
摘 要: 提出了一個自適應(yīng)量子粒子群優(yōu)化算法,用于訓(xùn)練RBF網(wǎng)絡(luò)的基函數(shù)中心和寬度,并結(jié)合最小二乘法計算網(wǎng)絡(luò)權(quán)值,對RBF網(wǎng)絡(luò)的泛化能力進(jìn)行改進(jìn)并用于特征選擇。實驗結(jié)果表明,采用自適應(yīng)量子粒子群優(yōu)化算法獲得的RBF網(wǎng)絡(luò)模型不但具有很強(qiáng)的泛化能力,而且具有良好的穩(wěn)定性,能夠選擇出較優(yōu)秀的特征子集。
??? 關(guān)鍵詞: 特征選擇;文本分類;RBF神經(jīng)網(wǎng)絡(luò);量子粒子群優(yōu)化;最小二乘法
?
在文本分類中,文本通常是以向量形式來表示的,其特點是高維性和稀疏性[1]。而在中文文本分類中,通常采用詞條作為最小的獨立語義載體,原始的特征空間可能由出現(xiàn)在文章中的全部詞條構(gòu)成。由于中文的詞條總數(shù)有20多萬條,這使得其高維性和稀疏性更加明顯,這樣就大大限制了分類算法的選擇空間,降低了分類算法的效率和精度。為此,尋找一種高效的特征選擇方法,以降低特征空間維數(shù)、避免維數(shù)災(zāi)難,提高文本分類的效率和精度,成為文本自動分類中亟待解決的重要問題[2-4]。
本文首先提出了一個自適應(yīng)量子粒子群優(yōu)化算法,用于訓(xùn)練RBF網(wǎng)絡(luò)的基函數(shù)中心和寬度,并結(jié)合最小二乘法計算網(wǎng)絡(luò)權(quán)值,對RBF網(wǎng)絡(luò)的泛化能力進(jìn)行改進(jìn)。然后把該RBF神經(jīng)網(wǎng)絡(luò)用于特征選擇。實驗結(jié)果表明,采用自適應(yīng)量子粒子群優(yōu)化算法獲得的RBF網(wǎng)絡(luò)模型不但具有很強(qiáng)的泛化能力,而且具有良好的穩(wěn)定性,能夠選擇出較優(yōu)秀的特征子集。
1 RBF神經(jīng)網(wǎng)絡(luò)簡介
??? RBF網(wǎng)絡(luò)是一種3層前饋神經(jīng)網(wǎng)絡(luò)[5-7]。由輸入層、隱層和輸出層組成。網(wǎng)絡(luò)輸出層的輸出計算公式為:
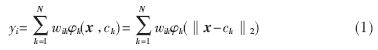
??? 這里 是輸入矢量;φk(·)是從正實數(shù)集合到實數(shù)集合的函數(shù),此函數(shù)的給出形式較多,這里采用高斯函數(shù):
是輸入矢量;φk(·)是從正實數(shù)集合到實數(shù)集合的函數(shù),此函數(shù)的給出形式較多,這里采用高斯函數(shù):
??? 
??? 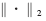 表示歐幾里德范式;wik是輸出層的權(quán)值;N表示隱含層神經(jīng)元的個數(shù);ck∈Rn×l表示輸入向量空間的RBF網(wǎng)絡(luò)的中心(簡稱中心)。對于隱含層的每一個神經(jīng)元,要計算與其關(guān)聯(lián)的中心和網(wǎng)絡(luò)輸入間的歐幾里德距離。隱含層神經(jīng)元的輸出是該距離的非線性函數(shù)。隱含層輸出的加權(quán)和是RBF網(wǎng)絡(luò)的輸出[5-7]。
表示歐幾里德范式;wik是輸出層的權(quán)值;N表示隱含層神經(jīng)元的個數(shù);ck∈Rn×l表示輸入向量空間的RBF網(wǎng)絡(luò)的中心(簡稱中心)。對于隱含層的每一個神經(jīng)元,要計算與其關(guān)聯(lián)的中心和網(wǎng)絡(luò)輸入間的歐幾里德距離。隱含層神經(jīng)元的輸出是該距離的非線性函數(shù)。隱含層輸出的加權(quán)和是RBF網(wǎng)絡(luò)的輸出[5-7]。
??? 由公式(1)和(2)可見,如果知道了RBF網(wǎng)絡(luò)的隱層節(jié)點數(shù)N、中心ck和δ寬度,RBF網(wǎng)絡(luò)從輸入到輸出就成了一個線性方程組,此時連接權(quán)值的學(xué)習(xí)可采用最小二乘法求解。因此,只要確定了N、ck和δ,RBF網(wǎng)絡(luò)模型也建立好了。而對RBF網(wǎng)絡(luò)的隱層節(jié)點個數(shù),本文采用了SOM(Self Organization Mapping)網(wǎng)絡(luò)的聚類算法來確定。對中心ck和寬度?滓則由本文提出的自適應(yīng)量子粒子群優(yōu)化算法來確定。
2 優(yōu)化的粒子群算法
2.1 量子粒子群優(yōu)化算法(QPSO)
??? 粒子群優(yōu)化(PSO)算法是一種基于群體智能的隨機(jī)搜索算法,其粒子在經(jīng)典力學(xué)空間中飛行,由于飛行軌跡確定,因此搜索空間有限,易陷入局部極值[8]。為了避免這個缺陷參考文獻(xiàn)[9]從量子力學(xué)的角度出發(fā)提出具有量子行為的粒子群優(yōu)化算法(QPSO)。由于在量子空間中的粒子移動時沒有確定的軌跡,使粒子可以在整個可能解空間中隨機(jī)搜索全局最優(yōu)解,因此QPSO算法的全局搜索能力遠(yuǎn)遠(yuǎn)優(yōu)于PSO算法[9]。
??? 由于在量子空間中,粒子的位置和速度不能同時確定,因此可以通過波函數(shù)(波函數(shù)的平方是粒子在空間中某一點出現(xiàn)的概率密度)來描述粒子的狀態(tài),并通過求解薛定諤方程得到粒子在空間某一點出現(xiàn)的概率密度函數(shù),隨后通過蒙特卡羅隨機(jī)模擬的方式得到量子空間中粒子的位置方程,如下式所示[10]:
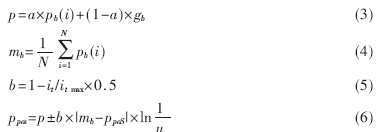
其中p為pb與gb之間的隨機(jī)位置;mb是所有粒子個體最佳位置pb的平均值;N為粒子個數(shù);b為收縮擴(kuò)張系數(shù),在QPSO算法收斂的過程中線性減小;it為當(dāng)前迭代次數(shù);it max為設(shè)定的最大迭代次數(shù);ppos是粒子的當(dāng)前位置;a和u都是0~1之間的隨機(jī)數(shù),當(dāng)u>=0.5時,公式(5)取“—”號,當(dāng)0
??? 在QPSO算法中,當(dāng)pb和gb很接近時意味著粒子的參數(shù)P很小,于是粒子的搜索范圍也變得很小。這樣,粒子群的進(jìn)化就會停滯;如果這個時候粒子群的當(dāng)前最佳位置處于一個局部最優(yōu)解,那么整個粒子群就會趨于早熟收斂[10]。
??? 在QPSO算法中,只有一個收縮擴(kuò)張系數(shù)b,對這個參數(shù)的選擇和控制是非常重要的,它關(guān)系到整個算法的收斂性能[10]。在參考文獻(xiàn)[10]中已經(jīng)證明,當(dāng)b<1.7時,粒子收斂,靠近粒子群的當(dāng)前最佳位置;當(dāng)b>1.8時,粒子發(fā)散,遠(yuǎn)離粒子群的當(dāng)前最佳位置。從公式(5)可以看出收縮擴(kuò)張系數(shù)b在粒子進(jìn)化過程隨著進(jìn)化代數(shù)的增加而線性減小,這種固定的變化并不能自適應(yīng)避免早熟趨勢。對此,本文做出如下改進(jìn):
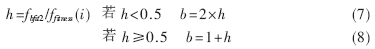
其中fbfit2為上一代群體獲得最佳位置gb的適應(yīng)度;ffitness(i)為第i個粒子的當(dāng)前適應(yīng)度。h為兩者的比值,h越小,說明粒子越遠(yuǎn)離粒子群的當(dāng)前最佳位置;h越大,說明粒子越靠近粒子群的當(dāng)前最佳位置。本文以h的值是否小于0.5為分界,如果h<0.5,說明粒子遠(yuǎn)離群體最佳位置gb,收縮擴(kuò)張系數(shù)b應(yīng)該小于1.7,使它收斂。因此將b值設(shè)為2×h,使它不超過1;h≥0.5,說明粒子靠近群體的當(dāng)前最佳位置gb,因此將b值設(shè)為1+h,增加其大于1.8的概率,使它盡量發(fā)散,擴(kuò)大搜索范圍。
3 AQPSO算法對RBF網(wǎng)絡(luò)的優(yōu)化
用AQPSO算法訓(xùn)練RBF神經(jīng)網(wǎng)絡(luò)時,首先要用向量形式表示RBF網(wǎng)絡(luò)的學(xué)習(xí)過程中需要調(diào)整的2個訓(xùn)練參數(shù):(1)徑向基函數(shù)的數(shù)據(jù)中心c。(2)徑向基函數(shù)的擴(kuò)展常數(shù),即寬度?滓。假設(shè)采用SOM聚類算法得到RBF網(wǎng)絡(luò)有個隱層節(jié)點,粒子群的規(guī)模,即粒子的個數(shù)為N,則對粒子參數(shù)編碼格式如表1所示,粒子群編碼格式如表2所示。粒子參數(shù)維數(shù)D=2m,每個粒子用1個2m維的向量來表示對應(yīng)的m個徑向基函數(shù)的數(shù)據(jù)中心和寬度,則粒子在N×D維的解空間POP中搜索群體的最佳位置,粒子群體的最佳位置對應(yīng)RBF網(wǎng)絡(luò)中的最優(yōu)的數(shù)據(jù)中心值和寬度。
?

??? 計算粒子群體的最佳位置需要比較粒子的適應(yīng)度,本文以每個粒子對應(yīng)的網(wǎng)絡(luò)參數(shù)在訓(xùn)練集上產(chǎn)生的均方差EMS作為粒子的適應(yīng)度的目標(biāo)函數(shù),則適應(yīng)度越小,EMS就越小,網(wǎng)絡(luò)對數(shù)據(jù)的擬合程度就越高。粒子的適應(yīng)度ffitness可用下面的公式計算:

??? 其中yi為第i個粒子的實際輸出值;ti為第i個粒子的期望輸出值。一旦粒子搜索完成,找到的粒子群中適應(yīng)度最小者,即擁有最佳位置gb,則對應(yīng)的隱層節(jié)點的最優(yōu)的數(shù)據(jù)中心和寬度也就確定了。對于RBF網(wǎng)絡(luò)隱層到輸出層網(wǎng)絡(luò)連接權(quán)值向量則可以使用最小二乘法(LMS)直接計算得到。
??? 具體的優(yōu)化RBF網(wǎng)絡(luò)模型實現(xiàn)如下:
??? (1)初始化粒子群體POP、每個粒子的最佳位置pb(0)=Φ、粒子群最佳位置gb=Φ、粒子的適應(yīng)度ffitness(0)=0、當(dāng)前粒子群的最佳適應(yīng)度fbfit1=0、上一代粒子群的最佳適應(yīng)度fbfit2=0和預(yù)設(shè)精度ε=0.09、最大迭代次數(shù)it max=200,i=1。
??? (2)根據(jù)當(dāng)前粒子i的位置(得到網(wǎng)絡(luò)的中心和寬度),結(jié)合最小二乘法(得到網(wǎng)絡(luò)的連接權(quán)值)計算出粒子i對所有訓(xùn)練樣本的適應(yīng)度;并比較粒子i的適應(yīng)ffitness(i)和整個粒子群體的適應(yīng)度fbfit1,如果ffitness(i)
??? (3)判斷所有粒子是否完成搜索,是則轉(zhuǎn)(4),否則返回(2)。
??? (4)比較當(dāng)前群體的最佳適應(yīng)度fbfit1和上一代群體的最佳適應(yīng)度fbfit2,若fbfit1
??? (5)判斷粒子群中最佳的適應(yīng)度即最小EMS,是否小于預(yù)設(shè)精度ε,是則轉(zhuǎn)(8),否則轉(zhuǎn)(6)。
??? (6)i=i+1,如果i≥it max,則轉(zhuǎn)(8),否則返回(7)。
??? (7)根據(jù)公式(8)至(9)更新每個粒子的位置,生成新的粒子群,返回(2)。
??? (8)RBF網(wǎng)絡(luò)訓(xùn)練完成,輸出粒子群最佳位置gb。其中,gb(1:m)對應(yīng)RBF網(wǎng)絡(luò)最優(yōu)的m個數(shù)據(jù)中心,gb(m+1:2×m)對應(yīng)RBF網(wǎng)絡(luò)最優(yōu)的m個寬度。用LMS計算出網(wǎng)絡(luò)連接權(quán)值,建立基于AQPSO算法的RBF網(wǎng)絡(luò)預(yù)測模型。
4 本文特征選擇方法
??? 本文特征選擇方法使用了本文提出的基于AQPSO算法優(yōu)化的RBF神經(jīng)網(wǎng)絡(luò)。簡單過程如下:
??? 訓(xùn)練樣本首先經(jīng)過分詞、特征提取得到原始特征集;然后利用參考文獻(xiàn)[2]提出的優(yōu)化的文檔頻方法先過濾掉一些詞條(最小詞頻數(shù)閾值n=2,最小文檔數(shù)閾值m=5, 這時的特征集為初選特征集),來降低特征空間維數(shù),從而降低RBF網(wǎng)絡(luò)的輸入層的單元數(shù),以減少該網(wǎng)絡(luò)的訓(xùn)練耗時。最后用本文所給的優(yōu)化的RBF網(wǎng)絡(luò)進(jìn)行特征優(yōu)選,從而選擇出較優(yōu)的特征子集。
??? 使用優(yōu)化的RBF網(wǎng)絡(luò)進(jìn)行特征優(yōu)選的方法如下:把每個訓(xùn)練樣本表示成向量的形式,每個初選特征(經(jīng)過優(yōu)化的文檔頻方法篩選的特征)在這個向量中對應(yīng)一個權(quán)值。本文取該特征在這個文本中出現(xiàn)的次數(shù)和這個文本所屬類的總訓(xùn)練文本中包含該特征的文本數(shù)的乘積為權(quán)值。將所有文本向量(相當(dāng)于初始粒子群)作為訓(xùn)練樣本,RBF網(wǎng)絡(luò)的輸入層神經(jīng)元個數(shù)等于初選特征數(shù);輸出層神經(jīng)元個數(shù)等于訓(xùn)練文本的類別個數(shù);隱含層神經(jīng)元個數(shù)相對固定(以網(wǎng)絡(luò)的泛化性和訓(xùn)練效率確定)。經(jīng)過訓(xùn)練后,存在一些較大權(quán)值對應(yīng)的隱含層神經(jīng)元,與其相連接的輸入層神經(jīng)元所代表的特征即為特征,它們的并集就是優(yōu)選的特征子集。
5 實驗例證
5.1 實驗語料庫
??? 在中文文本分類方面,經(jīng)過分析和比較,本文選用的分類語料庫是復(fù)旦大學(xué)中文文本分類語料庫。該語料庫由復(fù)旦大學(xué)計算機(jī)信息與技術(shù)系國際數(shù)據(jù)庫中心自然語言處理小組構(gòu)建,語料文檔全部采自互聯(lián)網(wǎng),可以免費下載,網(wǎng)址為:http://www.nlp.org.cn/categories/default.php?cat_id=16。
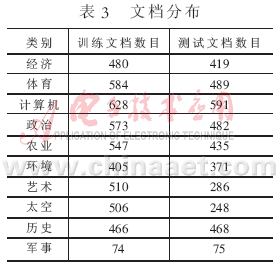
??? 復(fù)旦大學(xué)中文文本分類語料庫中包含20個類別,分為訓(xùn)練文檔集和測試文檔集2個部分。每個部分都包括20個的子目錄,相同類別的文檔存放在一個對應(yīng)的子目錄下;每個存儲文件只包含1篇文檔,所有文檔均以文件名作為唯一編號。共有19 637篇文檔,其中訓(xùn)練文檔9 804篇,測試文檔9 833篇;訓(xùn)練文檔和測試文檔基本按照1:1的比例來劃分。去除部分重復(fù)文檔和損壞文檔后,共保留文檔14 378篇,其中訓(xùn)練文檔8 214篇,測試文檔6 164篇,跨類別的重復(fù)文檔沒有考慮,即1篇文檔只屬于1個類別。該語料庫中的文檔的類別分布情況是不均勻的。其中,訓(xùn)練文檔最多的類Economy有1 369篇訓(xùn)練文檔,而訓(xùn)練文檔最少的類Communication有25篇訓(xùn)練文檔;同時,訓(xùn)練文檔數(shù)少于100篇的稀有類別共有11個。訓(xùn)練文檔集和測試文檔集之間互不重疊。本文只取前10個類的部分文檔,其類別文檔分布如表3所示。
5.2 實驗環(huán)境及參數(shù)設(shè)置
??? 實驗設(shè)備是1臺普通計算機(jī):操作系統(tǒng)為Microsoft Windows XP Professional(SP2),CPU規(guī)格為Intel(R) Celeron(R) CPU 2.40 GHz,內(nèi)存512 MB,硬盤80 GB。
??? 進(jìn)行中文分詞處理時,采用的是中科院計算所開源項目“漢語詞法分析系統(tǒng)ICTCLAS”系統(tǒng)。
??? 實驗使用的軟件工具是Weka,這是紐西蘭的Waikato大學(xué)開發(fā)的數(shù)據(jù)挖掘相關(guān)的一系列機(jī)器學(xué)習(xí)算法。實現(xiàn)語言是Java,可以直接調(diào)用,也可以在代碼中調(diào)用。Weka包括數(shù)據(jù)預(yù)處理、分類、回歸分析、聚類、關(guān)聯(lián)規(guī)則、可視化等工具,對機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘的研究工作很有幫助,是開源項目,網(wǎng)址為:http://www.cs.waikato.ac.nz/ml/weka/。實驗使用的計算工具為MATLAB 7.0。
5.3 實驗所用分類器及其評價標(biāo)準(zhǔn)
??? 本實驗旨在比較本文方法與信息增益(IG)、x2統(tǒng)計量(CHI)、互信息(MI)等3種特征選擇方法對后續(xù)文本分類精度的影響,因此本實驗在各種特征選擇方法后采用相同的分類器對文本進(jìn)行分類。本實驗中使用KNN分類器來比較這幾種特征選擇方法(K設(shè)置為10)。
??? 為了評價實驗效果,實驗中選擇分類正確率和召回率作為評價標(biāo)準(zhǔn):準(zhǔn)確率(Precision)=a/(a+b),它是所判斷的文本與人工分類文本吻合的文本所占的比率;召回率(Recall)=a/(a+c),是人工分類結(jié)果應(yīng)有的文本與分類系統(tǒng)吻合的文本所占的比率。在實際中,查準(zhǔn)率比查全率重要。其中a、b、c代表相應(yīng)的文檔數(shù),它們的含義如表4所示。

5.4 實驗結(jié)果
??? 表5總結(jié)了四種方法在所選數(shù)據(jù)集上的分類準(zhǔn)確率和召回率,從總體上看,本文方法>IG>CHI>MI。由于本文方法使用了優(yōu)化的RBF網(wǎng)絡(luò)對特征進(jìn)行優(yōu)選,使得選擇出的特征子集較優(yōu)秀,所以效果最佳;由于IG方法受樣本分布影響,在樣本分布不均勻的情況下,它的效果就會大大降低,但從整體上看本文所選樣本分布相對均勻,只有極個別相差較大,所以總體效果次之;由于MI方法僅考慮了特征發(fā)生的概率,而CHI方法同時考慮了特征存在與不存在時的情況,所以CHI方法比MI方法效果要好。總的來說,本文所提的方法是有效的,在文本挖掘中有一定的實用價值。

??? 本文首先提出了一個自適應(yīng)量子粒子群優(yōu)化算法,用于訓(xùn)練RBF網(wǎng)絡(luò)的基函數(shù)中心和寬度,并結(jié)合最小二乘法計算網(wǎng)絡(luò)權(quán)值,對RBF網(wǎng)絡(luò)的泛化能力進(jìn)行改進(jìn)。然后把該RBF神經(jīng)網(wǎng)絡(luò)用于特征選擇。實驗結(jié)果表明,采用自適應(yīng)量子粒子群優(yōu)化算法獲得的RBF網(wǎng)絡(luò)模型不但具有很強(qiáng)的泛化能力,而且具有良好的穩(wěn)定性,能夠選擇出較優(yōu)秀的特征子集。特征選擇方法與3種經(jīng)典特征選擇方法“信息增益”和“統(tǒng)計量”以及“互信息”相比有較高的準(zhǔn)確率和召回率,為后續(xù)的知識發(fā)現(xiàn)算法減少了時間與空間復(fù)雜性,從而使得本文方法在文本分類中有一定的使用價值。
參考文獻(xiàn)
[1] DELGADO M, MARTIN-BAUTISTA M J, SANCHEZ D, et al. Mining text data: special features and patterns [C]//In Proceedings of ESF Exploratory Workshop. London: U.K, Sept, 2002:32-38.
[2] 朱顥東,鐘勇.一種新的基于多啟發(fā)式的特征選擇算法[J].計算機(jī)應(yīng)用,2009,29(3):849-851.
[3] FRIEDMAN N, GEIGER D, GOLDSZMIDT M. Bayesian network classifiers[J]. machineIearning,1997,29(2):131-163.
[4] 張海龍,王蓮芝.自動文本分類特征選擇方法研究[J].計算機(jī)工程與設(shè)計,2006,27(20):3838-3841.
[5] 蔣華剛,吳耿鋒.基于人工免疫原理的RBF網(wǎng)絡(luò)預(yù)測模型[J].計算機(jī)工程,2008,34(2):202-205.
[6] 顏聲遠(yuǎn),于曉洋,張志儉,等.基于RBF網(wǎng)絡(luò)的顯示設(shè)計主觀評價方法[J].哈爾濱工程大學(xué)學(xué)報,2007,28(10):1150-1155.
[7] 臧小剛,宮新保,常成,等.一種基于免疫系統(tǒng)的RBF網(wǎng)絡(luò)在線訓(xùn)練方法[J].電子學(xué)報,2008,36(7):1396-1400.
[8] 劉鑫朝,顏宏文.一種改進(jìn)的粒子群優(yōu)化RBF網(wǎng)絡(luò)學(xué)習(xí)算法[J].計算機(jī)技術(shù)與發(fā)展,2006,16(2):185-187.
[9] 陳偉,馮斌,孫俊.基于QPSO算法的RBF神經(jīng)網(wǎng)絡(luò)參數(shù)優(yōu)化優(yōu)化仿真研究[J].計算機(jī)應(yīng)用,2006,26(8):19-28.
[10] SUN Jun, FENG Bin, XU Wen Bo. Particle swarm pptimization with particles having quantum behavior[A] Proceeding of 2004 Congress on Evolutionary Computation[C].Piscataway CA: IEEE Press, 2004:325-330.