
摘 要: 引入幀跳躍的概念,從而改進(jìn)了傳統(tǒng)的端點(diǎn)檢測(cè)算法和DTW算法,實(shí)現(xiàn)了一個(gè)改進(jìn)的實(shí)時(shí)語(yǔ)音識(shí)別系統(tǒng),并在計(jì)算機(jī)上進(jìn)行了模擬仿真。實(shí)驗(yàn)結(jié)果表明,改進(jìn)后的算法能有效提高孤立詞的識(shí)別速度和識(shí)別精度。
關(guān)鍵詞: 語(yǔ)音識(shí)別;動(dòng)態(tài)時(shí)間規(guī)整;端點(diǎn)檢測(cè)
通過(guò)語(yǔ)言進(jìn)行交流是人類最基本也是最廣泛使用的交流方式。語(yǔ)音識(shí)別是指讓機(jī)器通過(guò)識(shí)別和理解過(guò)程把人類的語(yǔ)言信號(hào)轉(zhuǎn)變?yōu)橄鄳?yīng)的文本或命令的技術(shù)[1],其本質(zhì)上是一種模式識(shí)別的過(guò)程,主要包含特征提取技術(shù)、模型訓(xùn)練技術(shù)及模式匹配技術(shù)3個(gè)方面。其基本思路是提取語(yǔ)音信號(hào)中能代表語(yǔ)音內(nèi)容的特征向量,訓(xùn)練過(guò)程通過(guò)特定算法建立模板庫(kù),識(shí)別過(guò)程按照一定的規(guī)則將提取出的特征與模板庫(kù)中的參考模板相對(duì)比得出識(shí)別結(jié)果。
語(yǔ)音識(shí)別系統(tǒng)一般包含預(yù)處理模塊、特征提取模塊、訓(xùn)練模塊和識(shí)別模塊[2]。其中預(yù)處理模塊實(shí)現(xiàn)讀入語(yǔ)音信號(hào)并對(duì)信號(hào)進(jìn)行濾波、預(yù)加重、分幀、加窗和端點(diǎn)檢測(cè)等功能;特征提取模塊則是對(duì)針對(duì)每一幀進(jìn)行運(yùn)算,提取出每一幀的時(shí)域參數(shù)或者頻域參數(shù);訓(xùn)練模塊是將帶識(shí)別語(yǔ)音模板通過(guò)計(jì)算得到模板向量并存入數(shù)據(jù)庫(kù);識(shí)別模塊是將待識(shí)別語(yǔ)音序列同模板庫(kù)進(jìn)行比較并得出識(shí)別結(jié)果,識(shí)別算法多用的是動(dòng)態(tài)時(shí)間規(guī)整DTW(Dynamic Time Warping)算法。DTW是把時(shí)間規(guī)整和距離測(cè)度計(jì)算結(jié)合起來(lái)的一種非線性規(guī)整技術(shù),它盡管對(duì)大詞匯量、連續(xù)語(yǔ)音和非特定人語(yǔ)音識(shí)別效果較差,但對(duì)孤立詞語(yǔ)音識(shí)別和較為簡(jiǎn)潔,正確識(shí)別率也較高,因此,DTW算法在孤立詞語(yǔ)音識(shí)別系統(tǒng)有較廣泛的應(yīng)用[3],因而對(duì)其進(jìn)一步地研究以提高其正確識(shí)別速度具有很強(qiáng)的實(shí)用價(jià)值。一個(gè)典型的孤立詞語(yǔ)音識(shí)別系統(tǒng)流程圖如圖1所示。

識(shí)別精度和識(shí)別速度是評(píng)價(jià)孤立詞語(yǔ)音識(shí)別系統(tǒng)性能的兩個(gè)最主要的參數(shù),而端點(diǎn)檢測(cè)和模板匹配算法是影響這兩個(gè)參數(shù)的最主要的原因。端點(diǎn)檢測(cè)的目的是從包含語(yǔ)音的一般信號(hào)中確定出語(yǔ)音的起點(diǎn)以及終點(diǎn),有效的端點(diǎn)檢測(cè)不僅能使處理時(shí)間最小,而且能排除無(wú)聲段的噪聲干擾,從而使識(shí)別系統(tǒng)具有良好的識(shí)別性能。模板匹配的目的是匹配輸入向量和模板向量并得到結(jié)果,它是整個(gè)系統(tǒng)中最耗時(shí)、耗資源的一個(gè)環(huán)節(jié),因此模板匹配算法的性能好壞將直接影響整個(gè)系統(tǒng)的性能優(yōu)劣。
本文就提高孤立詞語(yǔ)音識(shí)別系統(tǒng)的識(shí)別精度和識(shí)別速度展開討論,提出了一種改進(jìn)的端點(diǎn)檢測(cè)方法和改進(jìn)的DTW算法,通過(guò)實(shí)驗(yàn)證明將兩種算法結(jié)合起來(lái)能提高整個(gè)系統(tǒng)的識(shí)別精度和識(shí)別速度,取得了預(yù)期的效果。
1 改進(jìn)語(yǔ)音識(shí)別算法
1.1 端點(diǎn)檢測(cè)
1.1.1 傳統(tǒng)端點(diǎn)檢測(cè)
傳統(tǒng)端點(diǎn)檢測(cè)算法采用短時(shí)時(shí)域分析方法,通過(guò)短時(shí)能量和短時(shí)過(guò)零率來(lái)判斷端點(diǎn)位置。短時(shí)能量是基于幀進(jìn)行計(jì)算的,如式(1)所示。短時(shí)過(guò)零率指一幀語(yǔ)音信號(hào)中語(yǔ)音波形通過(guò)零電平的次數(shù),其定義如式(2)所示。對(duì)于連續(xù)的語(yǔ)音信號(hào),過(guò)零是指時(shí)域波形穿過(guò)時(shí)間軸;對(duì)于離散信號(hào),相鄰的取樣值改變符號(hào)則稱為過(guò)零。
端點(diǎn)檢測(cè)主要使用的方法有以下兩種。
(1)雙門限端點(diǎn)檢測(cè)[4]:即分別為短時(shí)能量和短時(shí)過(guò)零率各設(shè)置一個(gè)高門限和一個(gè)低門限,低門限被超過(guò)基本值可以確定進(jìn)入了過(guò)渡段;高門限用于確定語(yǔ)音真正的起始端點(diǎn),僅高門限被成功檢測(cè)未必就是語(yǔ)音的起始端點(diǎn),也有可能是短時(shí)的噪音,但是噪聲一般持續(xù)時(shí)間比較短,可以用持續(xù)時(shí)間來(lái)決定是噪聲還是語(yǔ)音。
(2)動(dòng)態(tài)窗長(zhǎng)語(yǔ)音端點(diǎn)檢測(cè)[5]:語(yǔ)音端點(diǎn)檢測(cè)時(shí),語(yǔ)音為靜音段,采用較長(zhǎng)的窗;語(yǔ)音和靜音的過(guò)渡段采用較小的窗,可以確切判斷語(yǔ)音的起始點(diǎn);一旦確定語(yǔ)音的起始點(diǎn)就改用常規(guī)窗長(zhǎng),因?yàn)闈h語(yǔ)音節(jié)末尾都是濁音,只用短時(shí)能量就可以較好地判斷一個(gè)語(yǔ)音的末點(diǎn)。
1.1.2 改進(jìn)端點(diǎn)檢測(cè)
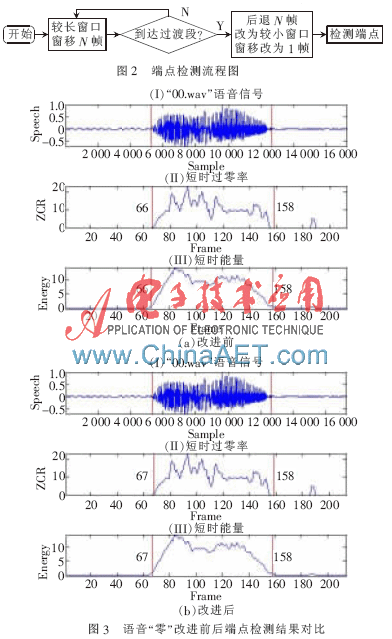
一般在一段語(yǔ)音信號(hào)中,無(wú)聲段會(huì)占據(jù)相當(dāng)一部分比例,這樣進(jìn)行端點(diǎn)檢測(cè)時(shí),會(huì)造成一部分計(jì)算資源浪費(fèi)在檢測(cè)無(wú)聲段上。并且雙門限檢測(cè)方法窗口每滑動(dòng)一次就要對(duì)兩個(gè)參數(shù)進(jìn)行計(jì)算和比較,因此所需要的計(jì)算資源比較大。語(yǔ)音段和過(guò)渡段相對(duì)于靜音段的短時(shí)過(guò)零率和短視能量要高出許多,并且隨著靜音段結(jié)束和語(yǔ)音段開始,中間過(guò)渡段的短時(shí)過(guò)零率和短視能量呈單調(diào)遞增趨勢(shì)。基于這個(gè)特性,本文提出一種基于跳躍幀的端點(diǎn)檢測(cè)方法,在動(dòng)態(tài)窗長(zhǎng)的基礎(chǔ)上引入幀跳躍這一概念,形成一種新的端點(diǎn)檢測(cè)方法。實(shí)驗(yàn)證明,該方法能有效地降低端點(diǎn)檢測(cè)的時(shí)間以及提高端點(diǎn)檢測(cè)的精確度。
端點(diǎn)檢測(cè)算法流程如圖2所示。進(jìn)行端點(diǎn)檢測(cè)時(shí),對(duì)于剛開始檢測(cè)的無(wú)聲階段,采用較長(zhǎng)的窗長(zhǎng)并且在計(jì)算和比較第一幀之后直接將窗口向前移動(dòng)N幀,直到判斷為進(jìn)入了過(guò)渡段或者語(yǔ)音段。當(dāng)檢測(cè)到語(yǔ)音進(jìn)入過(guò)渡段時(shí),首先將窗口后退N幀并且改為使用較小的窗長(zhǎng),然后開始逐幀進(jìn)行比較以精確確定語(yǔ)音的起始端點(diǎn),之后進(jìn)入語(yǔ)音段后就改為使用常規(guī)大小的窗長(zhǎng)。語(yǔ)音末尾端點(diǎn)的檢測(cè)與起始端點(diǎn)檢測(cè)類似。這里關(guān)鍵的就是N的取值問(wèn)題,N取得太大或者太小雖然不會(huì)影響算法的準(zhǔn)確性,但是對(duì)算法的速度有比較明顯的影響。根據(jù)實(shí)驗(yàn)結(jié)果比較可以得出,取N=10時(shí)算法的效率最高。圖3為語(yǔ)音“零”的改進(jìn)前后端點(diǎn)檢測(cè)結(jié)果比較。
1.2 DTW算法
1.2.1 DTW原理
在語(yǔ)音識(shí)別中解決語(yǔ)音信號(hào)特征參數(shù)序列比較問(wèn)題時(shí),不能簡(jiǎn)單地將輸入模板和相應(yīng)的參考模板直接進(jìn)行比較,因?yàn)檎Z(yǔ)音信號(hào)具有較大的隨機(jī)性,即使是同一個(gè)人在不同的時(shí)候說(shuō)話,也不能具有完全相同的時(shí)間長(zhǎng)度,因此時(shí)間歸正處理是必不可少的[6]。為此,日本學(xué)者板倉(cāng)將動(dòng)態(tài)規(guī)劃(DP)算法的概念用于解決語(yǔ)音識(shí)別中孤立詞識(shí)別時(shí)說(shuō)話速度不均勻的問(wèn)題,提出了著名的DTW算法。DTW算法是一種將全局最優(yōu)化問(wèn)題轉(zhuǎn)化為局部最優(yōu)問(wèn)題的算法,是把時(shí)間規(guī)整和距離測(cè)度計(jì)算結(jié)合起來(lái)的一種非線性規(guī)整技術(shù)。其具體實(shí)現(xiàn)原理如下。
將輸入信號(hào)和參考信號(hào)經(jīng)過(guò)特征提取和訓(xùn)練之后分別得到一組模板序列。這里假設(shè)輸入信號(hào)模板序列用X={x1,tx1,x2,tx2,…,xm,txm}表示,參考信號(hào)模板序列用Y={y1,ty1,y2,ty2,…,yn,tyn}表示。其中xi、yi,為音高序列,txi、tyi為其對(duì)應(yīng)的音長(zhǎng)。它們之間的相似度用其之間的距離D(X,Y)來(lái)度量,距離越小表示相似度越高。為了度量這一距離,就要從X、Y中各個(gè)幀的對(duì)應(yīng)點(diǎn)之間的距離算起。設(shè)m、n為分別從X、Y中任意選擇的一幀信號(hào),則D(Xm,Yn)就表示為這兩幀特征矢量之間的距離。
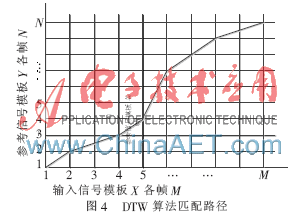
如圖4所示,橫軸是輸入信號(hào)模板X的各幀號(hào)m=1~M,縱軸上是參考信號(hào)模板Y的幀號(hào)n=1~N,其中N≠M,網(wǎng)格中的每一個(gè)交叉點(diǎn)表示兩個(gè)模板中的樣點(diǎn)匹配,匹配時(shí)從第一個(gè)點(diǎn)D(1,1)開始,一直計(jì)算到最后一個(gè)點(diǎn)D(M,N)結(jié)束。利用動(dòng)態(tài)規(guī)劃算法可以尋找到這樣的一條路徑,但是這條路徑不是隨意選擇的。
DTW算法的目標(biāo)是尋找這樣一條路徑:該路徑從起始點(diǎn)出發(fā)依次通過(guò)各個(gè)交叉點(diǎn)并最終到達(dá)終止點(diǎn)結(jié)束,這條路徑能使得該路徑上所有交叉點(diǎn)的累計(jì)失真最小,即保證兩個(gè)模板間存在最大的相似性,失真越小,相似度越高。為了避免盲目搜索,一般對(duì)于DTW的搜索路徑會(huì)有如下限制。
(1)路徑要通過(guò)起始點(diǎn)和終止點(diǎn)。
(2)為使路徑不至于過(guò)分傾斜,一般對(duì)路徑的最大和最小斜率會(huì)做適當(dāng)?shù)南拗疲话闳∽畲笮甭蕿?,最小斜率為0.5。
(3)具有連續(xù)性。在動(dòng)態(tài)伸縮路徑中,下一點(diǎn)與當(dāng)前點(diǎn)一定是相鄰的,下一個(gè)點(diǎn)可以位于當(dāng)前點(diǎn)的正上方、正右方或者是右上方對(duì)角線,但是不允許跨越一個(gè)點(diǎn)至下一個(gè)點(diǎn)。
(4)具有單調(diào)性。動(dòng)態(tài)伸縮路徑的延伸的方向一定是向右或者向上,反方向的延伸是不被允許的。
傳統(tǒng)DTW算法主要有以下幾個(gè)缺點(diǎn)。
(1)計(jì)算量過(guò)大。由于要找出最佳的匹配點(diǎn),因此程序會(huì)考慮多種情況,從而使計(jì)算量加大。
(2)識(shí)別性能過(guò)分依賴于端點(diǎn)檢測(cè)。端點(diǎn)檢測(cè)會(huì)受到不同的環(huán)境因素影響,DTW算法的識(shí)別準(zhǔn)確度也會(huì)受到影響。
(3)沒(méi)有充分利用語(yǔ)音信號(hào)的時(shí)域特征信息。
1.2.2 改進(jìn)DTW算法
由于DTW的計(jì)算量非常巨大,如果對(duì)于所有的參考模板進(jìn)行全部完全匹配,則會(huì)耗費(fèi)大量的計(jì)算資源。使用搜索寬度限制和放寬搜索寬度可以減低DTW的時(shí)間復(fù)雜度。本文在此基礎(chǔ)上提出一種簡(jiǎn)單的改進(jìn)策略,具體如下:由于輸入信號(hào)模板與參考信號(hào)模板不可能完全相同,通過(guò)DTW算法所要尋找的是與輸入信號(hào)最相似的參考信號(hào),因此可以在比較之前先計(jì)算一下兩個(gè)序列的長(zhǎng)度,如果兩個(gè)序列長(zhǎng)度相差過(guò)多,那么基本可以確定兩個(gè)序列不為相似序列,直接跳過(guò)此次匹配過(guò)程;接著可以設(shè)置一個(gè)相似度的閾值下限,在匹配過(guò)程中一旦這個(gè)相似度低于閾值,就表明輸入模板基本不可能與參考模板匹配,則立即停止此次匹配進(jìn)入下一輪匹配。實(shí)驗(yàn)證明,當(dāng)參考信號(hào)模板數(shù)據(jù)庫(kù)足夠大時(shí),使用這種策略能夠節(jié)省大量的時(shí)間,并且檢測(cè)的精確度幾乎不受影響。
2 實(shí)驗(yàn)與結(jié)果
本系統(tǒng)采用改進(jìn)的端點(diǎn)檢測(cè)方法和改進(jìn)的DTW匹配算法實(shí)現(xiàn)語(yǔ)音識(shí)別,并且采用MFCC(Mel Frequency Cepstral Coefficient)特征提取。語(yǔ)音采樣頻率為8 kHz,16 bit量化精度,窗函數(shù)采用Hamming窗。實(shí)驗(yàn)參考模板數(shù)據(jù)內(nèi)容為數(shù)字語(yǔ)音“0”到“99”,輸入模板為10組語(yǔ)音數(shù)據(jù)。
實(shí)驗(yàn)主要分為3組,第1組主要比較改進(jìn)前后端點(diǎn)檢測(cè)及生成模板庫(kù)的時(shí)間,第2組主要比較輸入的10組語(yǔ)音數(shù)據(jù)的識(shí)別速度,第3組主要比較輸入的10組語(yǔ)音數(shù)據(jù)的識(shí)別正確率。具體實(shí)驗(yàn)結(jié)果如表1所示。

通過(guò)表1可以發(fā)現(xiàn),改進(jìn)后的算法在識(shí)別準(zhǔn)確率上與原有算法相當(dāng),但是在模板庫(kù)生成時(shí)間和識(shí)別速度上要比原有算法分別有接近10%和17%的提升,進(jìn)一步驗(yàn)證了算法的可行性。
本文研究了一個(gè)孤立詞語(yǔ)音識(shí)別系統(tǒng),提出了一種新的端點(diǎn)檢測(cè)改進(jìn)策略和DTW算法匹配改進(jìn)策略,并將兩者結(jié)合運(yùn)用于語(yǔ)音識(shí)別系統(tǒng)。實(shí)驗(yàn)表明,改進(jìn)的語(yǔ)音識(shí)別系統(tǒng)在語(yǔ)音的識(shí)別速度和識(shí)別精度上都得到了較大程度的提高,達(dá)到了比較良好的性能。
參考文獻(xiàn)
[1] 張亞歌,張?zhí)?一種基于雙幀動(dòng)態(tài)時(shí)間規(guī)整的語(yǔ)音識(shí)別新方法[J].微電子學(xué)與計(jì)算機(jī),2010(11):17-19+24.
[2] RABINER L R, LEVINSON S E. Isolated and connected word recognition-theory and selected applications[J]. IEEE Transactions on Communications, 1981,COM-29(5):621-659.
[3] 胡金平,陳若珠,李戰(zhàn)明.語(yǔ)音識(shí)別中DTW改進(jìn)算法的研究[J].微型機(jī)與應(yīng)用,2011(3):30-32.
[4] 李景川,董慧穎.一種改進(jìn)的基于短時(shí)能量的端點(diǎn)檢測(cè)算法[J].沈陽(yáng)理工大學(xué)學(xué)報(bào),2008(3):37-39.
[5] 陳立萬(wàn).基于語(yǔ)音識(shí)別系統(tǒng)中DTW算法改進(jìn)技術(shù)研究[J].微計(jì)算機(jī)信息,2006(5):267-269.
[6] 吳艷艷.孤立詞語(yǔ)音識(shí)別的關(guān)鍵技術(shù)研究[D].青島:青島大學(xué),2012.