
??? 摘 要:? 提出了一種基于修正的M距離輻射源識(shí)別的新方法。該方法對(duì)各特征參數(shù)" title="特征參數(shù)">特征參數(shù)作加權(quán)值" title="權(quán)值">權(quán)值處理,得到一種新的相似性度量" title="相似性度量">相似性度量標(biāo)準(zhǔn),大大提高了識(shí)別的準(zhǔn)確性。通過(guò)計(jì)算機(jī)仿真,驗(yàn)證了該方法的合理性與有效性。
??? 關(guān)鍵詞:? M距離? 輻射源? 識(shí)別? 數(shù)據(jù)庫(kù)
?
??? 現(xiàn)代戰(zhàn)場(chǎng)電磁環(huán)境日益密集、復(fù)雜,如何快速、準(zhǔn)確地對(duì)輻射源進(jìn)行識(shí)別已成為電磁斗爭(zhēng)領(lǐng)域的一項(xiàng)緊迫任務(wù)。一般來(lái)說(shuō),無(wú)源探測(cè)系統(tǒng)通過(guò)對(duì)輻射源輻射信號(hào)的處理,得到反映輻射源特征的特征量,由這些特征量根據(jù)一定的算法完成對(duì)輻射源的識(shí)別。這里提到的識(shí)別主要是指對(duì)輻射源的類型作出判斷,若能預(yù)先知道輻射源與載體之間的搭配關(guān)系,則可進(jìn)一步實(shí)現(xiàn)對(duì)輻射源載體的識(shí)別[1]。目前,對(duì)輻射源識(shí)別方法的研究很多,包括人工識(shí)別方法、傳統(tǒng)的數(shù)據(jù)處理識(shí)別" title="處理識(shí)別">處理識(shí)別方法、智能化識(shí)別方法等[3] [4]。人工識(shí)別方法是運(yùn)用人的知識(shí)、經(jīng)驗(yàn),進(jìn)行分析和推理,作出判斷,不能適應(yīng)復(fù)雜的電磁環(huán)境。傳統(tǒng)的數(shù)據(jù)處理識(shí)別是利用計(jì)算機(jī)技術(shù)、數(shù)字技術(shù)進(jìn)行識(shí)別(如數(shù)據(jù)庫(kù)查詢識(shí)別、統(tǒng)計(jì)模式識(shí)別等)。這類識(shí)別方法在待識(shí)別雷達(dá)信號(hào)數(shù)據(jù)不全或新出現(xiàn)信號(hào)時(shí),識(shí)別結(jié)果難盡人意。智能化識(shí)別方法一般比較復(fù)雜,難以實(shí)現(xiàn)。本文從統(tǒng)計(jì)學(xué)理論出發(fā),提出了一種基于修正的M距離的輻射源識(shí)別法,對(duì)輻射源識(shí)別問(wèn)題進(jìn)行了一些有意義的研究。
1 問(wèn)題描述
??? 對(duì)于現(xiàn)有的數(shù)據(jù)庫(kù)或知識(shí)庫(kù),輻射源個(gè)體識(shí)別過(guò)程就是將偵察所得信號(hào)與輻射源數(shù)據(jù)庫(kù)中的已知信號(hào)相比較,根據(jù)某一判決規(guī)則,使按該規(guī)則對(duì)被識(shí)別對(duì)象進(jìn)行識(shí)別所造成的錯(cuò)誤識(shí)別率最小或引起的損失最小,從而確定該信號(hào)的類屬。簡(jiǎn)單地說(shuō)就是一個(gè)分類問(wèn)題[2]。其判斷的依據(jù)主要是看兩信號(hào)的相似性程度,這涉及到相似性度量標(biāo)準(zhǔn)的問(wèn)題。為了有效地實(shí)現(xiàn)分類識(shí)別,需對(duì)原始偵察數(shù)據(jù)進(jìn)行處理,得到最能反映分類本質(zhì)的特征。一般把原始數(shù)據(jù)構(gòu)成的空間叫測(cè)量空間,把分類識(shí)別賴以進(jìn)行的空間叫做特征空間。如果用一組特征參數(shù)描述輻射源信號(hào),由這組特征參數(shù)所構(gòu)成的向量即為特征空間中的一個(gè)點(diǎn),此時(shí),點(diǎn)間的距離函數(shù)可以作為相似性度量的一個(gè)標(biāo)準(zhǔn)。這樣,在實(shí)際過(guò)程中可以依據(jù)距離的大小作為模式分類的依據(jù)。現(xiàn)在的問(wèn)題就歸結(jié)為選擇什么樣的距離作為相識(shí)性度量的標(biāo)準(zhǔn),從而實(shí)現(xiàn)識(shí)別、分類。
??? 在輻射源識(shí)別中,常采用M距離作為相似性度量的標(biāo)準(zhǔn)。M距離又稱為馬氏距離,這里的M代表英文Maharanobis。在數(shù)理統(tǒng)計(jì)中,稱常數(shù)
??? 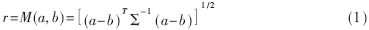
r為a到b的M距離。其中a、b為m維列向量。下面以雷達(dá)為例,討論輻射源識(shí)別中M距離的應(yīng)用。
??? 對(duì)于雷達(dá)這樣的多特征對(duì)象,采用多元正態(tài)分布的概率模型,其概率密度函數(shù)定義為:
??? 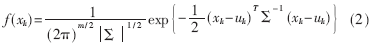
??? 式(2)中,xk=[xk1,xk2,…,xkm]T,xki,i=1,2,…,m是表征第k類雷達(dá)信號(hào)的一組特征參數(shù),它們對(duì)信號(hào)的識(shí)別起關(guān)鍵作用。例如xk1取載頻f,xk2取重頻間隔PRI,xk3取脈寬PW,xk4取天線掃描周期Ta等。這里,uk=[uk1,uk2,…,ukm]T為xk的m維均值向量, Σ為xk的m×m維協(xié)方差矩陣,即Σ=E{(xk-uk)(xk-uk)T}。由M距離的定義知道,對(duì)于特征空間的兩點(diǎn)xk和uk來(lái)說(shuō),M(xk,uk)表示空間上任意一點(diǎn)到某一考慮該類特征分布中心的距離,具體表示為[2]:
??? 
??? 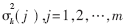 為特征矢量xk的每一個(gè)分量的方差,對(duì)于具體的偵察設(shè)備來(lái)說(shuō)即為參數(shù)容差值。
為特征矢量xk的每一個(gè)分量的方差,對(duì)于具體的偵察設(shè)備來(lái)說(shuō)即為參數(shù)容差值。
??? 事實(shí)上,M距離相對(duì)其他距離如歐氏距離而言具有以下優(yōu)點(diǎn):首先,M距離是歐幾里德空間中非均勻分布的歸一化距離,不用考慮各特征參數(shù)的量綱;其次,M距離是根據(jù)整個(gè)空間上的特征分布情況來(lái)作為判別依據(jù)的,排除了模式樣本之間的相關(guān)性影響;同時(shí),給出的結(jié)果是一個(gè)數(shù)值,判斷標(biāo)準(zhǔn)簡(jiǎn)單易行,也為更高一級(jí)的分析提供了較可靠的依據(jù)。但是,M距離的定義中并沒(méi)有考慮每一個(gè)特征參數(shù)在識(shí)別過(guò)程中所起作用即權(quán)重的大小。從式(4)可以看出,各特征參數(shù)在識(shí)別中是作等權(quán)值處理的,不符合實(shí)際情況。因此,采用修正的M距離作為相似性度量標(biāo)準(zhǔn)。定義新的距離函數(shù)如下:
??? 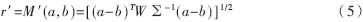
??? 其中W為權(quán)系數(shù)矩陣,表示如下:
??? 
??? 這樣,得到了一個(gè)新的相似性度量標(biāo)準(zhǔn)。
2 權(quán)系數(shù)的設(shè)置
??? 一般來(lái)說(shuō),對(duì)輻射源目標(biāo)特征參數(shù)之間重要性沒(méi)有任何先驗(yàn)信息,采用等加權(quán)處理方法,如式(4)所示。它是修正的M距離的一個(gè)特例。如果是具有一定先驗(yàn)信息的情況,此時(shí)權(quán)值可根據(jù)先驗(yàn)信息確定。但在實(shí)際工作中,先驗(yàn)信息很難得到,此時(shí)可以采用如下的熵值分析法確定權(quán)系數(shù)。
2.1 熵的定義[2]
??? 熵在信息論中是一個(gè)非常重要的概念,它是不確定性的一種度量。設(shè)集合X中各事件出現(xiàn)的概率用n維概率矢量 則熵定義為:
則熵定義為:
??? 
??? 因此,熵H可以看作是n維概率矢量p=(p1,p2,…,pn)的函數(shù),稱為熵函數(shù)。
??? 熵函數(shù)H(p)具有以下重要性質(zhì):
??? (1)對(duì)稱性:概率矢量p=(p1,p2,…,pn)各分量p1,p2,…,pn的次序任意改變時(shí),熵函數(shù)H(p)的值不變,即熵值只與集合X總體上的統(tǒng)計(jì)特征有關(guān)。
??? (2)非負(fù)性:熵函數(shù)是一個(gè)非負(fù)量,即:
??? H(p1,p2,…,pn)≥0?????????????????????????????????????? (9)
??? (3) 確定性:集合X中只要有一個(gè)必然事件,其熵值必為零。
??? (4)極值性:集合X中各事件以等概率出現(xiàn)時(shí),其熵值為最大" title="最大">最大,即有:
??? 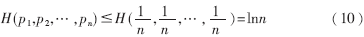
??? 由熵函數(shù)的定義可知,熵值越小,不同類別的分離程度越大。從概率論的角度來(lái)看,某一特征的熵值越小則包含的確定性信息越多;反映在分類識(shí)別中就是它對(duì)識(shí)別結(jié)果的影響較大,這也意味著設(shè)置該特征參數(shù)所對(duì)應(yīng)的權(quán)值要大一些,以保證識(shí)別的精度和準(zhǔn)確性。
2.2? 熵值分析法設(shè)置權(quán)重
??? 對(duì)于有k類模式的雷達(dá)輻射源識(shí)別問(wèn)題,已提取的特征參數(shù)共有m個(gè),如式(2)所示。對(duì)每一個(gè)特征參數(shù)Fj; j=1,2,…,m,將其對(duì)應(yīng)的分布區(qū)間分為相等的N段,記為rk(j),k=1,2,…,N。注意,這里的分布區(qū)間是指k類模式的最大可能的參數(shù)分布區(qū)間。滿足Fj∈rk(j)的樣本屬于i類的概率為pki(j):
??? 
??? 式(11)中,Nk(j)為有Fj∈rk(j)的樣本數(shù),Nki(j)為Nk(j)中屬于第i類的樣本數(shù),于是有:
??? 
??? 根據(jù)熵函數(shù)的性質(zhì),熵值H(Fj)越小,各類模式在特征Fj上的類間分離性越大,則特征Fj對(duì)分類的貢獻(xiàn)越大,即在識(shí)別過(guò)程中的權(quán)重越大。如果有Fj∈rk(j)的所有樣本都屬于同一類,則有H(Fj)=0。在這種情況下,用這一特征Fj就可以實(shí)現(xiàn)分類識(shí)別。在得到各個(gè)特征參數(shù)的H(Fj)后,就可以定義相應(yīng)的歸一化權(quán)值如下:
??? 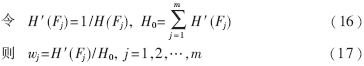
??? 需要注意的是,由于識(shí)別過(guò)程實(shí)際上是將偵察所得信號(hào)與輻射源數(shù)據(jù)庫(kù)中的已知信號(hào)相比較,因而可以采用輻射源數(shù)據(jù)庫(kù)中的數(shù)據(jù)作為熵值分析法的樣本。這實(shí)際上是充分利用已有的知識(shí)數(shù)據(jù)庫(kù)中的分類信息確定各特征參數(shù)在識(shí)別中的權(quán)值,以期得到較好的識(shí)別效果。
??? 獲得權(quán)系數(shù)后,就可根據(jù)相似性度量的大小判斷一個(gè)特征向量應(yīng)屬于哪一類。若已知待識(shí)別信號(hào)為s,顯然滿足M′(s,ui)最小的類ωi與樣本有著最大的相似度。即:
??? 
??? 其中i,j=1,2,…,K,K為類的總數(shù),ωi表示第i類。
3 仿真實(shí)驗(yàn)及結(jié)果分析
??? 在該實(shí)驗(yàn)中以雷達(dá)知識(shí)數(shù)據(jù)庫(kù)中11類雷達(dá)輻射源的識(shí)別問(wèn)題作為研究對(duì)象。所采用的描述雷達(dá)類型的特征參數(shù)為:載頻、重頻間隔、脈寬和天線掃描周期。分段數(shù)N=100,經(jīng)計(jì)算得到的各個(gè)參數(shù)在識(shí)別中的權(quán)重如表1所示。
?

??? 下面考慮對(duì)某個(gè)已知類型的雷達(dá)的一批偵察數(shù)據(jù)進(jìn)行處理,計(jì)算對(duì)該目標(biāo)的識(shí)別率,得到的識(shí)別率與信噪比的關(guān)系曲線如圖1所示。
?

??? 由圖1可以看出,為得到較高的識(shí)別率,要求信噪比達(dá)到5dB左右。進(jìn)一步的研究表明該方法對(duì)未知的新類型雷達(dá)目標(biāo)具有較好的判斷能力;同時(shí),分段數(shù)N的大小及由此決定的分段區(qū)間對(duì)權(quán)值的確定有一定的影響。當(dāng)N足夠大時(shí),權(quán)系數(shù)的變化趨向穩(wěn)定,最終得到的極限值就可以作為確定權(quán)系數(shù)的依據(jù)。
??? 本方法在實(shí)際應(yīng)用中還要注意特征參數(shù)的選取和識(shí)別權(quán)系數(shù)的確定,特別是對(duì)先驗(yàn)信息的利用,以期得到更佳的識(shí)別效果。
參考文獻(xiàn)
1 黃知濤.基于雙門(mén)限檢測(cè)的輻射源識(shí)別方法.系統(tǒng)工程與電子技術(shù),2001;11(23)
2 李世中.熵值分析法在特征提取中的應(yīng)用研究.華北工學(xué)院學(xué)報(bào),1999;3(20)
3 沈清,湯 霖.模式識(shí)別導(dǎo)論.長(zhǎng)沙:國(guó)防科技大學(xué)出版社,1997
4 劉同明.目標(biāo)類型識(shí)別方法研究.計(jì)算機(jī)應(yīng)用研究.1999;(7)