
0 引 言
在孤立詞語(yǔ)音識(shí)別中,最為簡(jiǎn)單有效的方法是采用動(dòng)態(tài)時(shí)間規(guī)整(Dynamic Time Warping,DTW)算法,該算法解決了發(fā)音長(zhǎng)短不一的模板匹配問題,是語(yǔ)音識(shí)別中出現(xiàn)最早、較為經(jīng)典的一種算法。用于孤立詞識(shí)別,該算法較現(xiàn)在比較流行的HMM算法在相同的環(huán)境條件下,識(shí)別效果相差不大,但HMM算法要復(fù)雜的多,這主要體現(xiàn)在HMM算法在訓(xùn)練階段需要提供大量的語(yǔ)音數(shù)據(jù),通過(guò)反復(fù)計(jì)算才能得到模型參數(shù),而DTW算法的訓(xùn)練中幾乎不需要額外的計(jì)算。所以在孤立詞語(yǔ)音識(shí)別中,DTW算法仍得到廣泛的應(yīng)用。本系統(tǒng)就采用了該算法。
1 系統(tǒng)概述
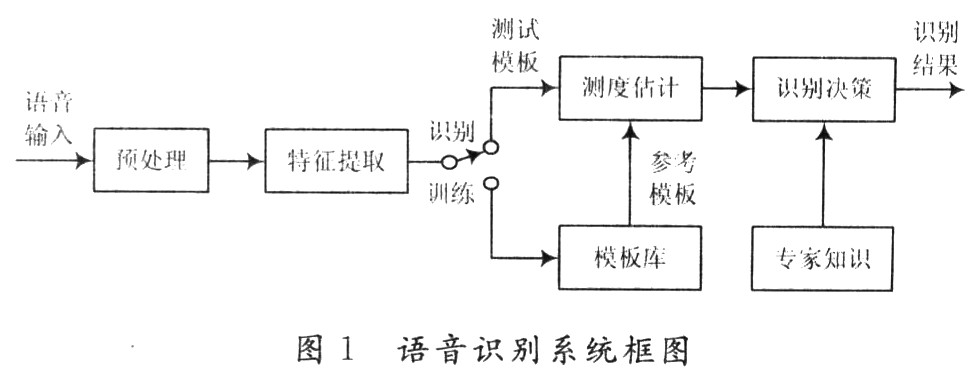
語(yǔ)音識(shí)別系統(tǒng)的典型實(shí)現(xiàn)方案如圖1所示。輸入的模擬語(yǔ)音信號(hào)首先要進(jìn)行預(yù)處理,包括預(yù)濾波、采樣和量化、加窗、斷點(diǎn)檢測(cè)、預(yù)加重等。語(yǔ)音信號(hào)經(jīng)過(guò)預(yù)處理后,接下來(lái)重要的一環(huán)就是特征參數(shù)提取,其目的是從語(yǔ)音波形中提取出隨時(shí)間變化的語(yǔ)音特征序列。然后建立聲學(xué)模型,在識(shí)別的時(shí)候?qū)⑤斎氲恼Z(yǔ)音特征同聲學(xué)模型進(jìn)行比較,得到最佳的識(shí)別結(jié)果。
2 硬件構(gòu)成
2.1 系統(tǒng)構(gòu)成
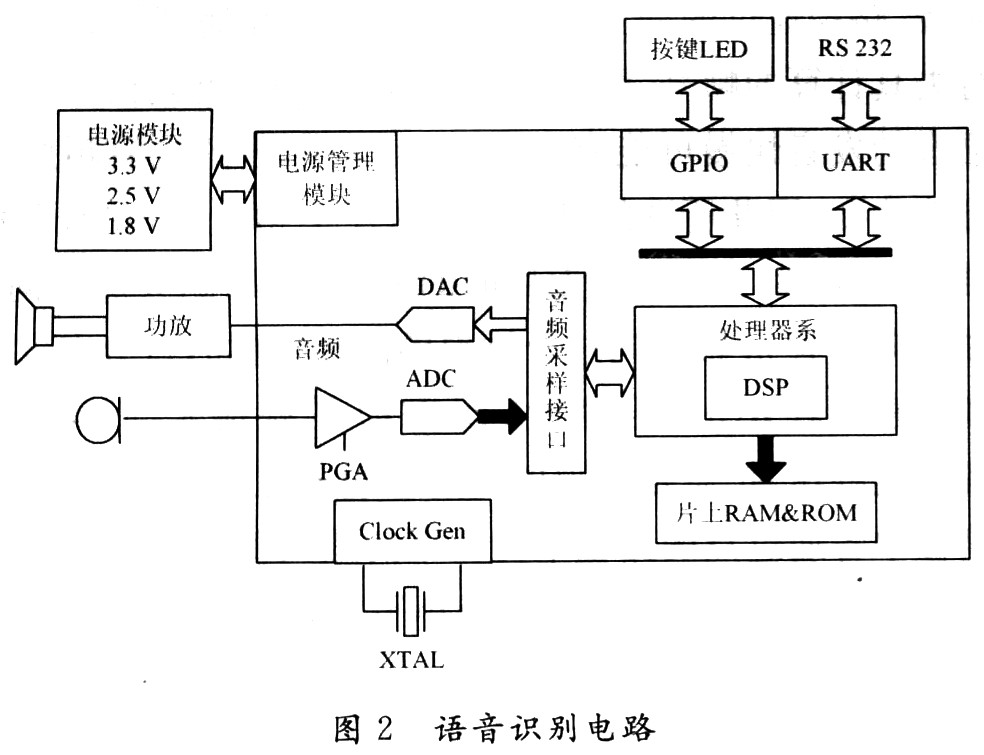
這里采用DSP芯片為核心(圖2),系統(tǒng)包括直接雙訪問快速SRAM、一路ADC/一路DAC及相應(yīng)的模擬信號(hào)放大器和抗混疊濾波器。外部只需擴(kuò)展FLASH存儲(chǔ)器、電源模塊等少量電路即可構(gòu)成完整系統(tǒng)應(yīng)用。
2.2 系統(tǒng)主要功能模塊構(gòu)成
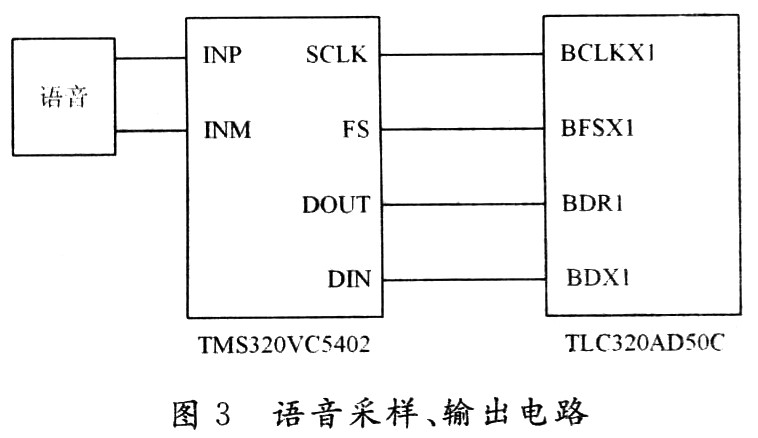
語(yǔ)音處理模塊采用TI TMS320VC5402,其主要特點(diǎn)包括:采用改進(jìn)的哈佛結(jié)構(gòu),一條程序總線(PB),三條數(shù)據(jù)總線(CB,DB,EB)和四條地址總線(PAB,CAB,DAB,EAB),帶有專用硬件邏輯CPU(40位算術(shù)邏輯單元(ALU),包括1個(gè)40位桶形移位器和二個(gè)40位累加器;一個(gè)17×17乘法器和一個(gè)40位專用加法器,允許16位帶或不帶符號(hào)的乘法),片內(nèi)存儲(chǔ)器(八個(gè)輔助寄存器及一個(gè)軟件棧),片內(nèi)外專用的指令集,允許使用業(yè)界最先進(jìn)的定點(diǎn)DSP C語(yǔ)言編譯器。TMS320VC5402含4 KB的片內(nèi)ROM和16 KB的雙存取RAM,一個(gè)HPI(HostPortInterface)接口,二個(gè)多通道緩沖單口MCBSP(Multi-Channel Buffered SerialPort),單周期指令執(zhí)行時(shí)間10 ns,帶有符合IEEE1149.1標(biāo)準(zhǔn)的JTAG邊界掃描仿真邏輯。語(yǔ)音輸入、輸出的模擬前端采用TI公司的TLC320ADSOC,它是一款集成ADC和DAC于一體的模擬接口電路,并且與DSP接口簡(jiǎn)單,性能高、功耗低,已成為當(dāng)前語(yǔ)音處理的主流產(chǎn)品。16位數(shù)據(jù)結(jié)構(gòu),音頻采樣頻率為2~22.05 kHz,內(nèi)含抗混疊濾波器和重構(gòu)濾波器的模擬接口芯片,還有一個(gè)能與許多DSP芯片相連的同步串行通信接口。TLC320AD50C片內(nèi)還包括一個(gè)定時(shí)器(調(diào)整采樣率和幀同步延時(shí))和控制器(調(diào)整編程放大增益、鎖相環(huán)PLL、主從模式)。TLC320AD50C與TMS320VC5402的硬件連接,如圖3所示。
3 語(yǔ)音識(shí)別算法實(shí)現(xiàn)
3.1 語(yǔ)音信號(hào)的端點(diǎn)檢測(cè)
語(yǔ)音的端點(diǎn)檢測(cè)是語(yǔ)音識(shí)別中最基本的模塊,在嵌入式語(yǔ)音識(shí)別系統(tǒng)中更是占有非常重要的地位:一方面端點(diǎn)檢測(cè)的結(jié)果不準(zhǔn)確,系統(tǒng)的識(shí)別性能就得不到保證;另一方面如果端點(diǎn)檢測(cè)的結(jié)果過(guò)于放松,雖然語(yǔ)音部分被很好地包含在處理的信號(hào)中,但是增加過(guò)多的靜音則會(huì)增加系統(tǒng)的運(yùn)算量,同時(shí)對(duì)識(shí)別性能也有負(fù)面影響。因此為能量和過(guò)零率兩個(gè)參數(shù)分別設(shè)定兩個(gè)門限,一個(gè)是比較低的門限,數(shù)值比較小,對(duì)信號(hào)的變化比較敏感,很容易就被超過(guò)。另一個(gè)是比較高的門限,數(shù)值比較大,信號(hào)必須達(dá)到一定的強(qiáng)度,該門限才可能被超過(guò)。低門限被超過(guò)未必就是語(yǔ)音的開始,有可能是時(shí)間很短的噪聲引起的。高門限被超過(guò),則基本確信是由于語(yǔ)音信號(hào)引起的。
整個(gè)語(yǔ)音信號(hào)的端點(diǎn)檢測(cè)可以分為四段:靜音、過(guò)渡段、語(yǔ)音段、結(jié)束。程序中使用一個(gè)變量status來(lái)表示當(dāng)前所處的狀態(tài)。在靜音段,如果能量或過(guò)零率超越了低門限,就應(yīng)該開始標(biāo)記起始點(diǎn),進(jìn)入過(guò)渡段。在過(guò)渡段中,由于參數(shù)的數(shù)值比較小,不能確信是否處于真正的語(yǔ)音段,因此只要兩個(gè)參數(shù)的數(shù)值都回落到低門限以下,就將當(dāng)前狀態(tài)恢復(fù)到靜音狀態(tài)。而如果在過(guò)渡段中兩個(gè)參數(shù)中任意一個(gè)超過(guò)了高門限,就可以確信進(jìn)入語(yǔ)音段了。一些突發(fā)性的噪聲可以引發(fā)短時(shí)能量或過(guò)零率的數(shù)值很高,但是往往不能維持足夠長(zhǎng)的時(shí)間,這些可以通過(guò)設(shè)定最短時(shí)間門限來(lái)判別。當(dāng)前狀態(tài)處于語(yǔ)音段時(shí),如果兩個(gè)參數(shù)的數(shù)值降低到低門限以下,而且總的計(jì)時(shí)長(zhǎng)度小于最短時(shí)間門限,則認(rèn)為這是一段噪音,繼續(xù)掃描以后的語(yǔ)音數(shù)據(jù)。否則就標(biāo)記好結(jié)束端點(diǎn),并返回。
3.2 語(yǔ)音特征參數(shù)的提取
近年來(lái),一種能夠比較充分利用人耳這種特殊的感知特新的參數(shù)得到了廣泛的應(yīng)用,這就是Mel尺度倒譜參數(shù)(Mel-scaled Cepstrum Coefficients,MFCC)。它和線性頻率的轉(zhuǎn)換關(guān)系是:
fMel=2 596log10(1+f/700)
MFCC參數(shù)是按幀計(jì)算的。首先要通過(guò)FFT得到該幀信號(hào)的功率譜,轉(zhuǎn)換為Mel頻率下的功率譜。這需要在計(jì)算之前先在語(yǔ)音的頻譜范圍內(nèi)設(shè)置若干個(gè)帶通濾波器Hm(n)。MFCC參數(shù)的計(jì)算流程為:
(1)確定每一幀語(yǔ)音采樣序列的點(diǎn)數(shù),本系統(tǒng)采取N=256點(diǎn)。對(duì)每幀序列s(n)進(jìn)行預(yù)加重處理后再經(jīng)過(guò)離散FFT變換,取模的平方得到離散功率譜s(n)。
(2)計(jì)算s(n)通過(guò)M個(gè)Hm(n)后所得的功率值,即計(jì)算s(n)和Hm(n)在各個(gè)離散頻率點(diǎn)上乘積之和,得到M個(gè)參數(shù)Pm,m=0,1,…,M-1。
(3)計(jì)算Pm的自然對(duì)數(shù),得到Lm,m=0,1,…,M-1。
(4)對(duì)L0,L1,…,LM-1計(jì)算其離散余弦變換,得到Dm,m=0,1,…,M-1。
(5)舍去代表直流成分的D0,取D1,D2,…,DK作為MFCC參數(shù)。此處K=12。
3.3 特定人語(yǔ)音識(shí)別算法
在孤立詞語(yǔ)音識(shí)別中,最為簡(jiǎn)單有效的方法是采用DTW動(dòng)態(tài)時(shí)間規(guī)整算法,設(shè)參考模板特征矢量序列為A={a1,a2,…,aj),輸入語(yǔ)音特征矢量序列為B={b1,b2,…,bk),j≠k。DTW算法就是要尋找一個(gè)最佳的時(shí)間規(guī)整函數(shù),使得語(yǔ)音輸入B的時(shí)間軸k映射到參考模板A的時(shí)間軸j上總的累計(jì)失真最小。
將己經(jīng)存入模板庫(kù)的各個(gè)詞條稱為參考模板,一個(gè)參考模板可以表示為{R(1),R(2),…,R(M)},m為訓(xùn)練語(yǔ)音幀的時(shí)序標(biāo)號(hào),m=1為起點(diǎn)語(yǔ)音幀,m=M為終點(diǎn)語(yǔ)音幀,因此M為該模式包含的語(yǔ)音幀總數(shù),R(m)為第m幀語(yǔ)音的特征矢量。所要識(shí)別的一個(gè)輸入詞條語(yǔ)音稱為參考模板,可表示為{T(1),T(2),…,T(N)),n為測(cè)試語(yǔ)音幀標(biāo)號(hào),模板中共包含N幀音,T(n)為第n幀音的特征矢量。
為了比較它們的相似度,可以計(jì)算,它們之間的失真D[T,R],失真越小相似度越高。為了計(jì)算這一失真,應(yīng)從T和R中各個(gè)對(duì)應(yīng)幀之間的失真算起。將各個(gè)對(duì)應(yīng)幀之間的失真累計(jì)起來(lái)就可以得到兩模式間的總失真。很容易想到的辦法是當(dāng)兩模式長(zhǎng)度相等時(shí),直接以相等的幀號(hào)相匹配后累加計(jì)算總失真,而當(dāng)兩個(gè)模式長(zhǎng)度不等時(shí)則利用線性擴(kuò)張或線性壓縮的方法使兩模式具有相等長(zhǎng)度,隨后進(jìn)行匹配計(jì)算失真度。但由于人類發(fā)音具有隨機(jī)的非線性變化,這種方法效果不可能是最佳的。為了達(dá)到最佳效果,可以采用動(dòng)態(tài)時(shí)間規(guī)整的方法。如圖4所示,橫坐標(biāo)對(duì)應(yīng)“1”這個(gè)字音的一次較短的發(fā)音,經(jīng)過(guò)分幀和特征矢量計(jì)算后共得到一個(gè)長(zhǎng)度為43幀的語(yǔ)音序列,而縱坐標(biāo)對(duì)應(yīng)“1”這個(gè)字音的一次較長(zhǎng)的發(fā)音,該語(yǔ)音特征序列共有56幀。為了找到兩個(gè)序列的最佳匹配路徑,現(xiàn)把測(cè)試模式的各個(gè)幀號(hào)n=1~N(圖4中N=43)在一個(gè)二維直角坐標(biāo)系中的橫軸上標(biāo)出,把參考模式的各幀號(hào)m=1~M(圖4中M=56)在縱軸上標(biāo)出。
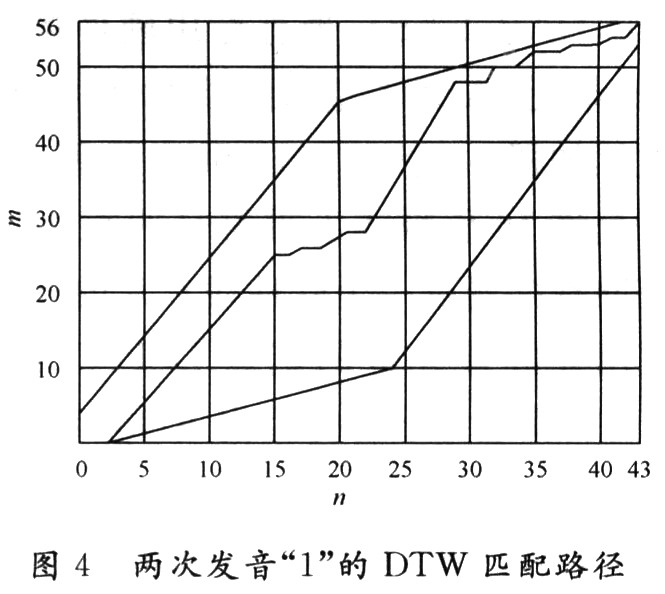
通過(guò)這些表示幀號(hào)的整數(shù)坐標(biāo)畫一些縱橫線即可形成一個(gè)網(wǎng)格,網(wǎng)格中何一個(gè)節(jié)點(diǎn)(n,m)表示測(cè)試模式中的某一幀和參考模式中的某一幀的交匯點(diǎn)。動(dòng)態(tài)時(shí)間規(guī)整算法可以歸結(jié)為尋找一條通過(guò)此網(wǎng)格中若干交叉點(diǎn)的路徑,路徑通過(guò)的交叉點(diǎn)即為參考模式和測(cè)試模式中進(jìn)行失真計(jì)算的幀號(hào)。路徑不是隨意選擇的,首先任何一種語(yǔ)音的發(fā)音快慢可能有變化,但是各部分的先后順序不可能改變,因此所選的路徑必定從左下角出發(fā),在右上角結(jié)束。其次為了防止漫無(wú)目的的搜索,可以刪去那些向n軸方向或者m軸方向過(guò)分傾斜的路徑(例如,過(guò)分向n軸傾斜意味著R(m)壓縮很大而T(n)擴(kuò)張很大,而實(shí)際語(yǔ)音中這種壓、擴(kuò)總是有限的)。為了引入這個(gè)限制,可以對(duì)路徑中各通過(guò)點(diǎn)的路徑平均斜率的最大值和最小值予以限制。通常最大斜率定為2,最小平均斜率定為1/2。路徑的出發(fā)點(diǎn)可以選擇(n,m)=(1,1)點(diǎn),也可以選擇(n,m)=(1,2)或(1,3)或(2,1)或(3,1)…點(diǎn)出發(fā)。前者稱為固定起點(diǎn),后者稱為松弛起點(diǎn)。同樣,路徑可在(n,m)=(N,M)點(diǎn)結(jié)束,也可以在(n,m)=(N,M-1)或(N,M-2)或(N-1,M)或(N-2,M)…點(diǎn)結(jié)束。前者稱為固定終點(diǎn),后者稱為松弛終點(diǎn)。
使用DTW算法為核心直接構(gòu)造識(shí)別系統(tǒng)十分簡(jiǎn)單,首先通過(guò)訓(xùn)練得到詞匯表中各參考語(yǔ)音的特征序列,直接將這些序列存儲(chǔ)為模板。在進(jìn)行識(shí)別時(shí),將待識(shí)語(yǔ)音的特征序列依次與各參考語(yǔ)音特征序列進(jìn)行DTW匹配,最后得到的總失真度最小且小于識(shí)別閾值的就認(rèn)為是識(shí)別結(jié)果。該方法最顯著的優(yōu)點(diǎn)是識(shí)別率極高,大大超過(guò)目前多數(shù)的HMM語(yǔ)音識(shí)別系統(tǒng)和VQ語(yǔ)音識(shí)別系統(tǒng)。但其最明顯的缺點(diǎn)是由于需要對(duì)大量路徑及這些路徑中的所有節(jié)點(diǎn)進(jìn)行匹配計(jì)算,導(dǎo)致計(jì)算量極大,隨著詞匯量的增大其識(shí)別過(guò)程甚至將達(dá)到難以接受的程度,因此無(wú)法直接應(yīng)用于大、中詞匯量識(shí)別系統(tǒng)。
4 結(jié) 語(yǔ)
以本系統(tǒng)為基礎(chǔ)開發(fā)了一種語(yǔ)音撥號(hào)系統(tǒng),經(jīng)過(guò)大量實(shí)驗(yàn)表明,該系統(tǒng)電路運(yùn)行穩(wěn)定,且識(shí)別率可以達(dá)到90%。系統(tǒng)成本低,稍加改進(jìn)就可把該語(yǔ)音識(shí)別模塊移植應(yīng)用到各種系統(tǒng)設(shè)備中。