乘再累加便得到其能量,由Multiply Accumulate模塊實(shí)現(xiàn)[2]。Clock提供基礎(chǔ)時(shí)鐘,PLL產(chǎn)生模塊所需要的兩個(gè)時(shí)鐘,Signal Compiler對模塊進(jìn)行編譯,轉(zhuǎn)化成VHDL語言。具體模塊如圖3所示。

3仿真測試
將上述三個(gè)子模塊和Simulink中的模擬示波器Scope連接在一起,讀取ROM中語音”1、2、3”的數(shù)據(jù)流。結(jié)果顯示在示波器上,如圖4所示。從上到下依次為原始信號、濾波信號、分幀信號、能量信號。

從圖中可以看到設(shè)計(jì)模塊已經(jīng)可以實(shí)時(shí)處理數(shù)據(jù),達(dá)到了設(shè)計(jì)要求。接下來便可以將其轉(zhuǎn)換成VHDL語言在QUARTUS II中進(jìn)行仿真,生成pof文件下載到FPGA里面。打開Signal Compiler,F(xiàn)amily選擇Cyclone II,Device選擇ALTERA公司的EP2C5T144C6芯片。點(diǎn)擊compile,便可以生成工程文件、VHDL代碼及配置文件[1]。
以上屬于軟件仿真,具有速度慢、內(nèi)容不易控制等缺點(diǎn)。ALTERA的DSP Builder提供的HIL模塊可以在Simulink模型與FPGA開發(fā)板之間通過JTAG通信口建立聯(lián)系,從而實(shí)現(xiàn)基于MATLAB/DSP Builder平臺的硬件仿真。打開HIL模塊,設(shè)置好工程文件speech.pof路徑,連接上FPGA開發(fā)板,點(diǎn)擊Configure FPGA便可以進(jìn)行硬件仿真。打開示波器查看仿真結(jié)果與軟件仿真結(jié)果吻合。在QUARTUS II中對生成的工程文件進(jìn)行編譯。整個(gè)系統(tǒng)使用了306個(gè)LE、214個(gè)寄存器、62個(gè)管腳,非常節(jié)省資源。
通過DSP Builder進(jìn)行FPGA設(shè)計(jì)無論是建模還是仿真都非常方便快捷,并可以在外部硬件測試平臺不夠完善的條件下引入HIL模塊進(jìn)行軟硬件聯(lián)合仿真。相對于傳統(tǒng)開發(fā)方式,具有更大的優(yōu)勢。在時(shí)序仿真時(shí)可以看出從語音輸入到能量的輸出占用640個(gè)周期,在100 MHz的工作頻率下僅耗時(shí)6.4 μs,是在MATLAB下運(yùn)行速度的50多倍,實(shí)時(shí)性得到了充分的體現(xiàn)。
參考文獻(xiàn)
[1] 潘松,黃繼業(yè).EDA技術(shù)與VHDL(第2版)[M].北京:清華大學(xué)出版社,2007:12-19.
[2] 劉軍海,基于DHMM非特定人孤立詞語音識別及硬件設(shè)計(jì)研究[D].上海:上海大學(xué),2007:35-37.
[3] 潘松,黃繼業(yè),王國棟.現(xiàn)代DSP技術(shù)[M].西安:西安電子科技大學(xué)出版社,2003:237-242.
[4] 王炳錫,屈丹,彭煊.實(shí)用語音識別基礎(chǔ)[M].北京:國防工業(yè)出版社,2005:56-59.
[5] 劉靜萍,姜占財(cái),德熙嘉措.語音信號的預(yù)處理技術(shù)探討[J].甘肅聯(lián)合大學(xué)學(xué)報(bào)(自然科學(xué)版),2006,20(5):61-64.
[6] 謝秋云.基于FPGA的語音識別技術(shù)研究[D].南京:江蘇大學(xué),2007:42-48.